
很久没有推荐论文了,但是在推荐新论文之前,首先推荐一个新闻:
谷歌分享了公司内部如何使用代码生成案例,3%的新代码是由语言模型(Language Model)、DeepSpeed (DeepSpeed)编写的,通过语言模型生成代码的智能建议,建议接受率约为25%,减少了6%的编码迭代时间,平均每个接受的建议为21个字符:
https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html
这才是AI在真实世界的应用,并且正在向着更好的方向前进,而不是像某些人成天吹嘘的替代这个、替代那个。
我们回到正题,本次推荐的10篇论文包括:强化学习(RL)、缩放定律、信息检索、语言模型等。
1、Beyond neural scaling laws: beating power law scaling via data pruning
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, Ari S. Morcos.
https://arxiv.org/abs/2206.14486
缩放定律是现代神经网络中普遍存在的经验现象,其中误差被认为是训练集大小、模型大小或两者的幂次。有一些人认为他是正确的,并且设计了一个专注于扩大规模的研究方向。但还有大部分人认为,一定有办法在不超大规模的模型和数据的情况下建立更好的模型。这篇论文探讨了一种能够提高神经网络性能,“战胜”缩放定律的数据剪枝技术。
在这项工作的背景下,剪枝是指从训练数据集中删除训练数据样本而不是修剪神经网络的权重。提出的方法背后的理论很简单:可以在“易于学习”到“难以学习”的训练数据集中对样本进行排名。一个典型的数据集将包含太多易于学习的样本——也就是说,更少的样本就足以在这些样本上达到良好的性能——而来自难以学习的样本又太少——这意味着需要更多的样本来适当地训练模型。
解决这个问题的一种方法是扩大整个训练数据集的规模,因为给定足够大的规模——假设数据分布是均匀的——最终你会得到足够多的“难以学习”的样本。但这是非常浪费的。如果我们可以使用先验来确定一个包含易于学习和难以学习样本的更好平衡的训练数据集,结果会怎么样呢?这就是这篇论文所研究的问题。
这个问题可以形式化为试图找到一个修剪度量分配给每个训练样本,然后根据该度量排序并修剪训练数据集到所需的大小。他们在这篇论文中提出了一个新的衡量标准,可以与现有的需要标记数据的工作相媲美。
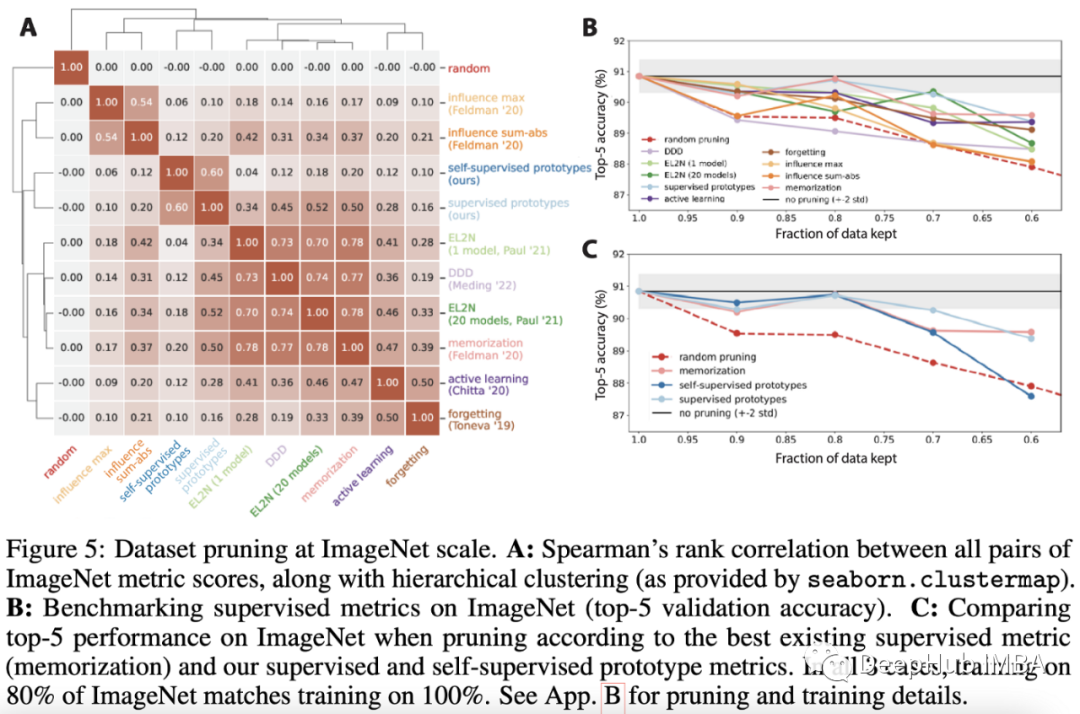
这篇论文中最有趣的贡献是他们关于无标签数据修剪的部分。他们对预训练的ImageNet模型的嵌入进行k-means聚类,并将每个样本的“硬度”定义为其到最近的质心的距离:容易学习的原型样本将最接近质心,而难以学习的样本将远离它们簇的质心。结果表明,大约20%的ImageNet训练样本可以在不牺牲性能的情况下进行修剪。
这篇论文的结果并不令人瞠目,但它背后的关键思想有可能在其他任务中有用,如图像分割、语言建模或任何其他多模态数据集管理。
2、Denoised MDPs: Learning World Models Better Than the World Itself
Tongzhou Wang, Simon S. Du, Antonio Torralba, Phillip Isola, Amy Zhang, Yuandong Tian.
