
【机器学习】网络爬虫详解

活动地址:CSDN21天学习挑战赛
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:机器学习
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
前言
什么是网络爬虫?
编写程序从网络中自动获取数据的过程叫作数据爬取,也叫作网络爬虫。网络爬虫一般步骤为:获取爬取页的url,获取页面内容、解析页面、获取所需数据,重复上述过程至爬取结束。
一、明星图片爬取
明星图片爬取基于百度搜索的返回结果进行,在百度搜索“中国艺人”,解析返回页面展示的艺人图片链接并保持。
(一)、定义爬取指定url页面的函数
- 导入相关包:
import requests
import json
import os
- 直接使用程序爬取网络数据会被网站识别出来,然后封禁该IP,导致数据爬取中断,所以我们需要首先将程序访问页面伪装成浏览器访问页面
User-Agent:定义一个真实浏览器的代理名称,表明自己的身份(是哪种浏览器),本demo为谷歌浏览器
Accept:告诉WEB服务器自己接受什么介质类型,*/* 表示任何类型
Referer:浏览器向WEB服务器表明自己是从哪个网页URL获得点击当前请求中的网址/URL
Connection:表示是否需要持久连接
Accept-Language:浏览器申明自己接收的语言
Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)
defgetPicinfo(url):
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36","Accept":"*/*","Referer":"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&fenlei=256&rsv_pq=cf6f24c500067b9f&rsv_t=c2e724FZlGF9fJYeo9ZV1I0edbhV0Z04aYY%2Fn6U7qaUoH%2B0WbUiKdOr8JO4&rqlang=cn&rsv_dl=ib&rsv_enter=1&rsv_sug3=15&rsv_sug1=6&rsv_sug7=101","Host":"sp0.baidu.com","Connection":"keep-alive","Accept-Language":"en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6","Accept-Encoding":"gzip, deflate"}# 根据url,使用get()方法获取页面内容,返回相应
response = requests.get(url,headers)# 成功访问了页面if response.status_code ==200:return response.text
# 没有成功访问页面,返回NonereturnNone
(二)、爬取图片
使用上述定义好的函数,进行指定url页面的爬取,然后解析返回的页面源码,获取其中的图片链接,并保存图片:
#图片存放地址
Download_dir='picture'if os.path.exists(Download_dir)==False:
os.mkdir(Download_dir)
pn_num=1# 爬取多少页
rn_num=10# 每页多少个图片for k inrange(pn_num):# for循环,每次爬取一页
url="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28266&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="+str(k)+"&rn="+str(rn_num)+"&_=1613785351574"
res = getPicinfo(url)# 调用函数,获取每一页内容
json_str=json.loads(res)# 将获取的文本格式转化为字典格式
figs=json_str['data'][0]['result']for i in figs:# for循环读取每一张图片的名字
name=i['ename']
img_url=i['pic_4n_78']# img_url:图片地址
img_res=requests.get(img_url)# 读取图片所在页面内容if img_res.status_code==200:
ext_str_splits=img_res.headers['Content-Type'].split('/')
