
要处理文本数据,需要比数字类型的数据更多的清理步骤。为了从文本数据中提取有用和信息,通常需要执行几个预处理和过滤步骤。
Pandas 库有许多可以轻松简单地处理文本数据函数和方法。在本文中,我介绍将学习 5 种可用于过滤文本数据(即字符串)的不同方法:
- 是否包含一系列字符
- 求字符串的长度
- 判断以特定的字符序列开始或结束
- 判断字符为数字或字母数字
- 查找特定字符序列的出现次数
首先我们导入库和数据
import pandas as pd
df = pd.read_csv("example.csv")
df
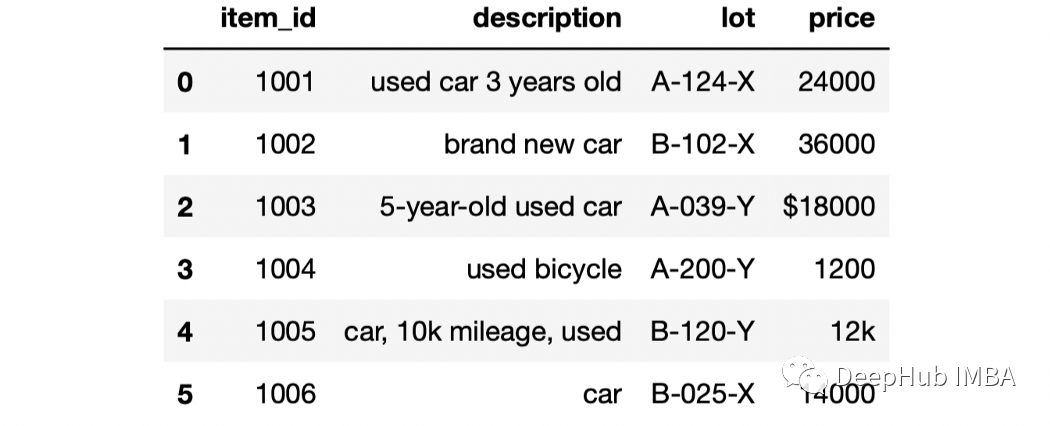
我们这个样例的DataFrame 包含 6 行和 4 列。我们将使用不同的方法来处理 DataFrame 中的行。第一个过滤操作是检查字符串是否包含特定的单词或字符序列,使用 contains 方法查找描述字段包含“used car”的行。但是要获得pandas中的字符串需要通过 Pandas 的 str 访问器,代码如下:
df[df["description"].str.contains("used car")]

但是为了在这个DataFrame中找到所有的二手车,我们需要分别查找“used”和“car”这两个词,因为这两个词可能同时出现,但是并不是连接在一起的:
df[df["description"].str.contains("used") &
df["description"].str.contains("car")]
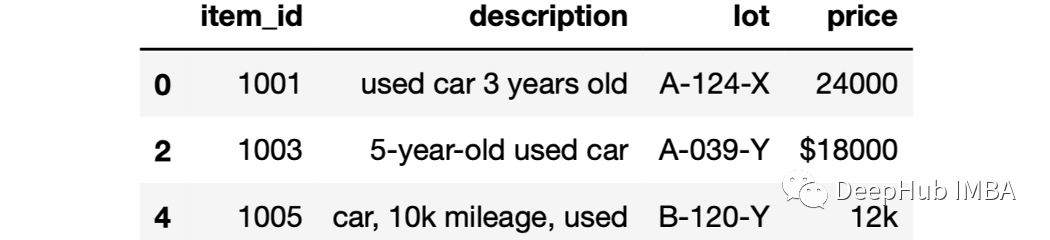
可以看到最后一行包含“car”和“used”,但不是一起。
下一个方法是根据字符串的长度进行过滤。假设我们只对超过 15 个字符的描述感兴趣。可以使用内置的 len 函数来执行此操作,如下所示:
df[df["description"].apply(lambda x: len(x) > 15)]
这里就需要编写了一个 lambda 表达式,通过在表达式中使用 len 函数获取长度并使用apply函数将其应用到每一行。执行此操作的更常用和有效的方法是通过 str 访问器来进行:
df[df["description"].str.len() > 15]

我们可以分别使用startswith和endswith基于字符串的第一个或最后一个字母进行过滤。
df[df["lot"].str.startswith("A")]
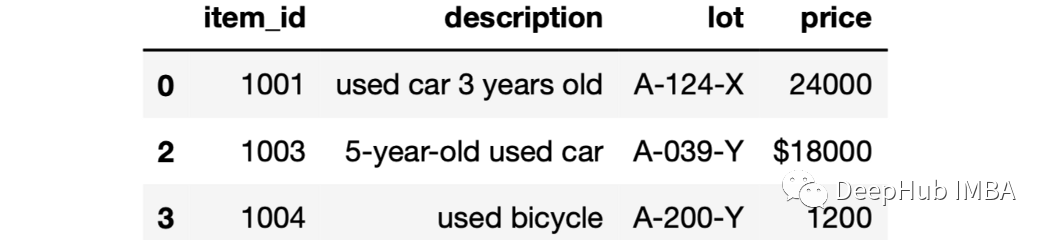
这个方法也能够检查前 n 个字符。例如,我们可以选择以“A-0”开头的行:
df[df["lot"].str.startswith("A-0")]

Python 的内置的字符串函数都可以应用到Pandas DataFrames 中。例如,在价格列中,有一些非数字字符,如 $ 和 k。我们可以使用 isnumeric 函数过滤掉。
df[df["price"].apply(lambda x: x.isnumeric()==True)]

同样如果需要保留字母数字(即只有字母和数字),可以使用 isalphanum 函数,用法与上面相同。
count 方法可以计算单个字符或字符序列的出现次数。例如,查找一个单词或字符出现的次数。
我们这里统计描述栏中的“used”的出现次数:
df["description"].str.count("used")
# 结果
0 1
1 0
2 1
3 1
4 1
5 0
Name: description, dtype: int64
如果想使用它进行条件过滤,只需将其与一个值进行比较,如下所示:
df[df["description"].str.count("used") < 1]
非常简单吧
本文介绍了基于字符串值的 5 种不同的 Pandas DataFrames 方式。虽然一般情况下我们更关注数值类型的数据,但文本数据同样重要,并且包含许多有价值的信息。能够对文本数据进行清理和预处理对于数据分析和建模至关重要。