哈工大2022机器学习实验二:逻辑回归
逻辑回归,又意译为对率回归,虽然它的名字中带“回归”,但它是一个分类模型。它的基本思想是直接估计条件概率P(Y|X)的表达式,即给定样本X=x,其属于类别Y的概率。
机器学习模型的集成方法总结:Bagging, Boosting, Stacking, Voting, Blending
集成学习是一种元方法,通过组合多个机器学习模型来产生一个优化的模型,从而提高模型的性能。集成学习可以很容易地减少过拟合,避免模型在训练时表现更好,而在测试时不能产生良好的结果。
Python中的层次聚类,详细讲解
机器学习中的层次聚类,python实现
“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享
“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享。
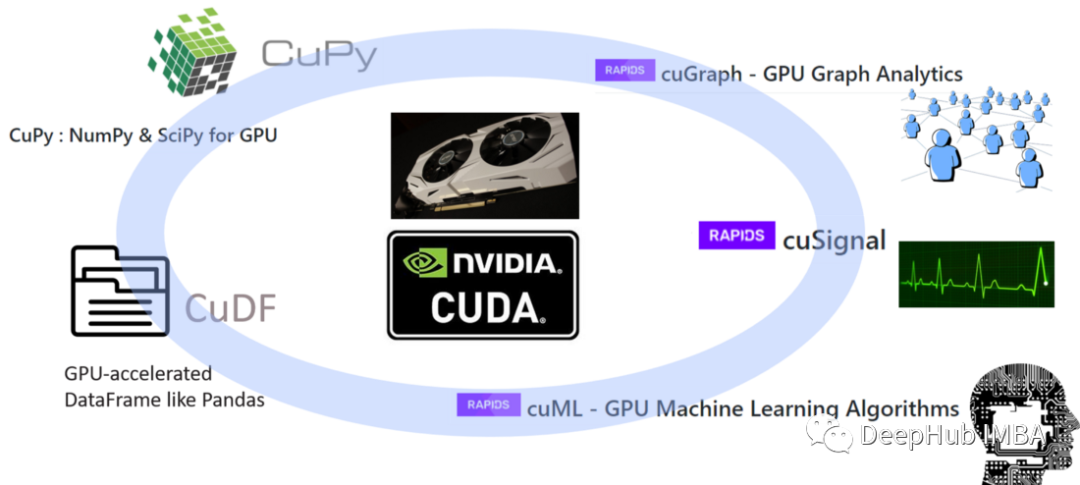
在gpu上运行Pandas和sklearn
Pandas和sklearn这两个是我们最常用的基本库,Rapids将Pandas和sklearn的功能完整的平移到了GPU之上

超长时间序列数据可视化的6个技巧
本文展示了6种用于绘制长时间序列数据的可视化方法,通过使用交互函数和改变视角,我可以使结果变得友好并且能够帮助我们更加关注重要的数据点。
Python实现基于机器学习的手写数字识别系统
安装好的OpenCV中有自带的分类器,但是很不幸的是自带的分类器仅有关于人脸识别方向的,如果是做人脸识别方向的研究使用该分类器将会非常方便。本章将介绍如何使用计算机视觉库OpenCV调用电脑摄像头、找到帧画面中的数字并对数字进行识别前的处理,最后调用训练好的手写数字模型将识别结果在原帧画面中显示出来
机器学习:详解半朴素贝叶斯分类AODE原理(附Python实现)
朴素贝叶斯中的属性独立性假设在实际上很难成立,因此引入半朴素贝叶斯分类器,其核心思想是:适当考虑部分属性的相互依赖。本文介绍典型的半朴素贝叶斯分类AODE原理及Python实现

生成模型VAE、GAN和基于流的模型详细对比
生成算法有很多,但属于深度生成模型类别的最流行的模型是变分自动编码器(VAE)、gan和基于流的模型。
嵌入式软件编程模式
这里讨论的编程模式主要针对没有操作系统的嵌入式软件运行环境,在这种情况下,CPU的全部算力可以分配到和应用相关的计算,不需要额外执行IO资源状态、内存清理、调度等软件操作系统的管理任务,因此运行效率和内存使用效率会更高,但付出的代价是需要手动管理任务并发、IO状态检查、资源共享等,对开发者有更高的要
《计算机视觉基础知识蓝皮书》第2篇 深度学习基础
深度学习基础知识精讲
【python-Unet】计算机视觉~舌象舌头图片分割~机器学习
舌象数据集包含舌象原图以及分割完成的二元图,共979*2张,示例图片如下:U-Net是一个优秀的语义分割模型,在中e诊中U-Net共三部分,分别是主干特征提取部分、加强特征提取部分、预测部分。利用主干特征提取部分获得5个初步有效的特征层,之后通过加强特征提取部分对上述获取到的5个有效特征层进行上采样

Nature子刊:一个从大脑结构中识别阿尔茨海默病维度表征的深度学习框架
脑部疾病的异质性是精准诊断/预后的一个挑战。作者描述并验证了一种名为Smile-GAN(SeMI-supervised cLustEring-Generative Adversarial Network),的半监督深度聚类方法,它研究了与正常大脑结构对比的神经解剖学异质性,从而通过神经影像特征识别疾
【国庆特辑文章】时间序列~动态时间规整(Dynamic Time Wraping)
解决的问题:测量两端时间序列的相似性

【XGBoost】第 7 章:使用 XGBoost 发现系外行星
在本章中,您将穿越星星,尝试以为向导发现系外行星。本章的原因是双重的。首先是使用 XGBoost 在自上而下的研究中获得实践非常重要,因为出于所有实际目的,这就是您通常使用 XGBoost 所做的事情。尽管您可能无法自己发现带有 XGBoost 的系外行星,但您在此处实施的策略(包括选择正确的评分指
softmax回归与交叉熵损失
回归与分类是机器学习中的两个主要问题,二者有着紧密的联系,但又有所不同。在一个预测任务中,回归问题解决的是多少的问题,如房价预测问题,而分类问题用来解决是什么的问题,如猫狗分类问题。分类问题又以回归问题为基础,给定一个样本特征,模型针对每一个分类都返回一个概率,于是可以认为概率最大的类别就是模型给出

贝叶斯回归:使用 PyMC3 实现贝叶斯回归
在这篇文章中,我们将介绍如何使用PyMC3包实现贝叶斯线性回归,并快速介绍它与普通线性回归的区别。
机器学习之手写决策树以及sklearn中的决策树及其可视化
(2)如果属性划分次数达到上限,即属性划分完了,或者是样本中在此类属性取值都一样,可以认为全部划分仍然存在不同类的样本,那么这个节点就标记为类别数占较多的叶节点。划分选择还是比较重要的,因为不同的划分选择会建出不同的决策树。划分选择的指标就是希望叶节点的数据尽可能都是属于同一类,即节点的“纯度”越来