ext=ext_str_splits[-1]# 索引-1指向列表倒数第一个元素
fname=name+"."+ext
# 保存图片open(os.path.join(Download_dir,fname),'wb').write(img_res.content)print(name,img_url,"saved")
爬取内容部分如图1-1所示:
二、股票行情爬取与分析
首先爬取一个股票名称列表,再获取列表里每支股票的信息。
(一)、爬取股票列表信息
代码如下:
#coding=utf-8'''
Created on 2021年02月20日
@author: zhongshan
'''#http://quote.eastmoney.com/center/gridlist.html#爬取该页面股票信息import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import json
import csv
defgetHtml(url):
r = requests.get(url,headers={'User-Agent': UserAgent().random,})
r.encoding = r.apparent_encoding
return r.text
#num为爬取多少条记录,可手动设置
num =20#该地址为页面实际获取数据的接口地址
stockUrl='http://99.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408733409809437476_1623137764048&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1623137764167:formatted'if __name__ =='__main__':
responseText = getHtml(stockUrl)
jsonText = responseText.split("(")[1].split(")")[0];
resJson = json.loads(jsonText)
datas = resJson["data"]["diff"]
datalist =[]for data in datas:# if (str().startswith('6') or str(data["f12"]).startswith('3') or str(data["f12"]).startswith('0')):
row =[data["f12"],data["f14"]]
datalist.append(row)print(datalist)
f =open('stock.csv','w+',encoding='utf-8',newline="")
writer = csv.writer(f)
writer.writerow(('代码','名称'))for data in datalist:
writer.writerow((data[0]+"\t",data[1]+"\t"))
f.close()
输出结果如图2-1所示:

(二)、股票数据获取
在获取股票代码及名称列表之后,逐个下载股票数据,根据观察,每支股票的历史数据由四部分组成:头url,上市地(深市,沪市)、股票代码、尾url,只需要组合好上述url,即可获得csv格式的数据,并下载,如下:
import csv
import urllib.request as r
import threading
#读取之前获取的个股csv丢入到一个列表中defgetStockList():
stockList =[]
f =open('stock.csv','r',encoding='utf-8')
f.seek(0)
reader = csv.reader(f)for item in reader:
stockList.append(item)
f.close()return stockList
defdownloadFile(url,filepath):# print(filepath)try:
r.urlretrieve(url,filepath)except Exception as e:print(e)print(filepath,"is downloaded")pass#设置信号量,控制线程并发数
sem = threading.Semaphore(1)defdownloadFileSem(url,filepath):with sem:
downloadFile(url,filepath)
urlStart ='http://quotes.money.163.com/service/chddata.html?code='
