
10个Pandas的小技巧
pandas是数据科学家必备的数据处理库,我们今天总结了10个在实际应用中肯定会用到的技巧
5000字用C++带你入门马氏链。
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。其中马尔科夫过程在预测模型上面的作用很大,校园图书馆管理人员根据当前学生们借阅图书的情况,需要用到马氏链来进行预测,股票行情的涨跌幅,状态分类。以及农业生态环境上面的改善,马氏链都做出了
人工智能基础:机器学习常见的算法介绍
监督学习是机器学习当中非常常见的一种机器学习类型,就是在已知输入输出的情况下训练出一个模型,并且将输入映射输出。特点:给出了学习目标(比如实际值、标注等等)。监督学习根据目标结果是离散还是连续,又可以把监督学习划分为分类和回归。
持续学习常用6种方法总结:使ML模型适应新数据的同时保持旧数据的性能
持续学习是指在不忘记从前面的任务中获得的知识的情况下,按顺序学习大量任务的模型。
增加sklearn逻辑回归拟合能力的解决方案
本文主要介绍了增加sklearn逻辑回归拟合能力的解决方案,希望对新手有所帮助。文章目录1. 问题描述2. 解决方案 2.1 不建议的解决方案 2.2 推荐的解决方案
微信版大语言模型来了:跨时空对话李白、教你高情商说话,API在线试玩全都有...
鱼羊 梦晨 发自 凹非寺量子位 | 公众号 QbitAI大规模语言模型,微信版,来了!并且甫一登场,就没藏着掖着:论文、API接口、在线试玩网站……一条龙全都齐备。续写文本、阅读理解等常规任务就不说了,这个名叫WeLM的AI,竟然直接让我和李白跨时空聊起了杜甫:我:现在有一首关于你的歌,其中一句歌词
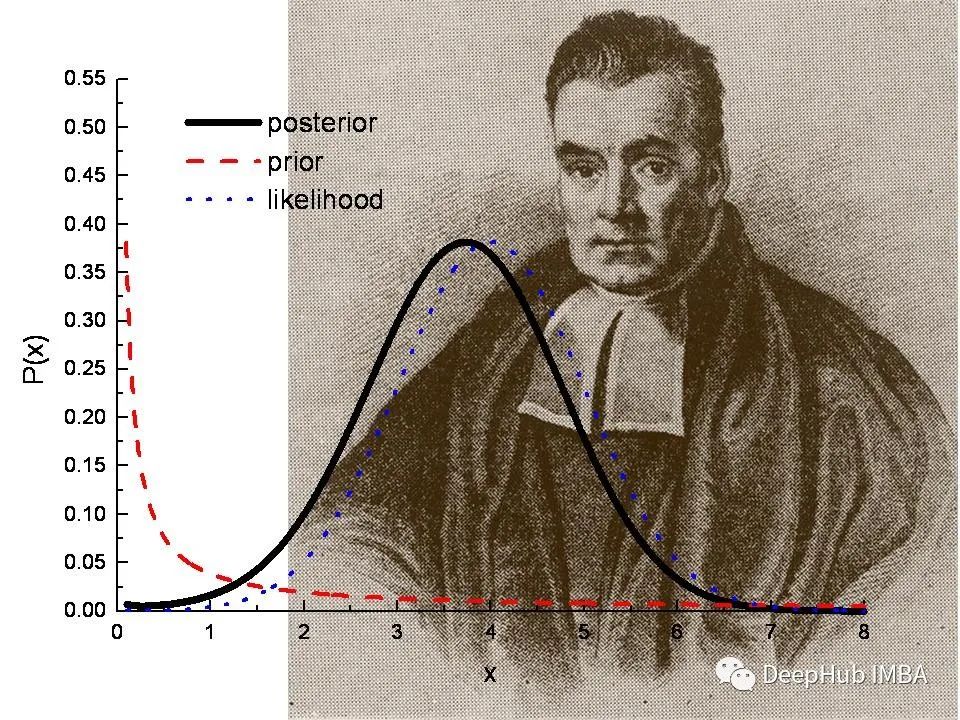
我们能从后验分布中学到什么?贝叶斯后验的频率解释
假设我们从未知分布 q 中观察到 N 个独立且同分布的 (iid) 样本 X = (x1, ... , xN)。统计学中的一个典型问题是“样本集 X 能告诉我们关于分布 q 的什么信息?”。
BP反向传播网络
本文介绍了如何通过反向传播误差修正模型参数,从梯度下降法等原理处学习如何进行反向传播,进而了解为什么模型参数的修正和激活函数相关。

