
变分自编码器 (VAE) 是在图像数据应用中被提出,但VAE不仅可以应用在图像中。在这篇文章中,我们将简单介绍什么是VAE,以及解释“为什么”变分自编码器是可以应用在数值类型的数据上,最后使用Numerai数据集展示“如何”训练它。
Numerai数据集数据集包含全球股市数十年的历史数据,在Numerai的锦标赛中,使用这个数据集来进行股票的投资收益预测和加密币NMR的收益预测。
为什么选择VAE?
一般来说 VAE 可以进行异常检测、去噪和生成合成数据。
异常检测
异常检测可以关于识别偏离大多数数据和不符合明确定义的正常行为概念的样本。在 Numerai 数据集中这些异常可能是存在财务异常时期,检测到这些时期会为我们的预测提供额外的信息。
去噪
去噪是从信号中去除噪声的过程。我们可以应用 VAE 对大多数偏离的特征进行降噪。去噪转换噪声特征,一般情况下我们会将异常检测出的样本标记为噪声样本。
生成合成数据
使用 VAE,我们可以从正态分布中采样并将其传递给解码器以获得新的样本。
为什么选择变分自编码器呢?
什么是VAE?
自编码器由两个主要部分组成:
1)将输入映射为潜在空间的编码器
2)使用潜在空间重构输入的解码器
潜在空间在原论文中也被称为表示变量或潜在变量。那么为什么称为变分呢?将潜在表示的分布强制转换到一个已知的分布(如高斯分布),因为典型的自编码器不能控制潜在空间的分布而(VAE)提供了一种概率的方式来描述潜在空间中的观察。因此我们构建的编码器不是输出单个值来描述每个潜在空间的属性,而是用编码器来描述每个潜在属性的概率分布。在本文中我们使用了最原始的VAE,我们称之为vanilla VAE(以下称为原始VAE)
VAE架构
编码器由一个或多个全连接的层组成,其中最后一层输出正态分布的均值和方差。均值和方差值用于从相应的正态分布中采样,采样将作为输入到解码器。解码器由也是由一个或多个完全连接的层组成,并输出编码器输入的重建版本。下图展示了VAE的架构:
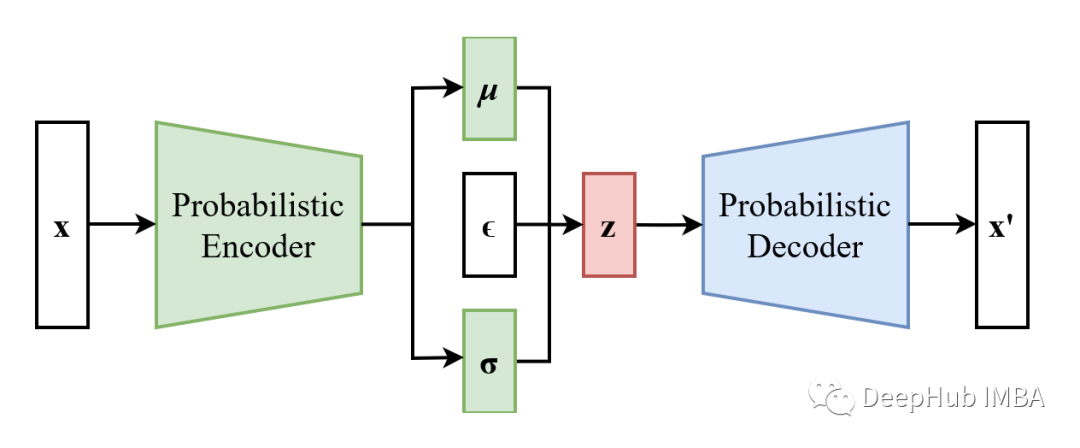
与普通自动编码器不同,VAE编码器模型将输出潜伏空间中每个维度的分布特征参数,而不是潜在空间的值。编码器将输出两个向量,反映潜在状态分布的均值和方差,因为我们假设先验具有正态分布。然后,解码器模型将通过从这些定义的分布中采样来构建一个潜在向量,之后它将为解码器的输入重建原始输入。
普通 VAE 的损失函数中有两个项:1)重建误差和 2)KL 散度:
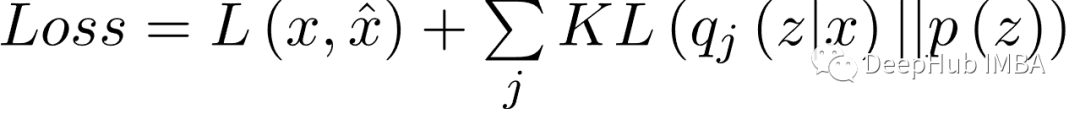
普通 VAE 中使用的重建误差是均方误差 (MSE)。MSE 损失试图使重构的信号与输入信号相似性。KL 散度损失试图使代码的分布接近正态分布。q(z|x) 是给定输入信号的代码分布,p(z) 是正态分布。PyTorch 代码如下所示:
recons_loss = F.mse_loss(recons, input)
kld_loss = torch.mean(-0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim = 1), dim = 0)
原始VAE 配置如下所示:
model_params:
name: 'NumeraiHistogram of KL divergence (left) and mean-squared reconstruction lossVAE'
in_channels: 1191
latent_dim: 32
data_params:
data_path: "/train.parquet"
train_batch_size: 4096
val_batch_size: 4096
num_workers: 8
exp_params:
LR: 0.005
weight_decay: 0.0
scheduler_gamma: 0.95
kld_weight: 0.00025
manual_seed: 1265
trainer_params:
