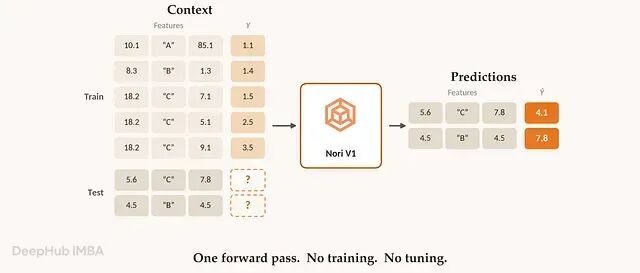
Synthefy Nori:6M 参数的表格基础模型,可以替代 XGBoost 和TabPFN-3
Nori,在零训练 (zero training) 条件下处理回归任务的表格基础模型。
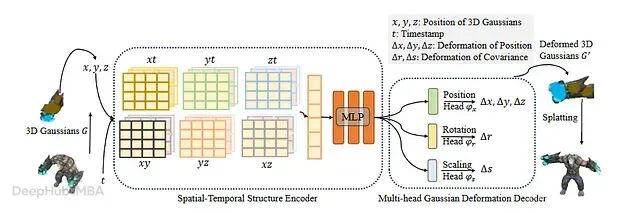
4D Gaussian Splatting 是怎么工作的:从规范 Gaussian 到形变场的原理拆解
4D-GS 靠合适的因子分解和几个关键约束,显式表示照样能搞定时间维度,而不用牺牲让它一开始就站住脚的实时性能。
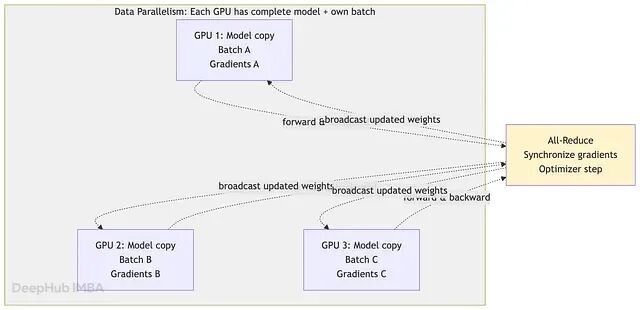
百亿参数模型的并行训练:节点内张量并行、节点间数据并行
瓶颈不在于数据移动的速度,而在于内存里能存多少、以及在移动数据的同时能让 GPU 保持多忙
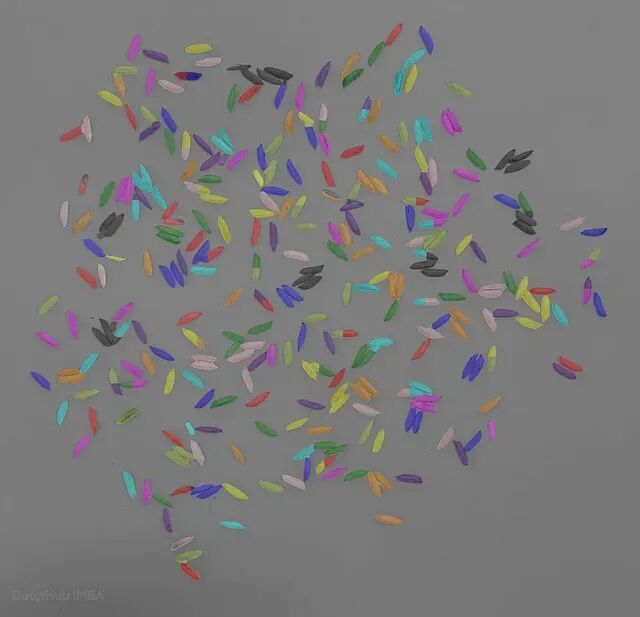
微调LocateAnything-3B 实现超高密度的目标检测
微调LocateAnything-3B,实现当图像中有 300+ 个密集重叠目标、人工标注不可行时的实用方案。