urlEnd ='&end=20210221&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;VOTURNOVER;VATURNOVER'if __name__ =='__main__':
stockList = getStockList()
stockList.pop(0)print(stockList)for s in stockList:
scode =str(s[0].split("\t")[0])#0:沪市;1:深市
url = urlStart +("0"if scode.startswith('6')else"1")+ scode + urlEnd
print(url)
filepath =(str(s[1].split("\t")[0])+"_"+scode)+".csv"
threading.Thread(target=downloadFileSem,args=(url,filepath)).start()
下载文件部分列表如图2-2所示:

(三)、股票数据分析
现在,我们对股票数据做一些简单的分析,比如股票的最高价、最低价随时间的变化,股票的涨跌幅/涨跌额随时间的变化,以及当天的成交量与前一天的涨跌幅有何关系等。
上述分析可以使用作图的方式进行直观展示。
- 定义加载数据的功能函数:
import pandas as pd
import matplotlib.pyplot as plt
import csv
# 设置显示中文
plt.rcParams['font.sans-serif']=['simhei']# 指定默认字体
plt.rcParams['axes.unicode_minus']=False# 用来显示负号
plt.rcParams['figure.dpi']=100# 每英寸点数
files =[]# ['日期' '股票代码' '名称' '收盘价' '最高价' '最低价' '开盘价' '前收盘' '涨跌额' '涨跌幅' '成交量' '成交金额']defread_file(file_name):
data = pd.read_csv(file_name,encoding='gbk')
col_name = data.columns.values
return data, col_name
defget_files_path():
stock_list=getStockList()
paths =[]for stock in stock_list[1:]:
p = stock[1].strip()+"_"+stock[0].strip()+".csv"print(p)
data,_ = read_file(p)iflen(data)>1:
files.append(p)print(p)
get_files_path()print(files)
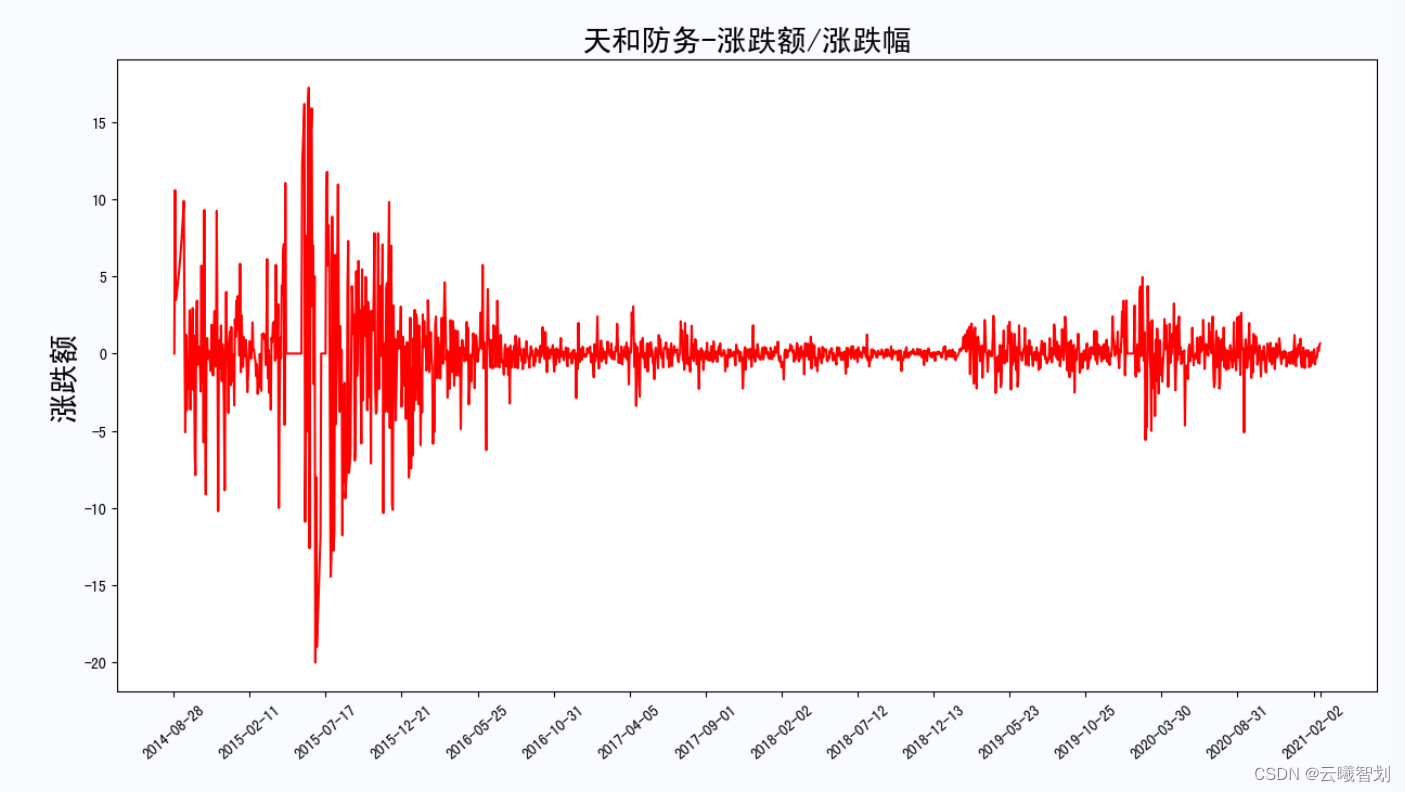
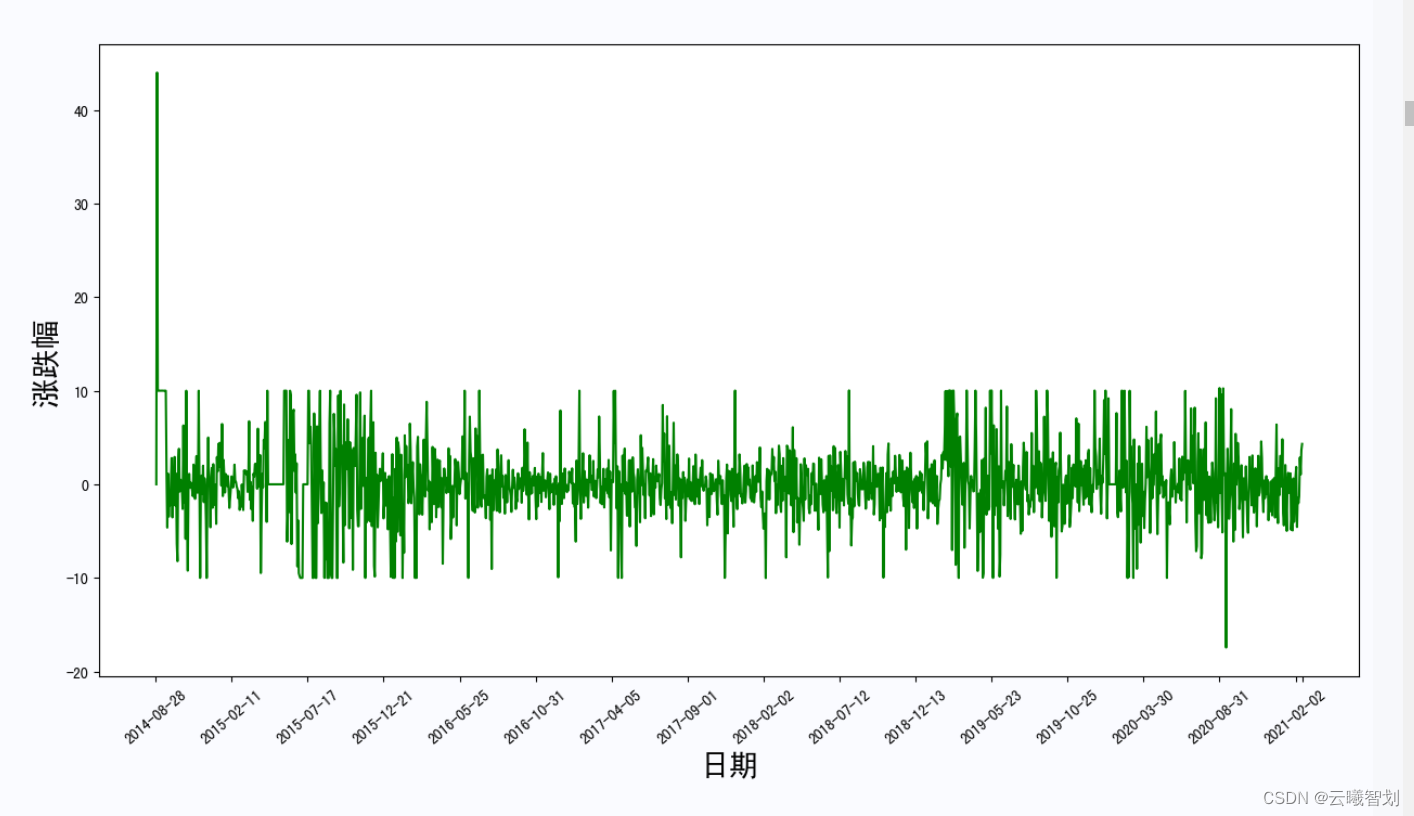
- 定义get_diff(file_name)函数,作该股票的涨跌幅/涨跌额随时间的变化图像,可以将该支股票的波动性观察一段时间。
# 获取股票的涨跌额及涨跌幅度变化曲线# ['日期' '股票代码' '名称' '收盘价' '最高价' '最低价' '开盘价' '前收盘' '涨跌额' '涨跌幅' '成交量' '成交金额']defget_diff(file_name):
data, col_name = read_file(file_name)
index =len(data['日期'])-1
sep = index//15
plt.figure(figsize=(15,17))
x = data['日期'].values.tolist()
x.reverse()# x = x[-index:]
xticks=list(range(0,len(x),sep))
xlabels=[x[i]for i in xticks]
xticks.append(len(x))# xlabels.append(x[-1])
y1 =[float(c)if c!='None'else0for c in data['涨跌额'].values.tolist()]
y2=[float(c)if c!='None'else0for c in data['涨跌幅'].values.tolist()]
y1.reverse()
y2.reverse()# y1 = y1[-index:]# y2 = y2[-index:]
ax1 = plt.subplot(211)
plt.plot(range(1,len(x)+1),y1,c='r')