gpus: [1]
max_epochs: 300
logging_params:
save_dir: "logs/"
name: "NumeraiVAE"
配置中的关键参数有:
in_channels:输入特征的数量
latent_dim:VAE 的潜在维度。
编码器/解码器包括线性层,然后是批量归一化和leakyReLU 激活。
编码器的模型定义:
# Build Encoder
modules = []
modules.append(
nn.Sequential(
nn.Linear(in_channels, latent_dim),
nn.BatchNorm1d(latent_dim),
nn.LeakyReLU(),
))
self.encoder = nn.Sequential(*modules)
self.fc_mu = nn.Linear(latent_dim, latent_dim)
self.fc_var = nn.Linear(latent_dim, latent_dim)
解码器的模型定义:
# Build Decoder
modules = []
self.decoder_input = nn.Linear(latent_dim, latent_dim)
modules.append(
nn.Sequential(
nn.Linear(latent_dim, in_channels),
nn.BatchNorm1d(in_channels),
nn.LeakyReLU()
))
self.decoder = nn.Sequential(*modules)
训练VAE
python3 run.py --config configs/numerai_vae.yaml
如果没有报错应该打印以下日志:
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
======= Training NumeraiVAE =======
Global seed set to 1265
initializing distributed: GLOBAL_RANK: 0, MEMBER: 1/1
----------------------------------------------------------------------------------------------------
distributed_backend=nccl
All distributed processes registered. Starting with 1 processes
----------------------------------------------------------------------------------------------------
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]| Name | Type | Params
-------------------------------------
0 | model | NumeraiVAE | 83.1 K
-------------------------------------
83.1 K Trainable params
0 Non-trainable params
83.1 K Total params
0.332 Total estimated model params size (MB)
Global seed set to 1265
Epoch 19: 100%|██████████████████████████████████████████████████████████████████████████| 592/592 [00:20<00:00, 28.49it/s, loss=0.0818, v_num=3]
VAE的应用
如何使用 VAE 进行异常检测?