sklearn 中的两个半监督标签传播算法 LabelPropagation和LabelSpreading
标签传播算法是一种半监督机器学习算法,它将标签分配给以前未标记的数据点。要在机器学习中使用这种算法,只有一小部分示例具有标签或分类。在算法的建模、拟合和预测过程中,这些标签被传播到未标记的数据点。
pytorch 实现逻辑回归
简单说明一下任务,想在一个正方形的区域内生成若干点,然后手工设计label,最后通过神经网络的训练,画出决策边界假设:正方形的边长是2,左下角的坐标为(0,0),右上角的坐标为(2,2)然后我们手工定义分界线 y = x ,在分界线的上方定义为蓝色,下方定义为红色。

数据科学家在使用Python时常犯的9个错误
最佳实践都是从错误中总结出来的,所以这里我们总结了一些遇到的最常见的错误,并提供了如何最好地解决这些错误的方法、想法和资源。
机器学习之支持向量机(SVM)的求解方法
支持向量机就是寻找一个超平面,将不同的样本分分隔开来,其中间隔分为硬间隔和软间隔,硬间隔就是不允许样本分错,而软间隔就是允许一定程度上样本存在偏差,后者更符合实际。支持向量机思路简单但是求解过程还是比较复杂,需要将原函数通过拉格朗日乘子法并附上KKT条件是的问题有强对偶性,再使用SMO等算法进行高效
在线薅 达摩院-人工智能训练师(高级)证书
人工智能训练师(高级)
时间序列平滑法中边缘数据的处理技术
金融市场的时间序列数据是出了名的杂乱,并且很难处理。这也是为什么人们都对金融数学领域如此有趣的部分原因!
机器学习:基于朴素贝叶斯实现单词拼写修正器(附Python代码)
本文基于朴素贝叶斯原理实现一个有趣的应用——单词拼写修正器,并梳理一些贝叶斯公式中的细节加深理解,最后给出python代码

2022年10个用于时间序列分析的Python库推荐
去年我们整理了一些用于处理时间序列数据的Python库,现在已经是2022年了,我们看看又有什么新的推荐
Tensorflow2数据集过大,GPU内存不够
在我们平时使用tensorflow训练模型时,有时候可能因为数据集太大(比如VOC数据集等等)导致GPU内存不够导致终止,可以自制一个数据生成器来解决此问题。方法就是将数据集图片的路径保存到一个列表之中,然后使用while循环在训练时进行不断读取,,我在训练时出现了这样的问题,这是我的猜测。

使用PyG进行图神经网络的节点分类、链路预测和异常检测
在这篇文章中,我们将回顾节点分类、链接预测和异常检测的相关知识和用Pytorch Geometric代码实现这三个算法。
分类判别式模型——逻辑斯特回归曲线
本文介绍了分类的判别式模型,从以往机器学习的三大步骤引入;在寻找最优解中,比较了与线性回归梯度下降法的不同;在损失函数层面,比较了交叉熵和square error的差异;在分类模型上,比较是本专栏上文的分类生成模型。最后在多分类问题上进行了扩展,在无法解决的同或问题中引入了特征映射和神经网络的概念。
带掩码的自编码器(MAE)最新的相关论文推荐
7-9月的MAE相关的9篇论文推荐