plt.title('{}-涨跌额/涨跌幅'.format(file_name.split('_')[0]),fontsize=20)
ax1.set_xticks(xticks)
ax1.set_xticklabels(xlabels, rotation=40)# plt.xlabel('日期')
plt.ylabel('涨跌额',fontsize=20)
ax2 = plt.subplot(212)
plt.plot(range(1,len(x)+1),y2,c='g')# plt.title('{}-涨跌幅'.format(file_name.split('_')[0]))
ax2.set_xticks(xticks)
ax2.set_xticklabels(xlabels, rotation=40)
plt.xlabel('日期',fontsize=20)
plt.ylabel('涨跌幅',fontsize=20)
plt.savefig('work/'+file_name.split('.')[0]+'_diff.png')
plt.show()
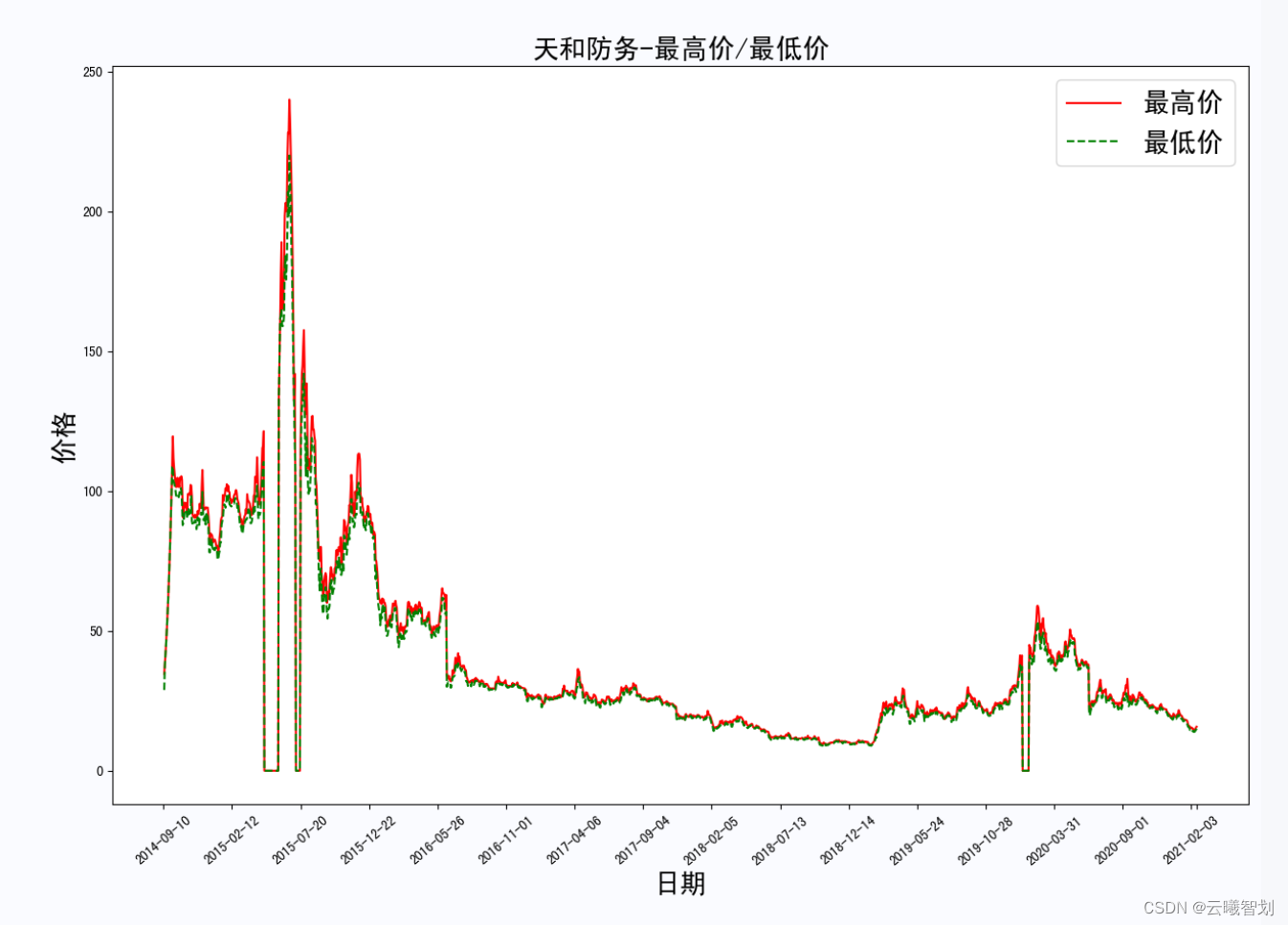
- 定义get_max_min(file_name)函数,做该股票的每日最高价/最低价随时间的变化图像,也可以将该支股票的波动性或者是否增值观察一段时间。
defget_max_min(file_name):
data, col_name = read_file(file_name)
index =len(data['日期'])-1
sep = index//15
plt.figure(figsize=(15,10))
x = data['日期'].values.tolist()
x.reverse()
x = x[-index:]
xticks=list(range(0,len(x),sep))
xlabels=[x[i]for i in xticks]
xticks.append(len(x))# xlabels.append(x[-1])
y1 =[float(c)if c!='None'else0for c in data['最高价'].values.tolist()]
y2=[float(c)if c!='None'else0for c in data['最低价'].values.tolist()]
y1.reverse()
y2.reverse()
y1 = y1[-index:]
y2 = y2[-index:]
ax = plt.subplot(111)
plt.plot(range(1,len(x)+1),y1,c='r',linestyle="-")
plt.plot(range(1,len(x)+1),y2,c='g',linestyle="--")
plt.title('{}-最高价/最低价'.format(file_name.split('_')[0]),fontsize=20)
ax.set_xticks(xticks)
ax.set_xticklabels(xlabels, rotation=40)
plt.xlabel('日期',fontsize=20)
plt.ylabel('价格',fontsize=20)
plt.legend(['最高价','最低价'],fontsize=20)
plt.savefig('work/'+file_name.split('.')[0]+'_minmax.png')
plt.show()
- 定义get_deal(file_name)函数,作该股票的每日成交量/成交金额随时间变化的图像,可以观察一段时间内该支股票的成交量变化,以及是否存在大宗交易:
defget_deal(file_name):
data, col_name = read_file(file_name)
index =len(data['日期'])-1
sep = index//15
plt.figure(figsize=(15,10))
x = data['日期'].values.tolist()
x.reverse()
x = x[-index:]
xticks=list(range(0,len(x),sep))
xlabels=[x[i]for i in xticks]
xticks.append(len(x))# xlabels.append(x[-1])
y1 =[float(c)if c!='None'else0for c in data['成交量'].values.tolist()]
y2=[float(c)if c!='None'else0for c in data['成交金额'].values.tolist()]
y1.reverse()
y2.reverse()
y1 = y1[-index:]