异常是具有高损失值的样本。损失值可以是重建损失、KL散度损失或它们的组合。
Numerai 训练数据集上的 KL 散度的直方图
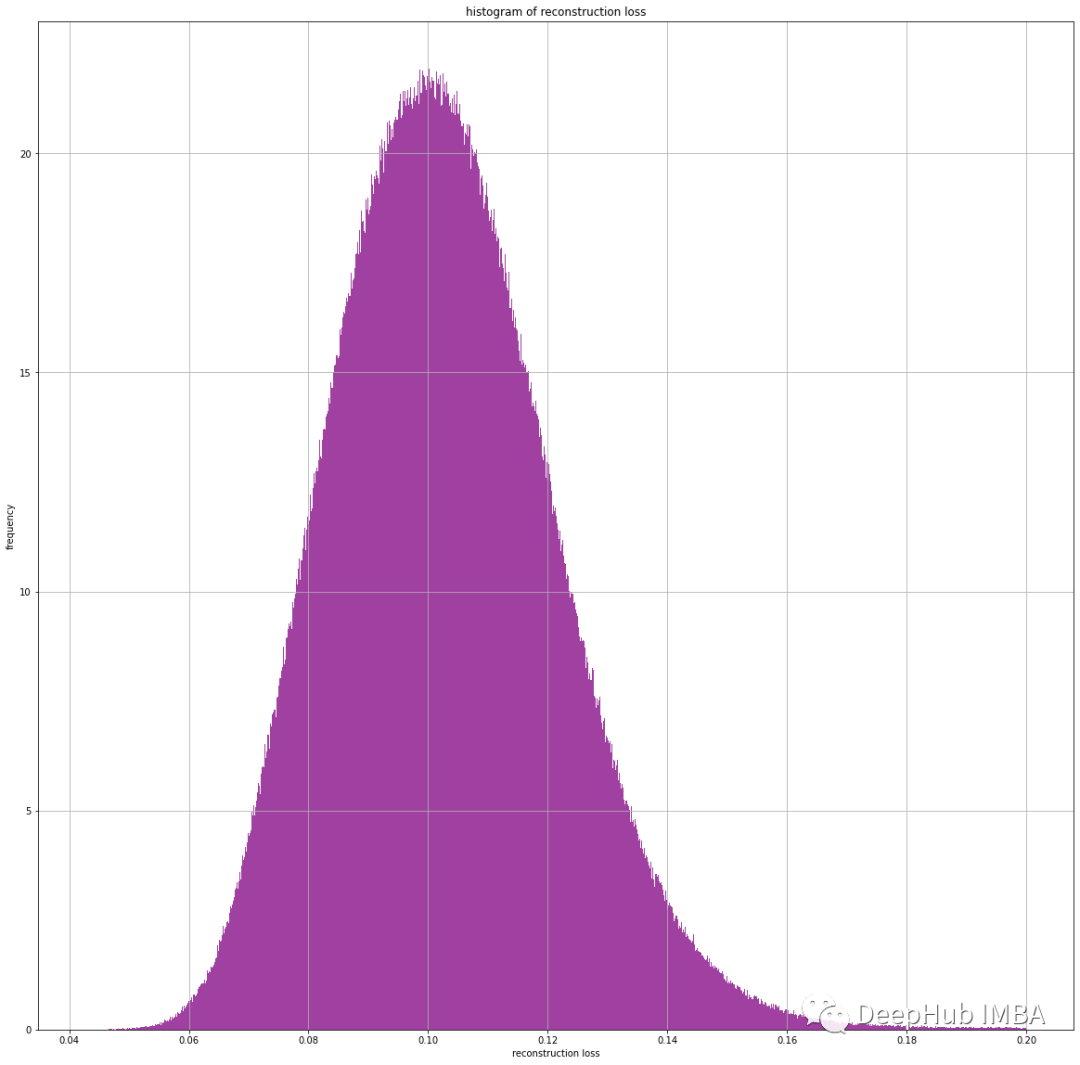
这是MSE损失的直方图。
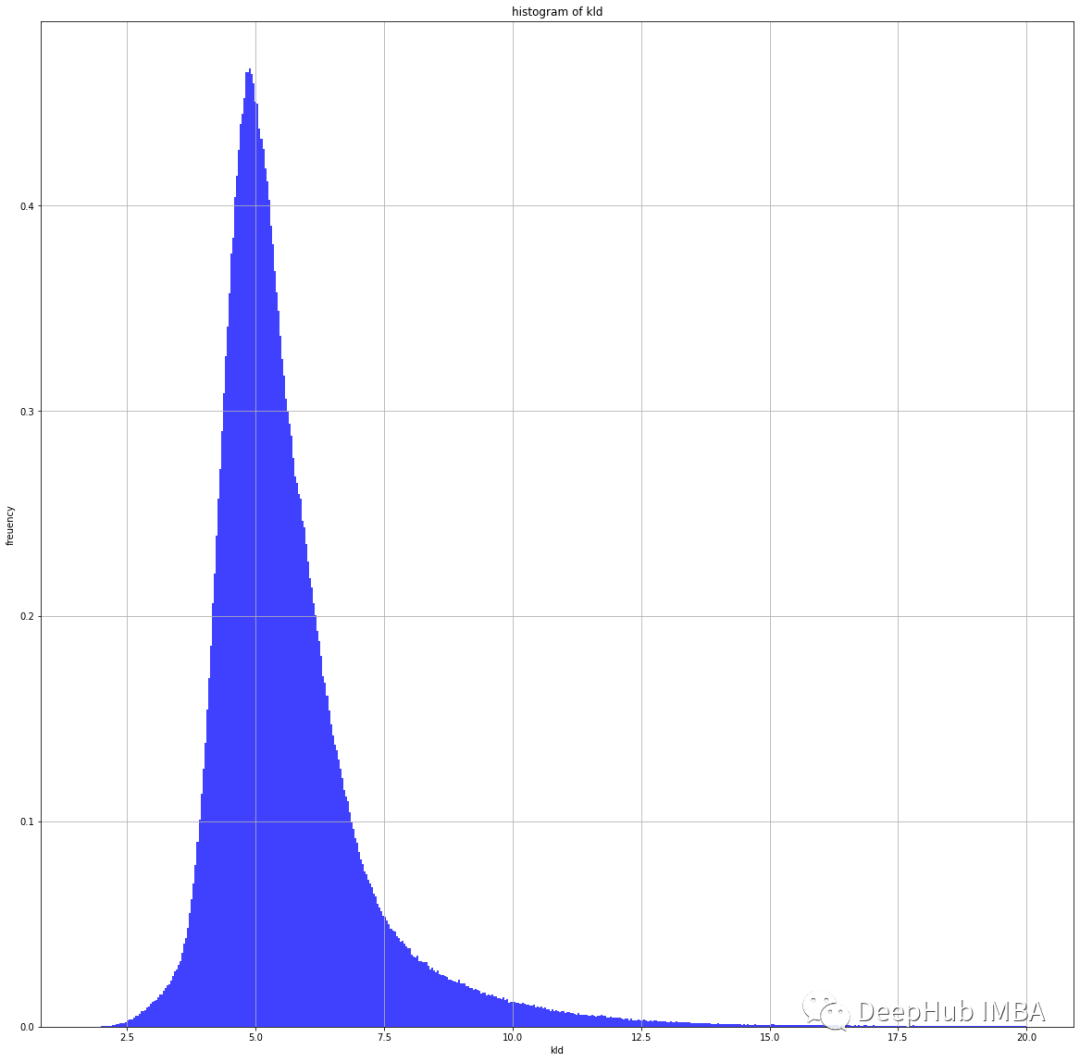
