MoCo代码分析 [自监督学习]
关键词:MoCo 源码分析。
R语言|plot和par函数绘图详解,绘图区域设置 颜色设置 绘图后修改及图像输出
如果bty的值为”o”(默认值)、”l”、”7”、”c”、”u”或者”]”中的任意一个,对应的边框类型就和该字母的形状相似,如果bty的值为”n”,表示无边框。R语言绘图讲解
机器学习中的七种分类算法
Spike-and-slab priors(SSP):尖峰和平板先验
自动驾驶入门必须要学会的ADAS(详解)
ADS分类详解
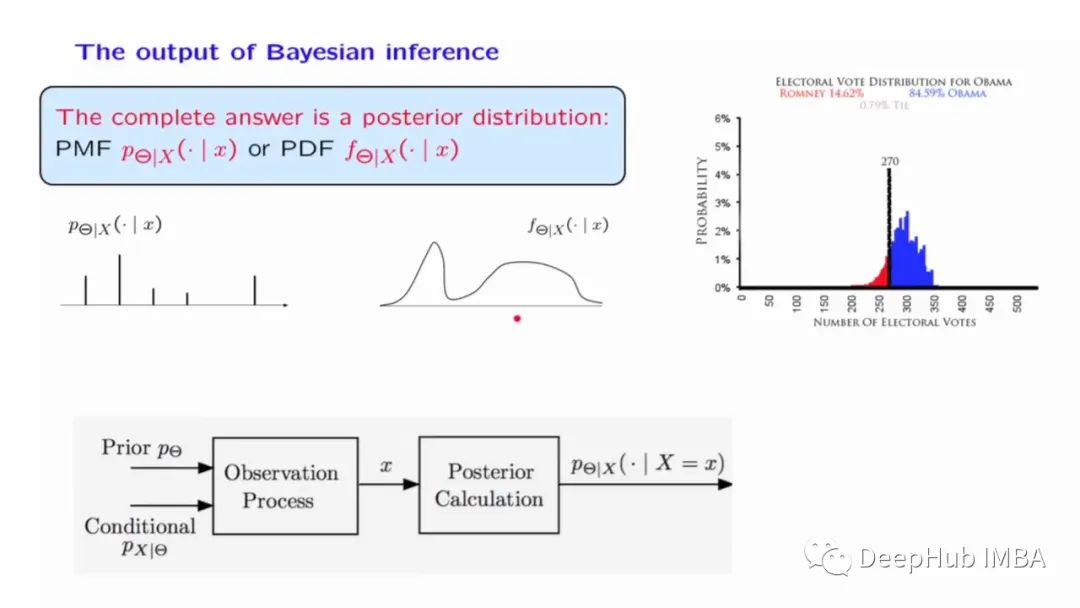
贝叶斯推理三种方法:MCMC 、HMC和SBI
本文将阐明为什么贝叶斯方法不仅在逻辑上是合理的,而且使用起来也很简单。这里将以三种不同的方式实现相同的推理问题。
PhyGeoNet一种可用于不规则区域的物理信息极限学习机
主要就是解决了CNN求解域为非规则形状这样问题,同时将物理信息嵌入CNN中,实现了物理数据双驱动。
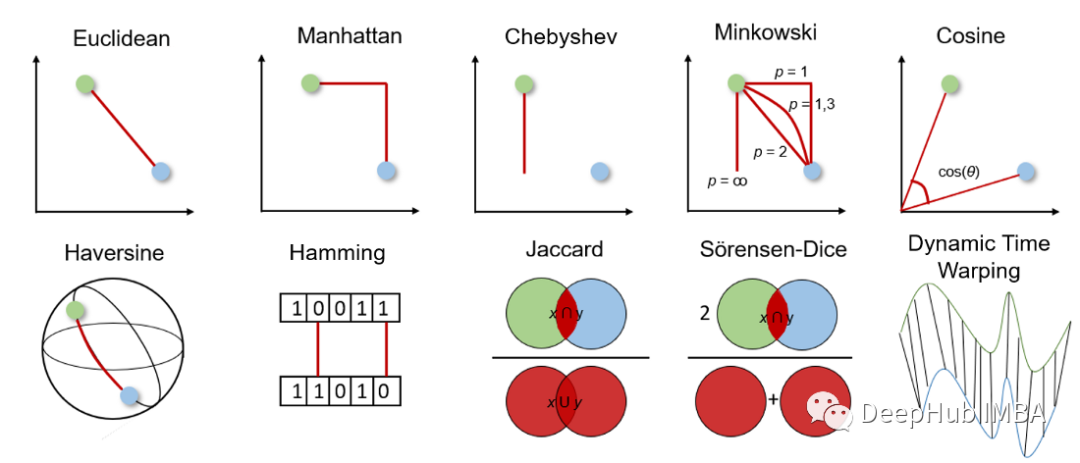
10个机器学习中常用的距离度量方法
距离度量是有监督和无监督学习算法的基础,包括k近邻、支持向量机和k均值聚类等。
手把手带你玩转Spark机器学习-深度学习在Spark上的应用
本文将介绍深度学习在Spark上的应用,我们将聚焦于深度学习Pipelines库,并讲解使用DL Pipelines的方式。我们将讲解如何通过Pipelines实现Transfer Learning,同时通过预训练模型实现来处理少量数据并实现预测。本文主要介绍深度学习在Spark上的应用,以花卉图片
手把手带你玩转需求预测-需求预测方法介绍
预测算法的本质是从历史数据中发现pattern,并利用这个pattern推演到未来,形成预测结果。供应链的绝大多数预测场景中,每个预测目标的历史观测值可以在时间轴上串起来形成一条时间序列(Time Series),因此这些预测问题都可以抽象成为一个时间序列预测的问题。本文会从时序预测技术迭代升级历经
从零入门机器学习之开宗明义:编程与数据思维
大家好,我是herosunly。985院校硕士毕业,热衷于机器学习算法研究与应用。曾获得各种AI比赛的Top名次,并拥有多项发明专利。本文是从零入门机器学习的第一篇文章,主要内容是讲解思维与方法。之所以不是一上来就讲解具体的知识点,主要原因在于市面上讲解知识点的课程数不胜数,主要原因在于市面上讲解知

