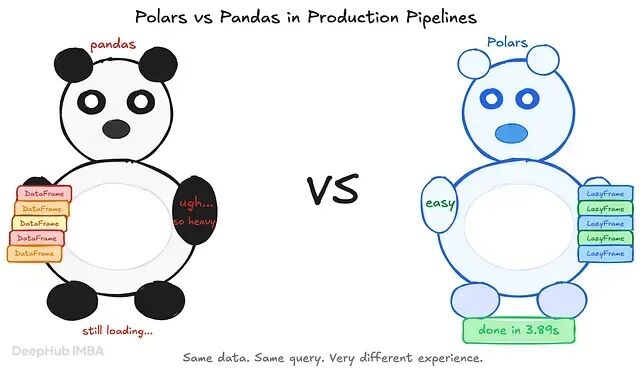
Polars vs Pandas 在生产 Pipeline 中的对比
Pandas 不是遗留技术,它是精准的专用工具;Polars 是另一种工作的精准专用工具。为每项工作选择合适的,不是迁移项目,是工程判断力。

UV vs pip vs Conda:Python环境管理应该怎么选
对于任何在意可维护性和可重现性的项目,请选择 uv。
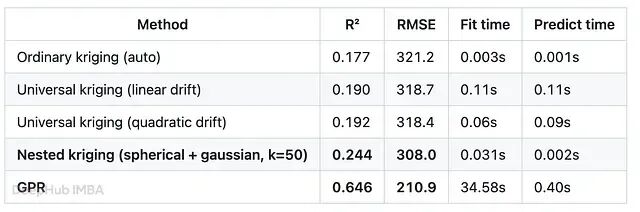
为什么Kriging 与高斯过程回归出自同一数学框架,但实际效果却差很远
本文将在 SPE9 数据集上跑了一套正面对比,覆盖多种 Kriging 变体、GPR 以及几个 ML 基线,还包括用 5 折和 20 折交叉验证重复了一遍,看稳定性。

Flash-KMeans:快速且内存高效的精确 K-Means,可在单张 GPU 进行亿级数据的聚类
本文介绍 Flash-KMeans是一个近期提出的框架,它受 Flash(最小化数据移动)的启发,论文给出了一种执行精确 K-Means 的方案,速度更快内存效率也远优于 FAISS 等行业标准实现
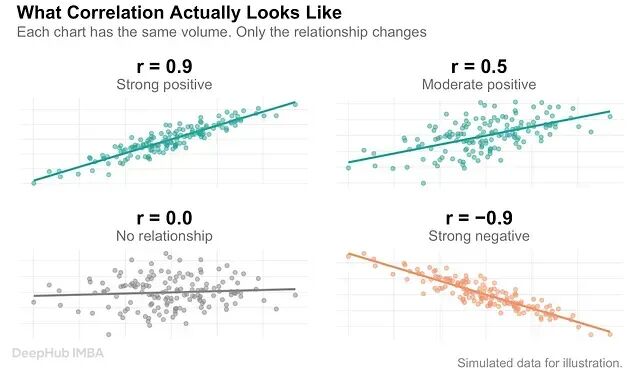
相关性与因果性:识别伪相关以提升模型在真实环境的可用性
相关性表示两个指标存在同步变动趋势,因果性则代表一件事直接促成了另一件事。两者之间有着一道需要用严谨论证来填补的鸿沟。测算相关性毫无门槛但是证明因果关系却极度困难。

让机器学习 Pipeline 更稳的 5 个 Python 装饰器代码
下面介绍 5 个适合现代 AI 开发流程的 Python 装饰器。
Feature Engineering 实战:Pandas + Scikit-learn的机器学习特征工程的完整代码示例
Feature engineering 是机器学习 pipeline 里最关键的一环。
机器学习特征工程:缩放、编码、聚合、嵌入与自动化
好模型的秘诀不在于更花哨的算法,而在于更好的特征。

10个内置在 Pandas 中却常被忽略的向量化操作
本文整理了10个这样的写法,每个都附带常见的冗长版本作为对照。

10个内置在 Pandas 中却常被忽略的向量化操作
本文整理了10个这样的写法,每个都附带常见的冗长版本作为对照。
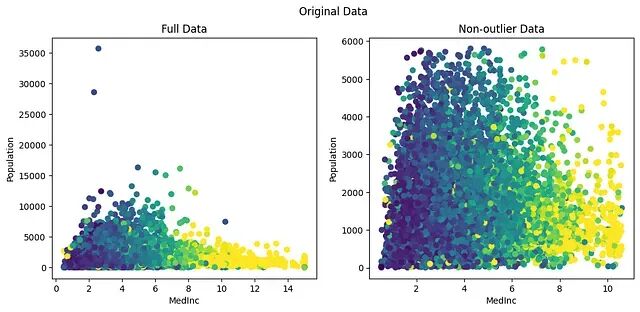
数值特征工程中的四种缩放方法:原理、适用场景与局限性
数值特征工程是机器学习模型训练中不可跳过的预处理环节。处理数值数据时需要面对两个核心问题:特征的量级差异和异常值。