下图是Numerai 训练数据集的 KL 散度和均方误差的可视化。该图训练后的 VAE 的潜在维度为 2,因此我们可以将其可视化。
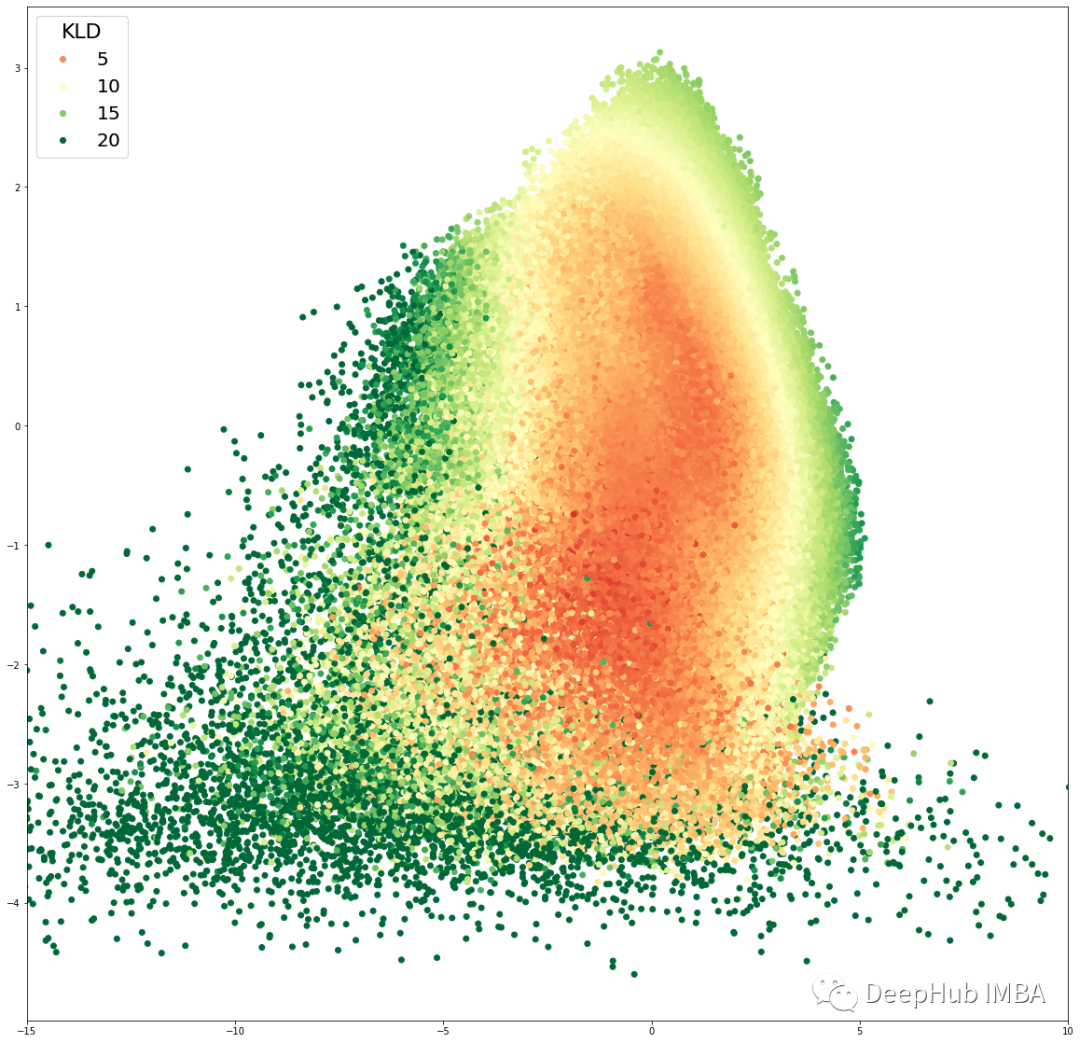
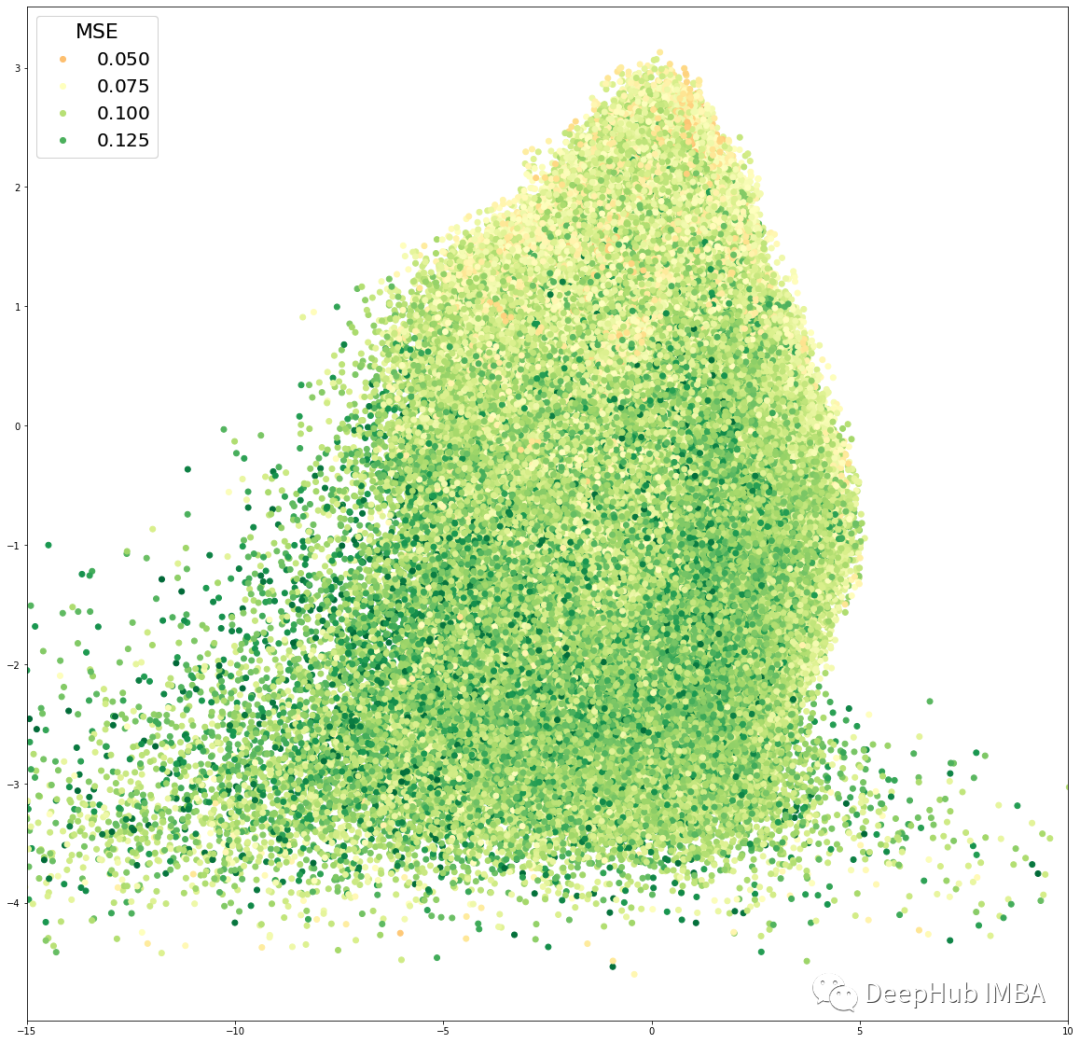
如何用 VAE 去噪?
首先将带有噪声的输入传递给编码器以获取潜在空间。然后将潜在空间传递给解码器以获得去噪后输入(重建输入)。
如何使用 VAE 生成合成数据?
由于解码器的输入遵循已知分布(即高斯分布),我们可以从高斯分布中采样并将值传递给解码器就可以获得新的合成数据。
本文引用:
VAE论文:https://arxiv.org/abs/1312.6114
这个github代码包含了很多的VAE实现,我们这里只是用了原始的VAE(也就是与上面论文相同的VAE):
https://github.com/AntixK/PyTorch-VAE
作者:Amir Erfan Eshratifar