https://arxiv.org/abs/2206.15477
许多机器学习技术的核心是从噪声中识别相关和有用的信号(或模式)的能力。
在强化学习的背景下,这项工作通过识别agent可控的和与奖励相关的信息,形式化了“好的信息与不相关的信息”的问题,如下图所示。
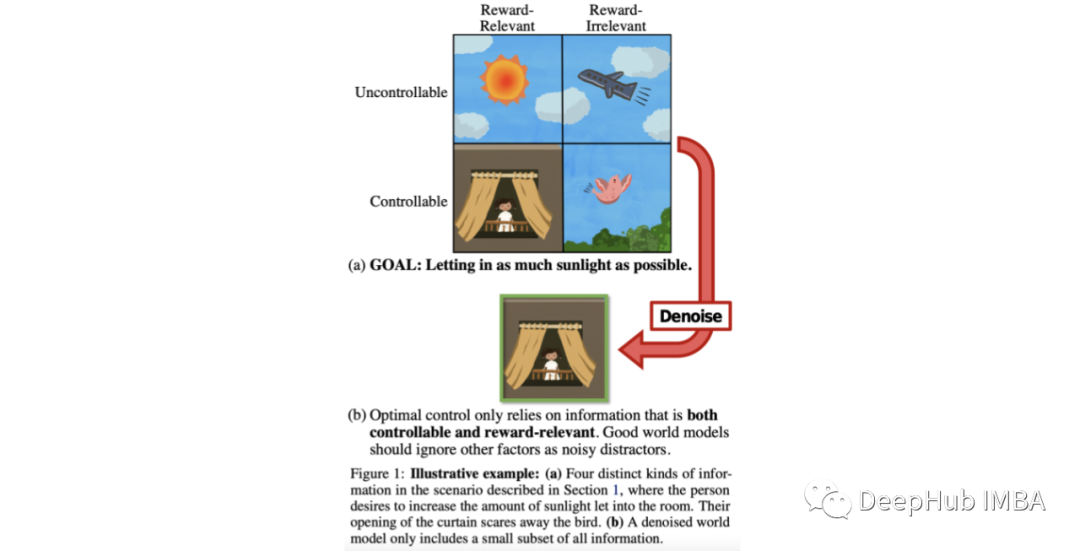
基于这一思想,作者提出了去噪MDPs(马尔科夫决策过程),这是一种学习状态表示的因数分解的方法,该方法利用信息论原理分离了状态的可控和奖励。它的要点是,状态的不同因素应该最大或最小地预测其他因素,这取决于它们的关系,基于以上的理论作者为代理优化设置一个变分目标。
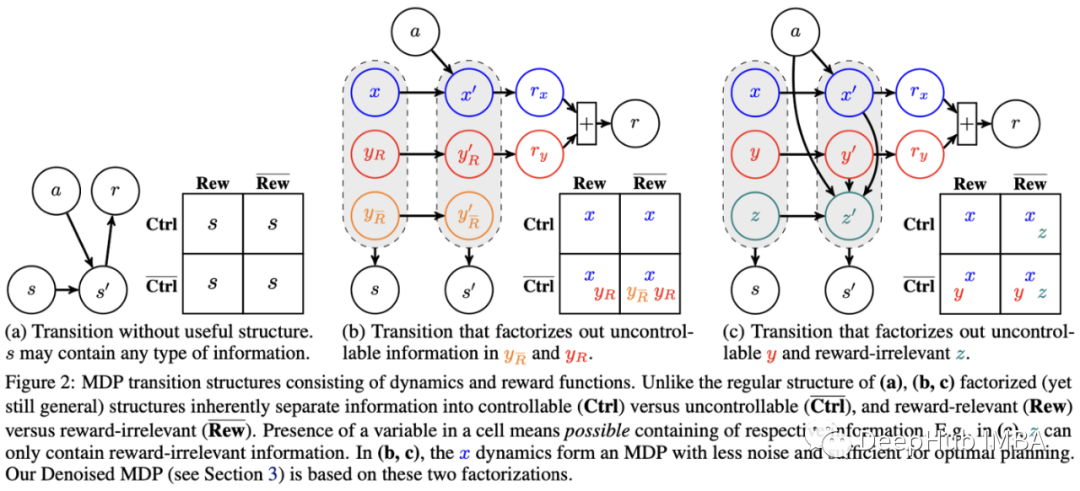
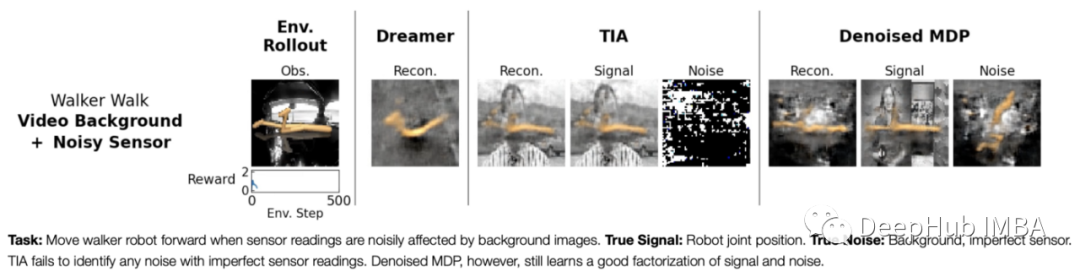
其结果是一个世界模型,该模型明确地建模了哪些信息应该被丢弃为噪声,以及哪些信息应该用于为代理的决策建模。作者证明了这种方法在DeepMind套件中是如何提高性能的,并且他们定性地展示了去噪MDP表示是如何工作的,通过训练一个解码器重构输入,可以理解状态的信号表示学习捕捉什么。
3、Parameter-Efficient Prompt Tuning Makes Generalized and Calibrated Neural Text Retrievers
Weng Lam Tam, Xiao Liu, Kaixuan Ji, Lilong Xue, Xingjian Zhang, Yuxiao Dong, Jiahua Liu, Maodi Hu, Jie Tang.