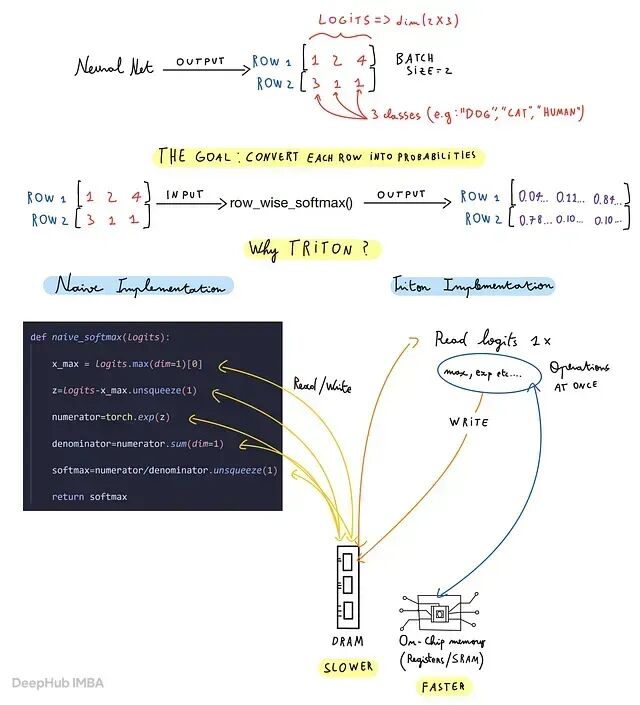
手写 Triton Softmax Kernel:程序实例、块大小、mask 与指针算术
以官方 Triton 教程为基础,深入代码背后的原理并配上手绘图解。如果你觉得 GPU 编程教程总是太晦涩,这篇文章正好可以用来入门。
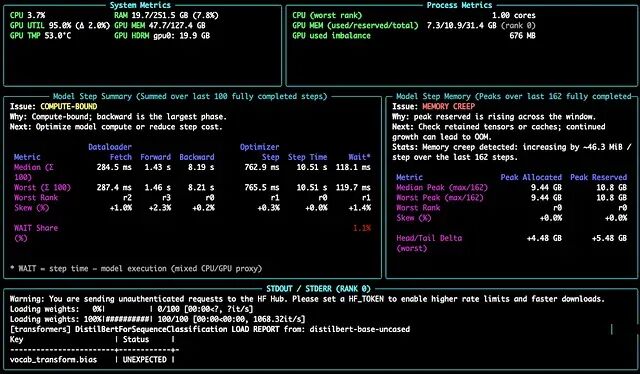
TraceML:用三行代码为训练循环加入 step 级诊断
TraceML 是开源的目前支持单 GPU 以及单节点 DDP/FSDP;多节点支持很快会推出。
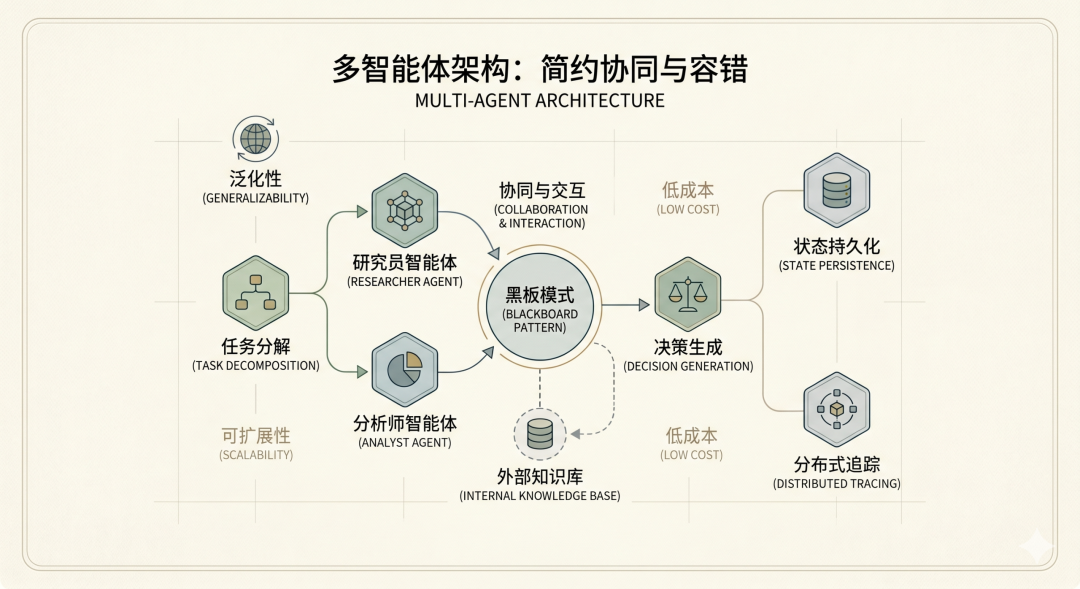
告别脆弱的单体应用,用多智能体网络构建稳定的生产力工具
本文深度解析了 AI 应用从单体大模型向多智能体(Multi-Agent)架构演进的技术趋势与工程实践。面对复杂业务,多智能体系统凭借角色分工与优雅降级展现出极强的泛化性
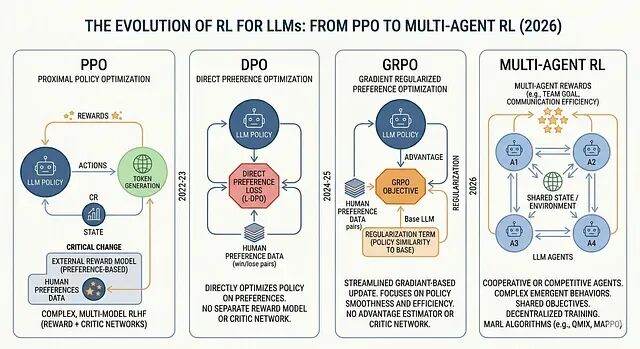
2026 年面向 LLM 的 RL方法总结:从 PPO 到 DPO 到 GRPO,再到多智能体 RL