y2 = y2[-index:]
ax = plt.subplot(111)
plt.plot(range(1,len(x)+1),y1,c='b',linestyle="-")
plt.plot(range(1,len(x)+1),y2,c='r',linestyle="--")
plt.title('{}-成交量/成交金额'.format(file_name.split('_')[0]),fontsize=20)
ax.set_xticks(xticks)
ax.set_xticklabels(xlabels, rotation=40)
plt.xlabel('日期',fontsize=20)# plt.ylabel('')
plt.legend(['成交量','成交金额'],fontsize=20)
plt.savefig('work/'+file_name.split('.')[0]+'_deal.png')
plt.show()
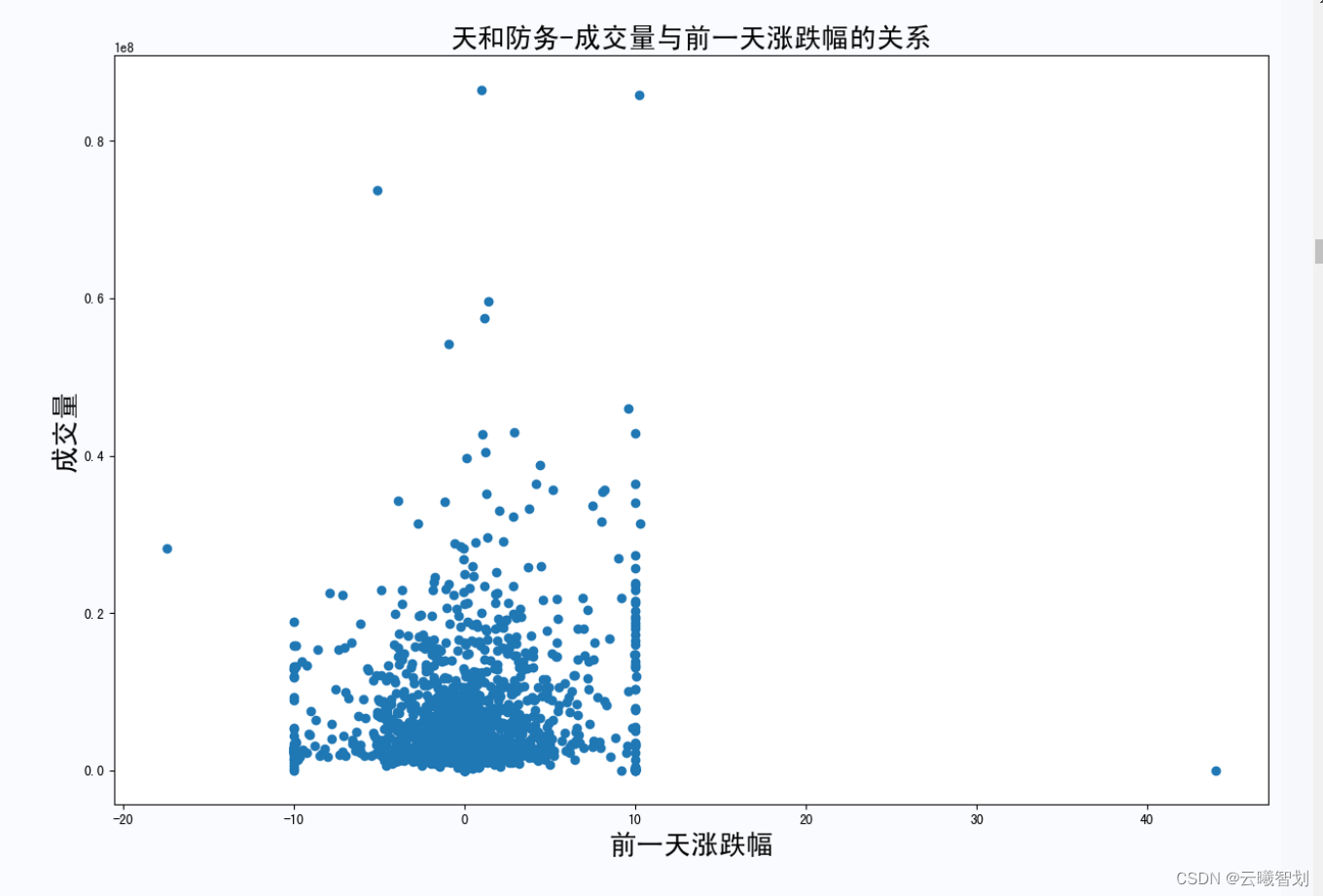
- 定义get_rel(flie_name)函数,做该股票的成交量与前一天涨跌额的关系图像,直观地展示涨跌额对成交量的影响。
defget_rel(file_name):
data, col_name = read_file(file_name)
index =len(data['日期'])-1
sep = index//15
plt.figure(figsize=(15,10))
x = data['日期'].values.tolist()
x.reverse()
x = x[-index:]
xticks=list(range(0,len(x),sep))
xlabels=[x[i]for i in xticks]
xticks.append(len(x))# xlabels.append(x[-1])
y1 =[float(c)if c!='None'else0for c in data['成交量'].values.tolist()]
y2=[float(c)if c!='None'else0for c in data['涨跌幅'].values.tolist()]
y1.reverse()
y2.reverse()
y1 = y1[-index:]
y2 = y2[-index:]
y2 =[0]+ y2[:-1]
ax = plt.subplot(111)
plt.scatter(y2,y1)
plt.title('{}-成交量与前一天涨跌幅的关系'.format(file_name.split('_')[0]),fontsize=20)# ax.set_xticks(xticks)# ax.set_xticklabels(xlabels, rotation=40)
plt.xlabel('前一天涨跌幅',fontsize=20)
plt.ylabel('成交量',fontsize=20)# plt.legend(['成交量','成交金额'],fontsize=20)
plt.savefig('work/'+file_name.split('.')[0]+'_rel.png')
plt.show()# for file in files:# get_diff(file)# for file in files:# get_max_min(file)print(len(files))
- 调用上述分析函数,为每支股票绘制相关的展示图:
forfilein files:
get_max_min(file)
get_deal(file)
get_diff(file)
get_rel(file)
股票的涨跌额及涨跌幅度变化如下图2-3、2-4所示:
股票的最高价/最低价变化如图2-5所示:
股票成交量/成交金额变化如图2-6所示:
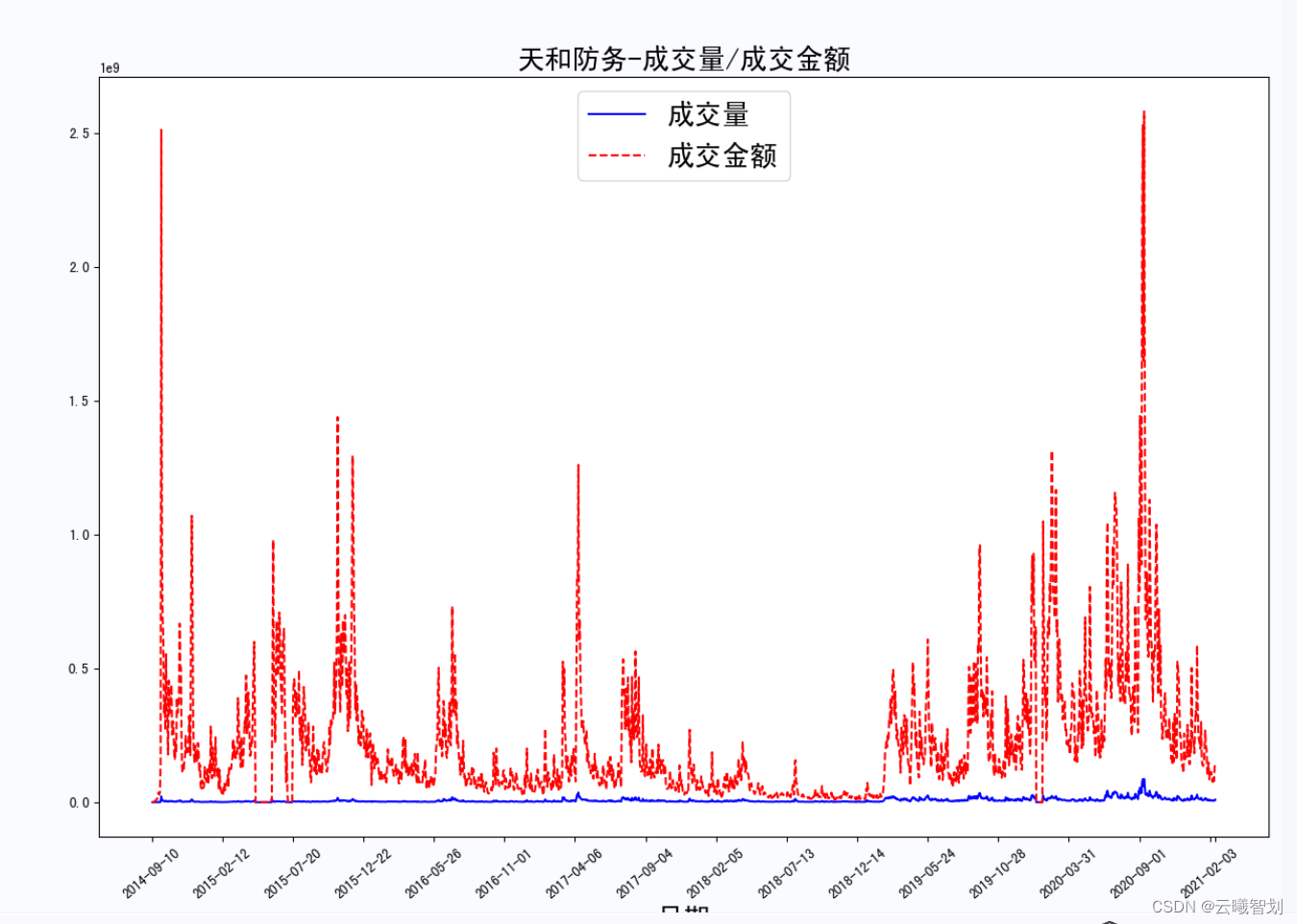
股票的涨跌额与次日成交量关系如下图2-7所示:
三、科比职业生涯数据爬取与分析
本实验从网址http://www.stat-nba.com获取科比的相关数据,主要包括:常规赛、季后赛、全明星赛三种赛事的数据。
(一)、科比职业生涯赛事数据爬取
- 导入相关包
import requests
from bs4 import BeautifulSoup
import csv
import matplotlib.pyplot as plt
import pandas as pd
- 获取url页面内容,并以文本格式返回
defgetKobeList(code):
url ="http://www.stat-nba.com/player/stat_box/195_"+code+".html"
response = requests.get(url)