https://arxiv.org/abs/2207.07087
在过去的几年中,Prompting在NLP方面取得了长足的进步,现在它在信息检索方面似乎也有了进步。
Prompting调优是一种通过向序列模型的输入添加可训练的Prompting标记,使预先训练的冻结模型适应给定任务的技术。与更常见的完整模型微调相比,这种方法的主要优点之一是,它只需要重新训练一小部分参数,这样效率更高,而且可以提高原始预训练模型的可重用性。
他们训练Dense Passage Retriever (通过查询和文档嵌入的最近邻搜索进行检索)和带有后期交互的ColBERT模型(包括查询和文档的联合建模)的方法不是微调整个模型,他们只微调一个Prompting,同时保持预训练的LM权重都是冻结的。通过实现基于P-Tuning v²方法,可训练的Prompting不仅被添加到输入,而且还被添加到Transformer的每一层。
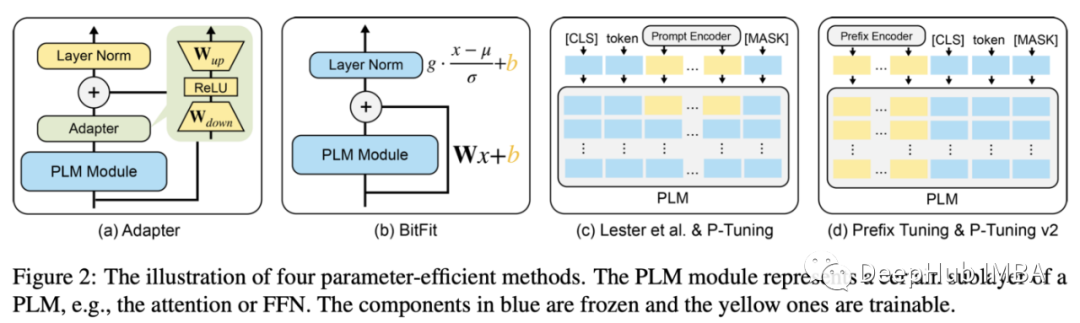
结果中最有趣的部分是泛化。尽管在域内基准测试中,Prompting调优的性能与fine-tuning相当,但它在各种来自BEIR³基准测试的跨域数据集上的性能要好得多。
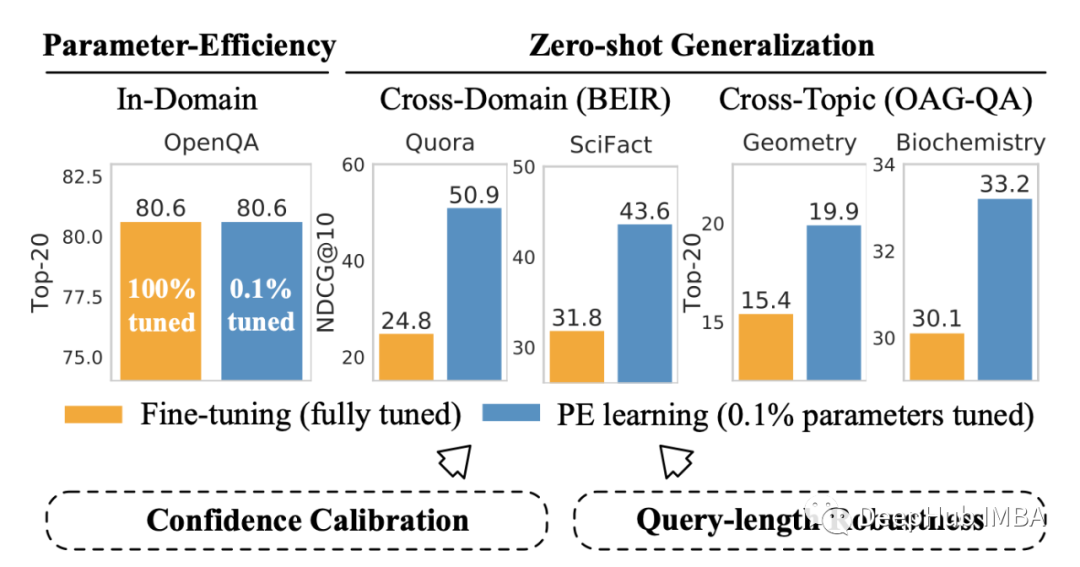
这项研究再次强化了:Prompting是fine-tuning的可行替代方案,而且可能会越来越受欢迎。
4、DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, Yuxiong He.