本文是对当前格局的一次梳理。会用一点篇幅讲历史,更多篇幅留给 PPO、DPO、GRPO 和 MARL——它们是什么、各自适合什么场景、实际中会在哪里坏掉,以及今天的开源技术栈大概长什么样。
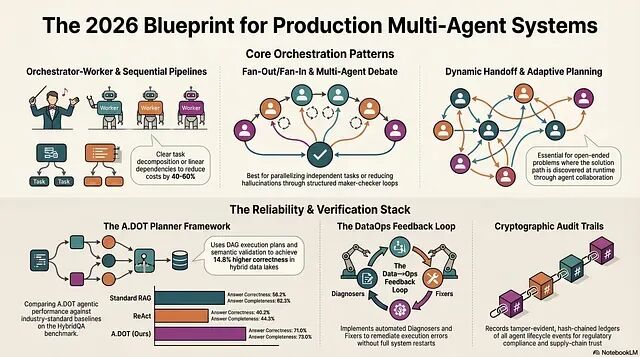
构建一个可自我改进的多 Agent RAG 系统:架构、评估,以及带人工审核的 Prompt 反馈闭环
本文描述的系统包含一个自我改进的评估闭环:自动定位表现不佳的 Prompt 维度,给出有针对性的改写方案,并通过一道由量化回归检测把关的人工审批步骤来决定是否上线。
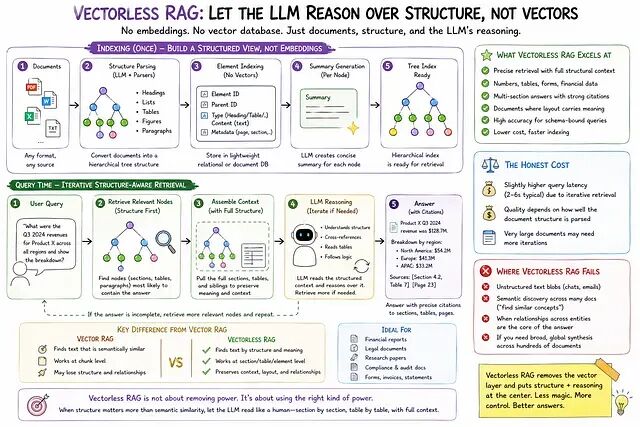
2026 RAG 选型指南:Vector、Graph、Vectorless 该怎么挑
这篇文章将介绍它们之间的差异,让你不必花三周读论文也能为自己的系统做出正确选择。
用 Playwright 和 LLM 实现自愈测试自动化
Playwright 是一个用于 Web 自动化和端到端测试的开源框架。
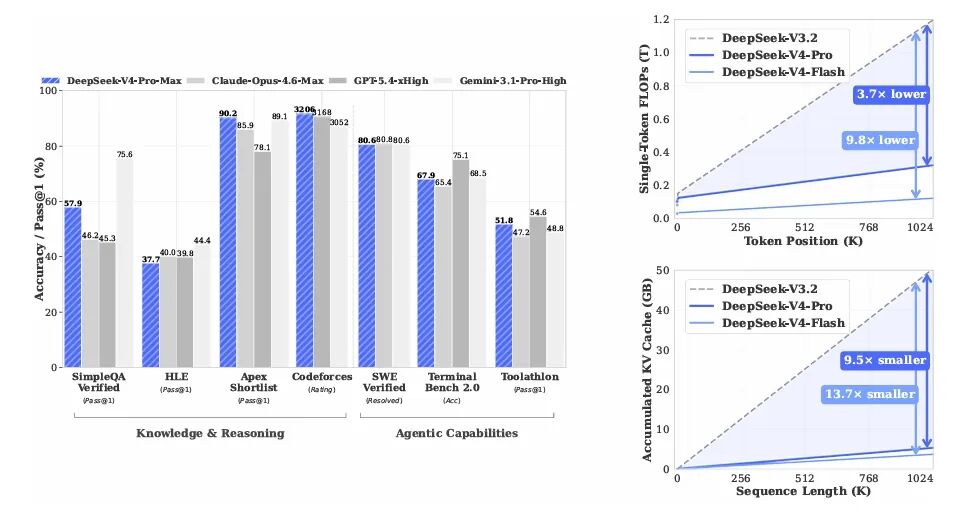