resKobe = response.text
return resKobe
- 获取Kobe历史数据
#获取kobe历史数据defgetRow(resKobe,code):
soup = BeautifulSoup(resKobe,"html.parser")
table = soup.find_all(id='stat_box_avg')#表头
header =[]if code =="season":
header =["赛季","出场","首发","时间","投篮","命中","出手","三分","命中","出手","罚球","命中","出手","篮板","前场","后场","助攻","抢断","盖帽","失误","犯规","得分","胜","负"]if code =="playoff":
header =["赛季","出场","时间","投篮","命中","出手","三分","命中","出手","罚球","命中","出手","篮板","前场","后场","助攻","抢断","盖帽","失误","犯规","得分","胜","负"]if code =="allstar":
header =["赛季","首发","时间","投篮","命中","出手","三分","命中","出手","罚球","命中","出手","篮板","前场","后场","助攻","抢断","盖帽","失误","犯规","得分"]#数据
rows =[];
rows.append(header)for tr in table[0].find_all("tr",class_="sort"):
row =[]for td in tr.find_all("td"):
rank = td.get("rank")if rank !="LAL"and rank !=None:
row.append(td.get_text())
rows.append(row)return rows
#写入csv文件,rows为数据,dir为写入文件路径defwriteCsv(rows,dir):withopen(dir,'w', encoding='utf-8-sig', newline='')as f:
writer = csv.writer(f)
writer.writerows(rows)#常规赛数据
resKobe = getKobeList("season")
rows = getRow(resKobe,"season")#print(rows)
writeCsv(rows,"season.csv")print("season.csv saved")#季后赛数据
resKobe = getKobeList("playoff")
rows = getRow(resKobe,"playoff")#print(rows)
writeCsv(rows,"playoff.csv")print("playoff.csv saved")#全明星数据
resKobe = getKobeList("allstar")
rows = getRow(resKobe,"allstar")#print(rows)
writeCsv(rows,"star.csv")print("star.csv saved")
(二)、科比职业生涯数据分析
针对不同赛事以及不同时间,绘制科比的职业生涯得分情况,比如,绘制各个赛季科比的篮板数、助攻、得分情况分布,可以在一定程度上反映其在各个赛季的贡献程度。首先定义展示函数show_score(),传入不同赛事的名称,要展示的项,以及绘制线型等:
# 篮板、助攻、得分defshow_score(game_name='season', item='篮板', plot_name='line'):# game_name: season, playoff, star# item: 篮板,助攻,得分# plot_name: line,bar
file_name = game_name+'.csv'
data = pd.read_csv(file_name)
X= data['赛季'].values.tolist()
X.reverse()if item=='all':
Y1 = data['篮板'].values.tolist()
Y2 = data['助攻'].values.tolist()
Y3 = data['得分'].values.tolist()
Y1.reverse()
Y2.reverse()
Y3.reverse()else:
Y = data[item].values.tolist()
Y.reverse()if plot_name=='line':if item=='all':
plt.plot(X,Y1,c='r',linestyle="-.")