https://arxiv.org/abs/2207.00032
DeepSpeed——微软开发并使用的用于大型神经网络大规模分布式训练的框架——现在除了训练,还用于推理。
大型transformer架构在过去的一年里已经多样化,它们的通过大尺寸增加了表达能力,在推理时只使用与输入相关的权值子集,这使它们更高效(如果实现也经过优化的话!)但是缺点也很明显,有效地训练和运行这些模型涉及更多的内容,因为大多数现有的深度学习库和硬件在设计时都没有使用这种类型的计算。
DeepSpeed之前是为训练大型transformer而设计的,但最新的更新则侧重于在所有类型的transformer(包括稀疏激活的架构)上提高推理的延迟和吞吐量。
论文谈论的是一个能够在数百个GPU、CPU和NVMe内存规模的异构硬件上实现并行的系统,它能够使用无法在GPU内存中单独载入的大型模型实现高速推理。
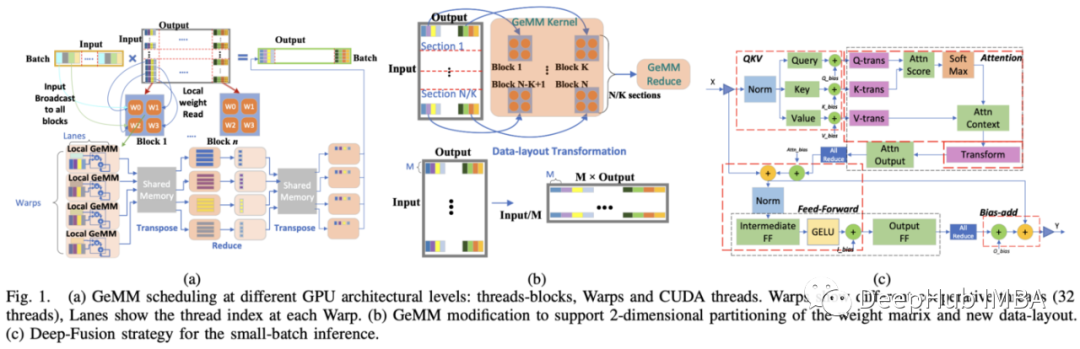
尽管大多数阅读这篇文章的人从来没有必要使用这样的框架来训练万亿规模的模型,但如果对训练和运行大规模神经网络工程感兴趣,可以看看这篇论文
5、Language Models (Mostly) Know What They Know
Saurav Kadavath et al.