9个提升Python代码生产质量的第三方库
这9个库覆盖了日常开发中几个反复出现的痛点:嵌套数据访问、标准库功能缺失、运行时类型安全、错误处理模式、时区陷阱、性能分析、测试断言、重试机制和数据管道。
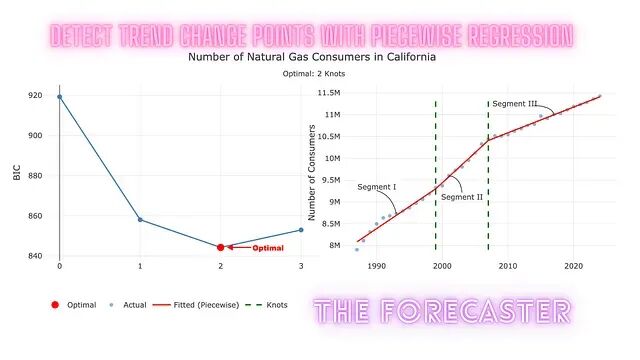
基于网格搜索与分段回归的时间序列变化点检测方法
传统统计方法在时间序列分析中既简洁又有力,但面对大规模时间序列集合时,扩展性往往不尽如人意。现实中的趋势变化往往微弱、带有噪声、数量也不止一个,靠肉眼判断既不可靠也不现实。

Python标准库里藏着的7个代码简化利器
开始使用它们之后,项目体积缩小了,维护成本降低了,自动化也顺畅得多。以下是改变一切的七个技巧。
Energy Distance:度量两个多元分布差异的统计方法
Energy Distance 是一种基于度量的统计工具,适用于衡量两个多元分布的差异程度。

贝叶斯公式推导:从联合概率的对称性看条件反转
本文从简单概率的概念出发,逐步过渡到条件概率,最后介绍贝叶斯定理。整个过程会尽量保持直观,不涉及复杂的数学形式。

时间序列异常检测的5种方法:从统计阈值到深度学习
异常检测的核心不在于找出"奇怪的数字",而在于理解每个时间点上什么才算正常。
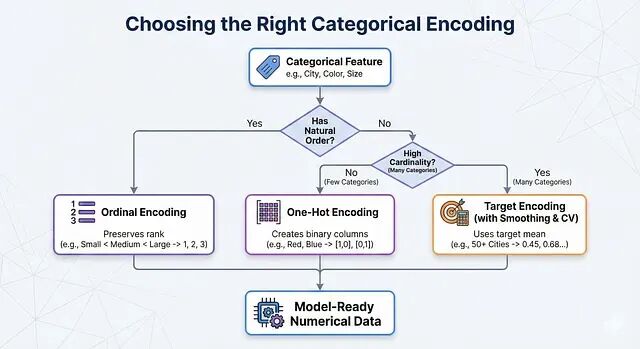
机器学习特征工程:分类变量的数值化处理方法
实际操作中可以这样判断:特征有天然顺序就用 Ordinal Encoding;没有顺序、类别数量也不多就用 One-Hot Encoding;类别太多就上 Target Encoding,记得配合 Smoothing 和交叉验证。
分类数据 EDA 实战:如何发现隐藏的层次结构
这篇文章讲的是如何在 EDA 阶段把这些隐藏结构找出来,用实际的步骤、真实的案例,外加可以直接复用的 Python 代码。
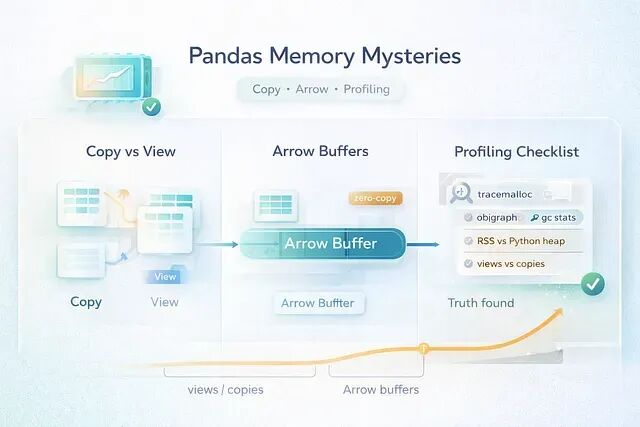
pandas 3.0 内存调试指南:学会区分真假内存泄漏
在pandas 3.0 之后这类情况更多了,因为Copy-on-Write 改变了数据共享的方式,Arrow 支持的 dtype 让内存行为变得更难预测。