DeepSeek-V4 深度解读:百万上下文背后的工程细节
本文围绕三个问题:长上下文效率到底怎么破(架构);万亿 MoE 怎么稳定训练(基础设施 + trick);十几个领域专家如何合并成一个模型(后训练)。
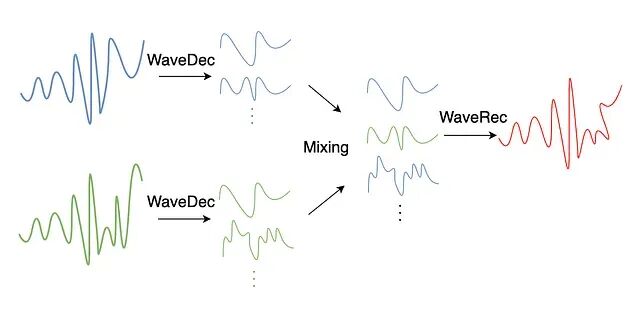
时间序列预测增强方法总结:频域、分解、patch
数据增强是现代机器学习中一个绕不开的环节。

Claude Opus 4.7 系统 Prompt 泄露:其中的10 个核心设计决策解读
Claude 4.7刚发布不久他的Prompt就已经被Hack出来了,仔细看 Claude 的系统设计会发现一件有意思的事:它不只追求聪明,还在试图约束自身的行为。
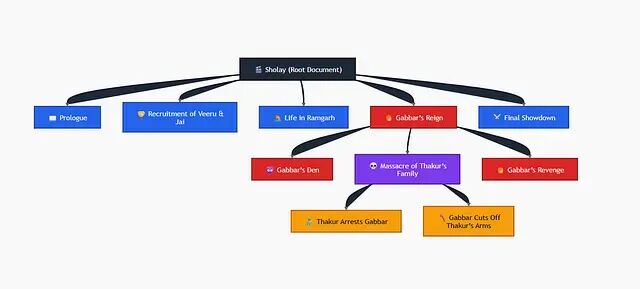
无 Embedding、无向量数据库的 RAG 方法:PageIndex 技术解析
传统 RAG 的假设:相关性等于语义相似度。PageIndex 的假设:相关性等于结构化推理。
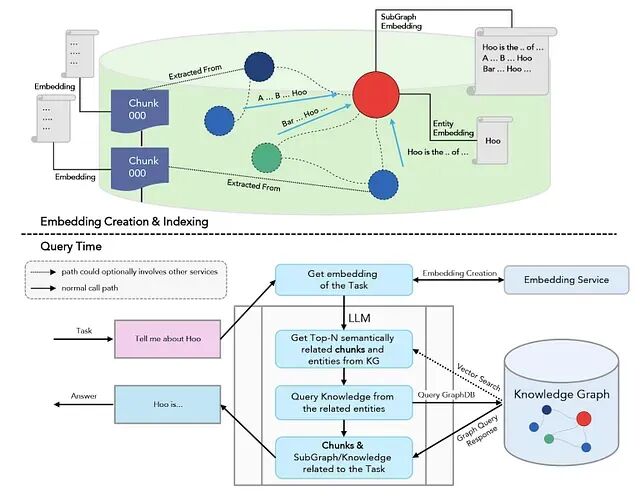