https://arxiv.org/abs/2207.05221
性能远非ML模型唯一的指标。准确地知道他们对自己的输出的确定程度可能更重要,尤其是在以安全为重点的应用程序中。
Calibration 是机器学习中的概念,用于表明一个模型的预测置信度有多好(例如,一个具有90%确定性输出的完美校准模型应该是正确的9/10次,不少也不会不多)。
这项工作首先研究了lm回答问题的Calibration,假设一个单一的令牌是一个答案,概率可以直接从模型输出的可能性计算。
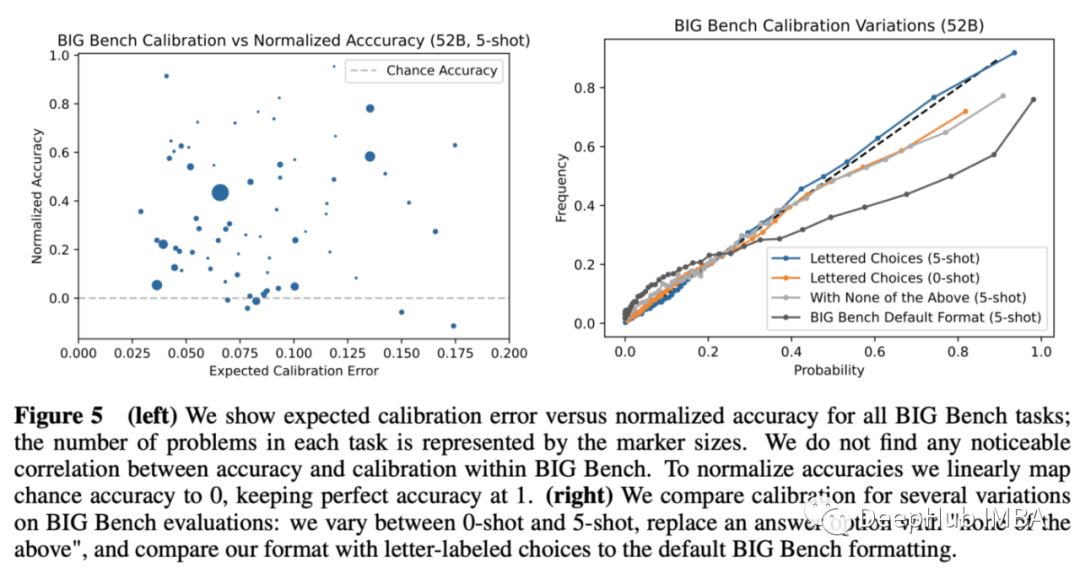
虽然lm对格式非常敏感,但只要给出适当的问题公式,大型lm就会得到很好的Calibration。有趣的是,这种能力在较小的范围内崩溃(见下图)。
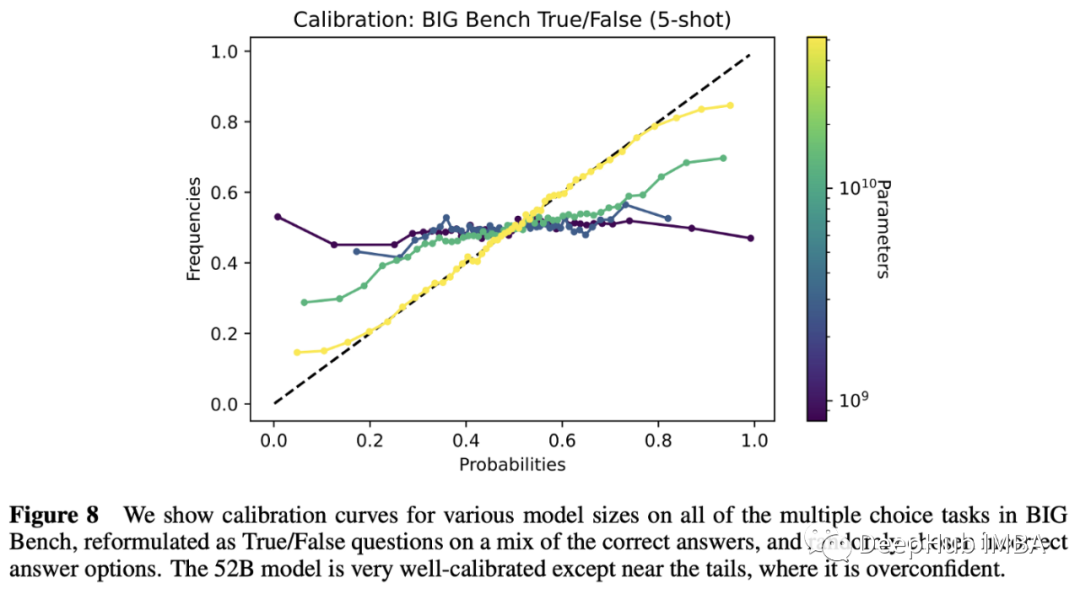
这篇论文深入探讨了更多的比较和分析模式,但结论仍然是:lm知道他们所知道的,但结果仍然很容易受到影响,而且模型需要足够大。
6、Towards Grand Unification of Object Tracking (Unicorn🦄)
Bin Yan, Yi Jiang, Peize Sun, Dong Wang, Zehuan Yuan, Ping Luo, Huchuan Lu.