plt.plot(X,Y2,c='g',linestyle="--")
plt.plot(X,Y3,c='b',linestyle="-")
legend=['篮板','助攻','得分']else:
plt.plot(X,Y,c='g',linestyle="-")
legend=[item]elif plot_name=='bar':#facecolor:表面的颜色;edgecolor:边框的颜色if item=='all':
fig = plt.figure(figsize=(15,5))
ax1 = plt.subplot(131)
plt.bar(X,Y1,facecolor ='#9999ff',edgecolor ='white')
plt.legend(['篮板'])
plt.title('Kobe职业生涯数据分析:'+game_name)
plt.xticks(rotation=60)
plt.ylabel('篮板')
ax2 = plt.subplot(132)
plt.bar(X,Y2,facecolor ='#999900',edgecolor ='white')
plt.legend(['助攻'])
plt.title('Kobe职业生涯数据分析:'+game_name)
plt.xticks(rotation=60)
plt.ylabel('助攻')
ax3 = plt.subplot(133)
plt.bar(X,Y3,facecolor ='#9988ff',edgecolor ='white')
legend=['得分']else:
plt.bar(X,Y,facecolor ='#9900ff',edgecolor ='white')
legend=[item]else:return
plt.legend(legend)
plt.title('Kobe职业生涯数据分析:'+game_name)
plt.xticks(rotation=60)
plt.xlabel('赛季')if item!='all':
plt.ylabel(item)else:
plt.ylabel('得分')
plt.savefig('work/Kobe职业生涯数据分析_{}_{}.png'.format(game_name,item))
plt.show()# 篮板、助攻、得分