使用pandas-profiling对时间序列进行EDA
在这篇文章中,我将利用 pandas-profiling 的时间序列特性,介绍EDA中的一些关键步骤。
[机器学习、Spark]Spark MLlib分类
线性支持向量机在机器学习领域中是一种常见的判别方法,是一一个有监督学习模型,通常用来进行模式识别,分类以及回归分析。通过找到支持向量从而获得分类平面的方法,称为支持向量机。可以非常成功地处理回归(时间序列分析)和模式识别(分类问题、判别分析)等诸多问题,并可推广到预测和综合评价等领域,因此可应用于理
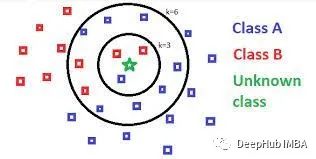
使用KNN进行分类和回归
一般情况下k-Nearest Neighbor (KNN)都是用来解决分类的问题,其实KNN是一种可以应用于数据分类和预测的简单算法,本文中我们将它与简单的线性回归进行比较。
GRAF论文解读
为了解决这个问题,最近的几种方法将基于中间体素的表示与可微渲染相结合。然而,现有方法要么产生低图像分辨率,要么无法解开相机和场景属性,例如,对象身份可能随视点而变化。在本文中,我们提出了一种辐射场的生成模型,该模型最近被证明在单个场景的新颖视图合成方面是成功的。
机器学习之神经网络的公式推导与python代码(手写+pytorch)实现
因为要课上讲这东西,因此总结总结,发个博客模型图假设我们有这么一个神经网络,由输入层、一层隐藏层、输出层构成。(这里为了方便,不考虑偏置bias)输入特征为xn输入层与隐藏层连接的权重为vij隐藏层的输出(经过激活函数)为ym隐藏层与输出层连接的权重为wjk输出层的预测值(经过激活函数)为ol隐藏层
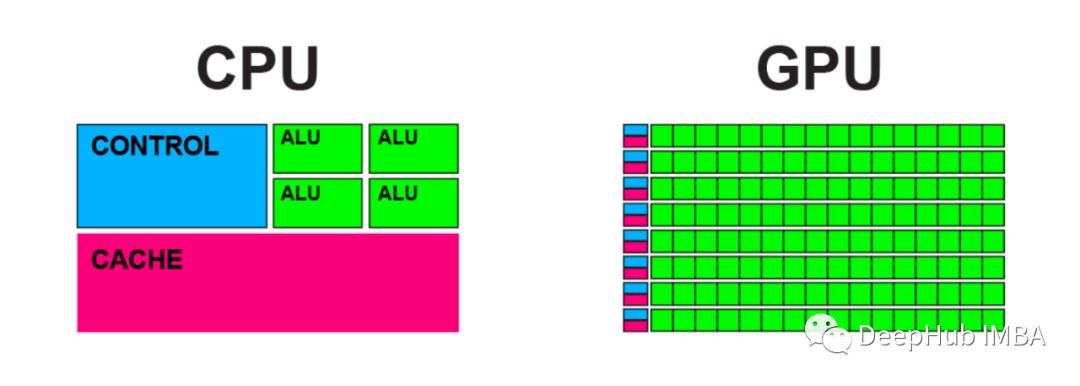
比较CPU和GPU中的矩阵计算
GPU 计算与 CPU 相比能够快多少?在本文中,我将使用 Python 和 PyTorch 线性变换函数对其进行测试。
Bishop 模式识别与机器学习读书笔记_ch1.1 机器学习概述
Bishop著作 《Pattern Recognition and Machine Learning》 读书笔记

构建基于Transformer的推荐系统
使用基于BERT的模型构建基于协同过滤的推荐系统

谷歌AudioLM :通过歌曲片段生成后续的音乐
AudioLM 是 Google 的新模型,能够生成与提示风格相同的音乐。该模型还能够生成复杂的声音,例如钢琴音乐或人的对话。结果是它似乎与原版没有区别,这是十分让人惊讶的。
AdaBoost算法详解及python实现【Python机器学习系列(十八)】
Boosting是机器学习的三大框架之一,其特点是,训练过程中的诸多弱模型,彼此之间有着强依赖关系。Boost也被称为增强学习或提升法。典型的代表算法是AdaBoost算法。AdaBoost算法的核心思想是:将关注点放在预测错误的样本上。