https://arxiv.org/abs/2207.07078
在过去的几年中,整理和统一机器学习模型架构在NLP中被证明是卓有成效的,现在他已经延申到视频计算机视觉任务了。
当涉及到视频相关的任务时,现有的表现最好的模型仍然倾向于依赖于任务特定的设计,结果是过度专注于他们的特定应用程序。
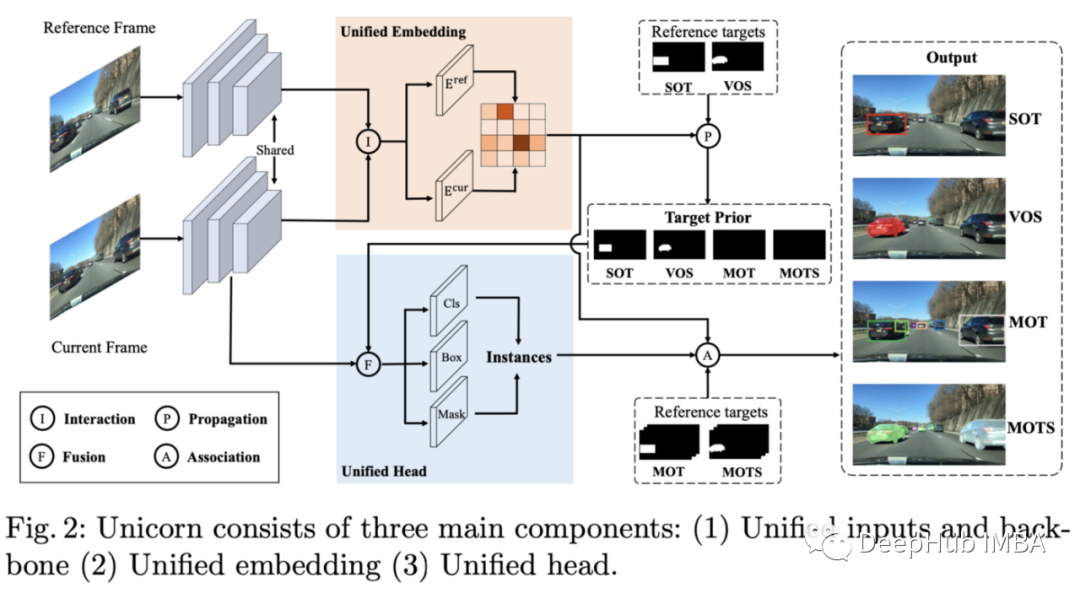
作者提出了一个单一的模型架构,在4种模式下进行目标跟踪:单目标跟踪(SOT),多目标跟踪(MOT),视频对象分割(VOS)和多目标跟踪和分割(MOTS)。
这个架构相当复杂,通过下面的图(也不一定能说清楚。。。)。在大致上,它从一个统一的主干嵌入图像开始,然后为参考帧和当前帧计算一个统一的嵌入。Transformer用于统一嵌入和当前帧之间的特征交互,输出对应于所有对象跟踪风格的类、框和掩码。
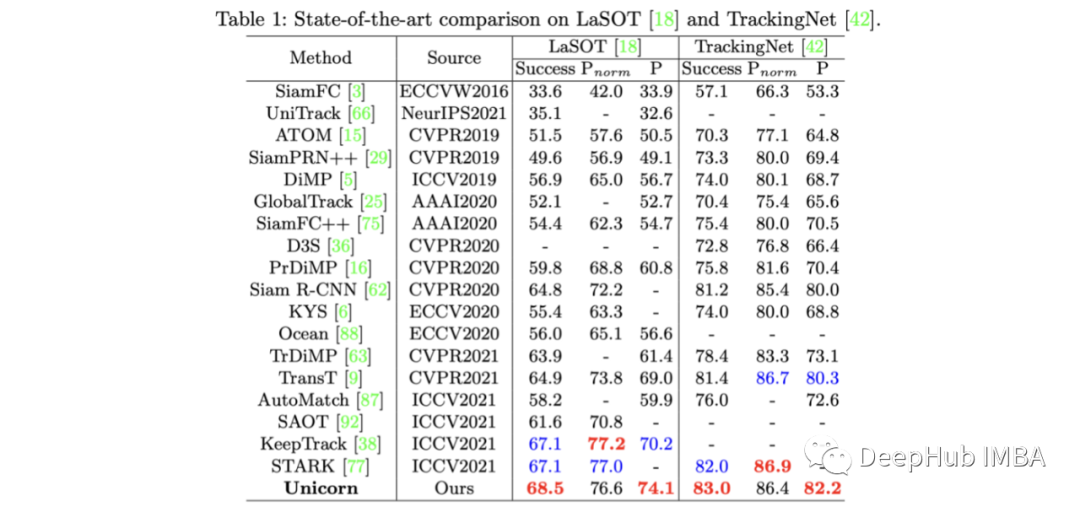
该系统在几个对象跟踪基准上进行了基准测试,如LaSOT、TrackingNet、MOT17、BDD100K(和其他),并在其中大多数上取得了最好的性能。
7、Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
Yi Tay, Mostafa Dehghani, Samira Abnar, Hyung Won Chung, William Fedus, Jinfeng Rao, Sharan Narang, Vinh Q. Tran, Dani Yogatama, Donald Metzler.