game_name ='season'for game_name in['season','playoff','star']:
show_score(game_name=game_name, item='篮板', plot_name='bar')
show_score(game_name=game_name, item='助攻', plot_name='bar')
show_score(game_name=game_name, item='得分', plot_name='bar')
show_score(game_name=game_name, item='篮板', plot_name='line')
show_score(game_name=game_name, item='助攻', plot_name='line')
show_score(game_name=game_name, item='得分', plot_name='line')
show_score(game_name=game_name, item='all', plot_name='bar')
show_score(game_name=game_name, item='all', plot_name='line')
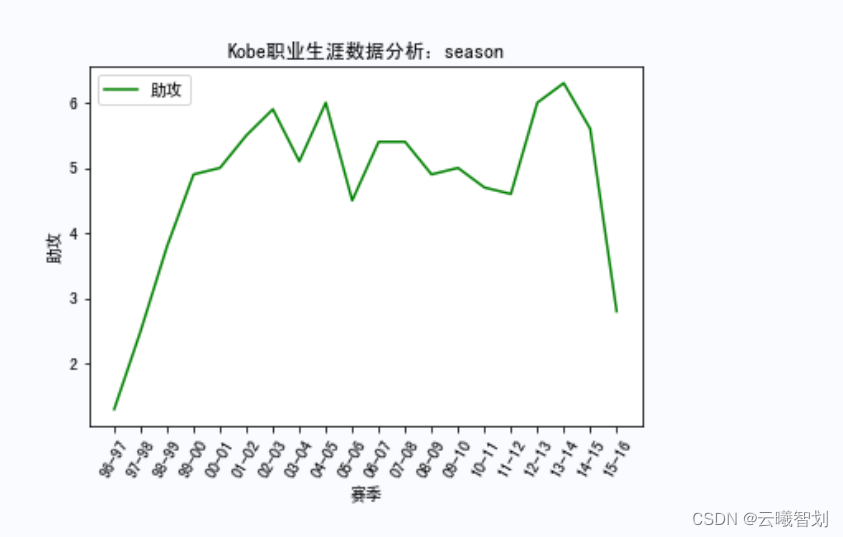
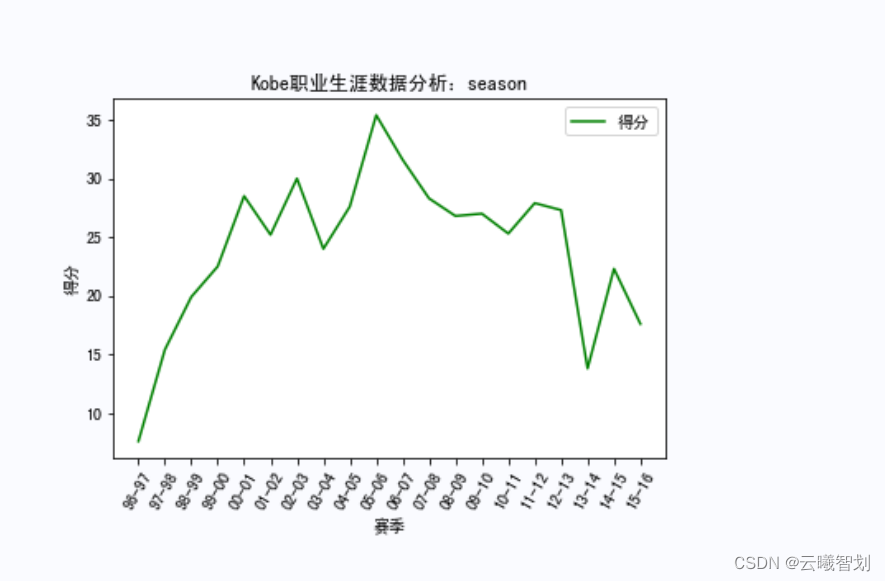
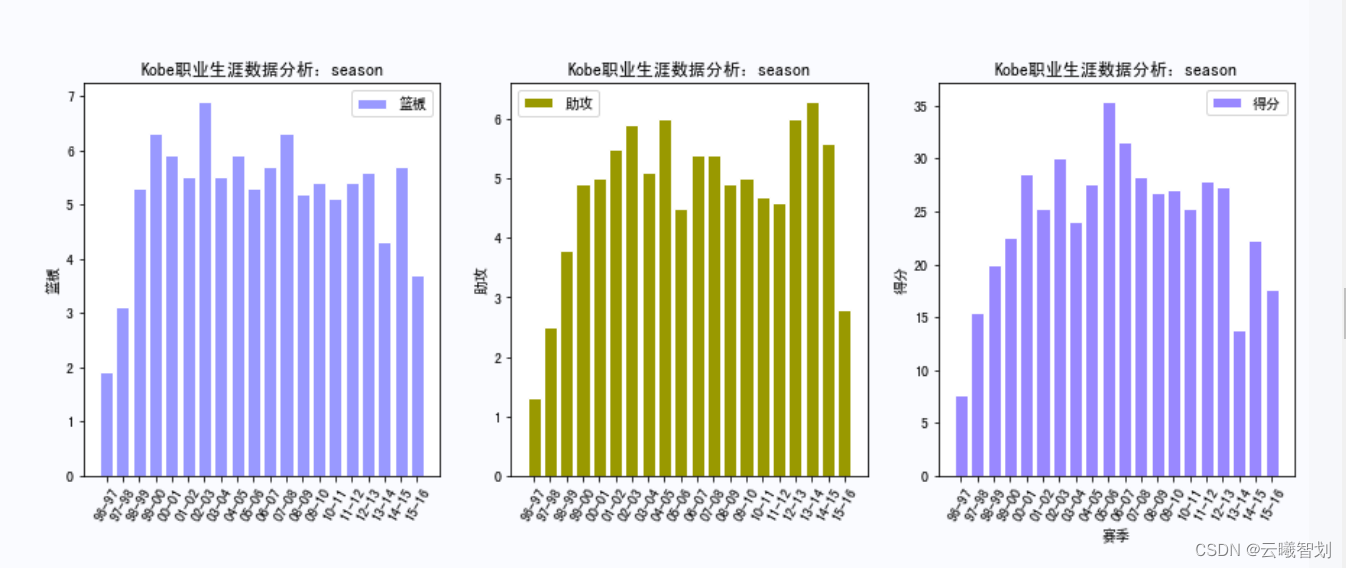
根据上面定义的绘图函数,绘制Kobe在各种赛事中的相关数据,如下图3-1、3-2、3-3所示:
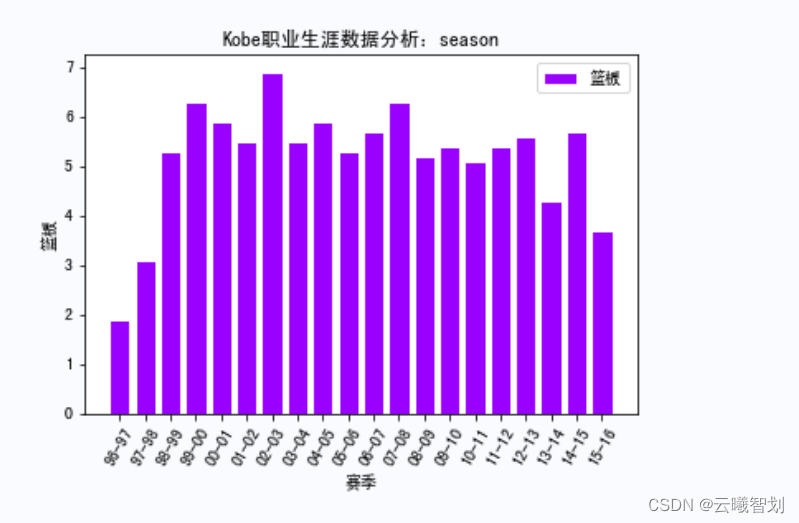
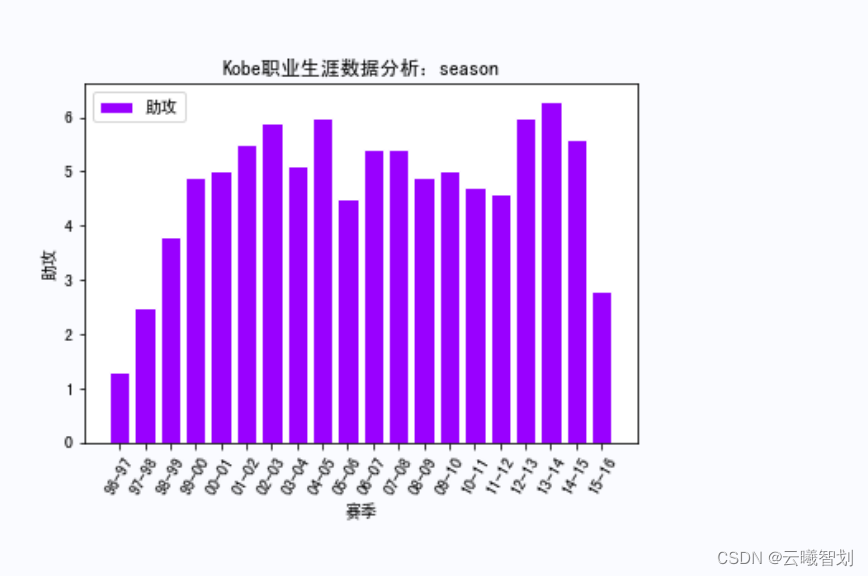
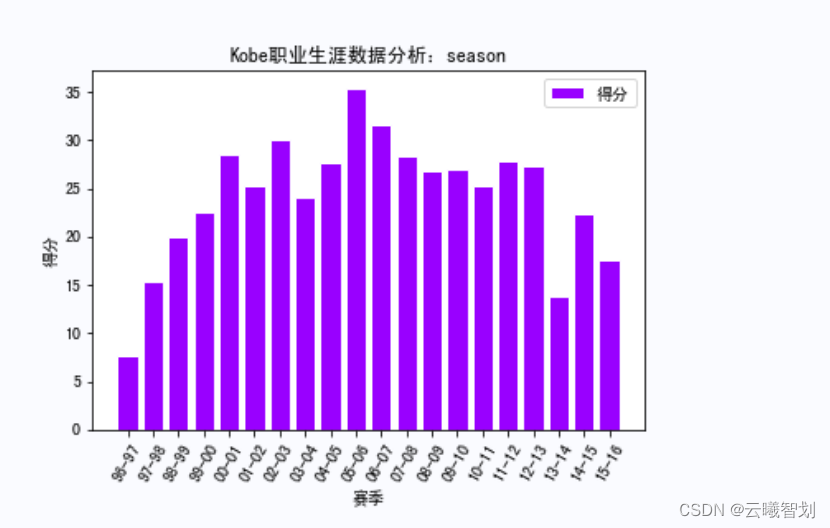
输出部分结果如图3-4至3-8所示:

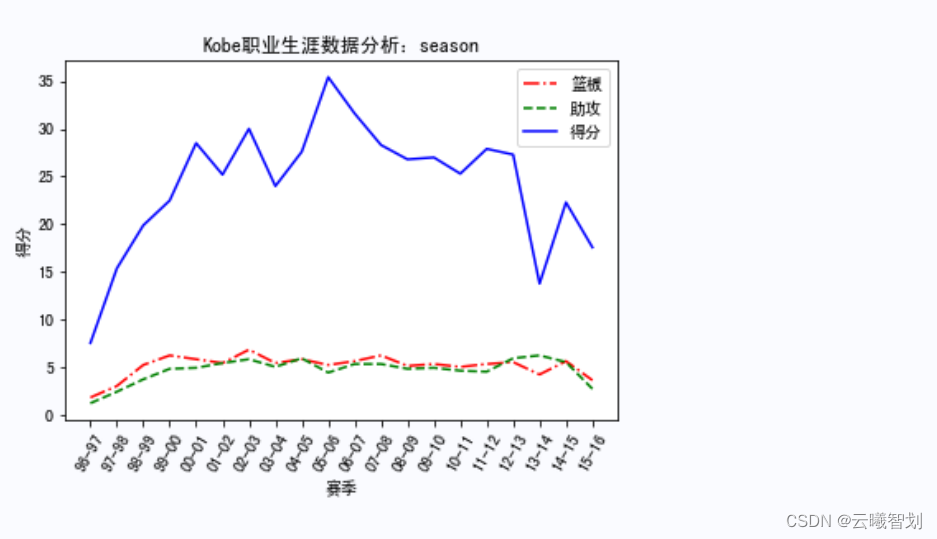
总结
本系列文章内容为根据清华社初版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞浆开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】

版权归原作者 云曦智划 所有, 如有侵权,请联系我们删除。