Karpathy的LLM Wiki:一种将RAG从解释器模式升级为编译器模式的架构
Karpathy没有发明新技术,他在清晰阐述一个工作流模式,让LLM天生擅长的事——快速阅读、综合、交叉引用、一致地遵循约定——去接替人类一直需要但从未能持续做好的工作。
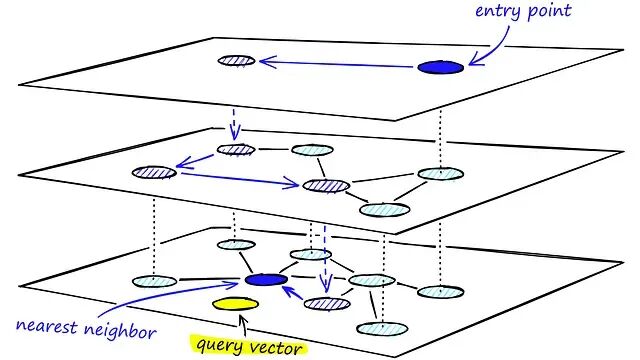
向量相似性搜索详解:Flat Index、IVF 与 HNSW
Flat Index、IVF 和 HNSW:你需要了解的向量搜索算法
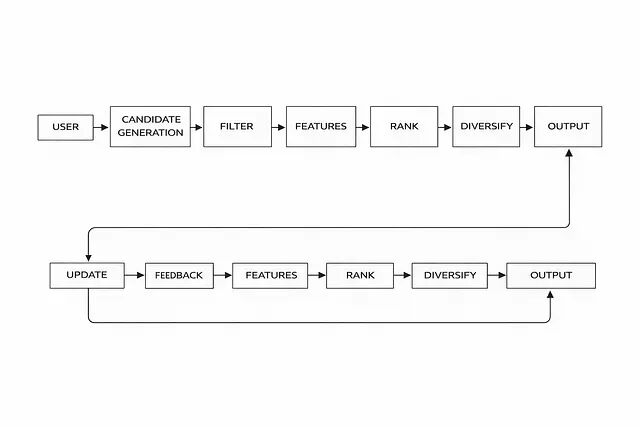
拆解推荐系统:候选生成、过滤、排序、多样性的分层设计
本文梳理一条可以实际构建并持续扩展的端到端推荐 Pipeline。

向量数据库对比:Pinecone、Chroma、Weaviate 的架构与适用场景
本文对比三个主流方案,每个都附有 Python 代码,均来自实际在生产环境中使用三者的经验。
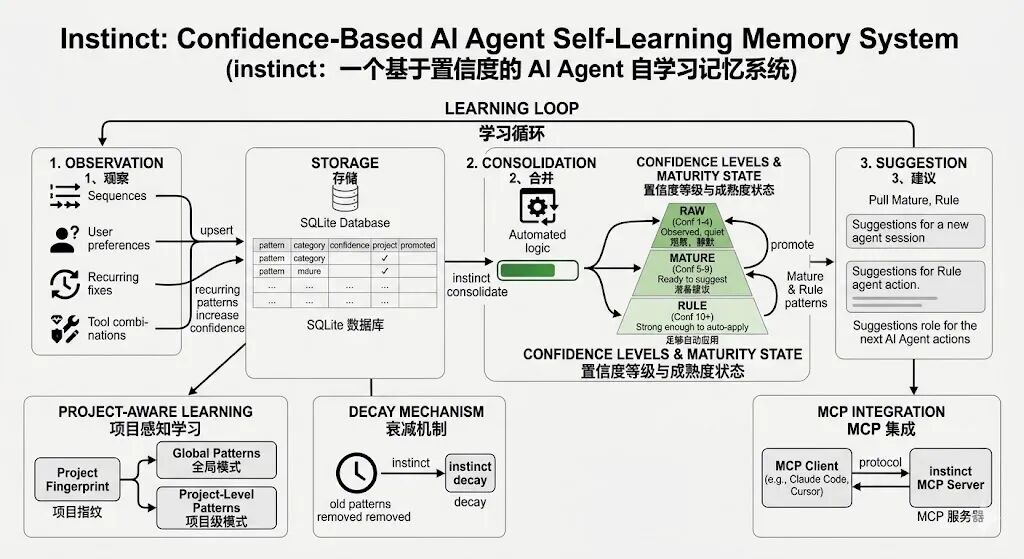
instinct:一个基于置信度的 AI Agent 自学习记忆系统
记忆应当是 Agent 在反复实践中习得的,而非人工分配的。