https://arxiv.org/abs/2207.10551
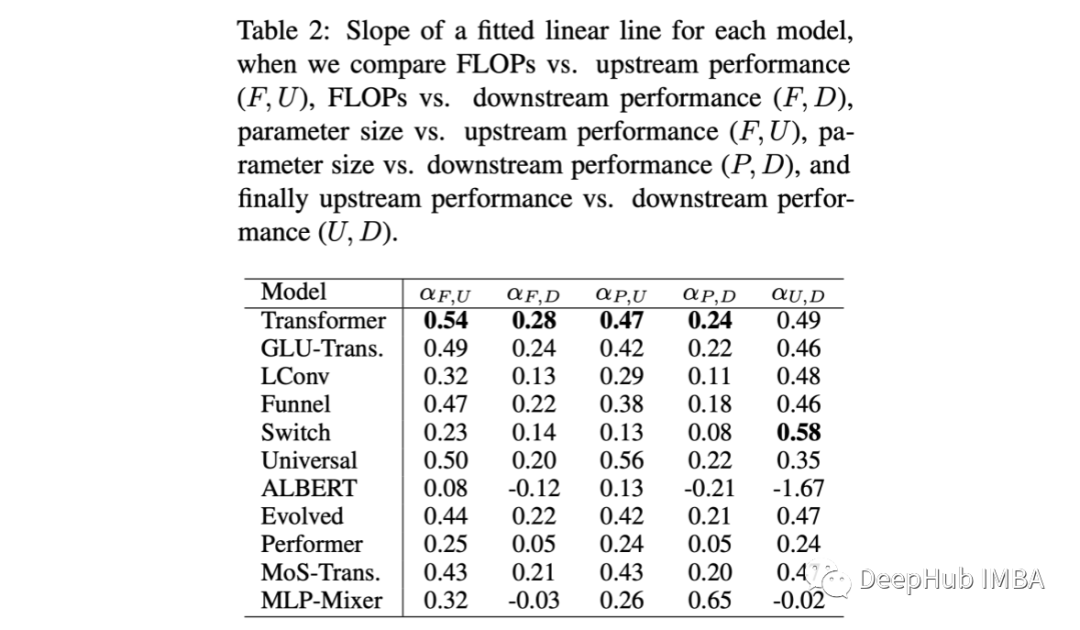
作者执行了数百个跨尺度的实验,广泛的架构包括经典的和改进的Transformers,MLP mixer,和基于卷积的模型。实验包括使用自回归语言建模进行预训练(上游性能),然后监督微调GLUE、SuperGLUE和SQuAD(下游性能)。
结果很简单。在所有缩放机制中,经典的Transformer都不是最佳选择,但它在不同缩放机制中显示了最健壮和一致的性能结果。
卷积和基于mlp的架构在预训练(上游性能)方面做得很好,但在微调时无法获得相应的性能。这就指出了架构归纳偏差在迁移学习中的重要性。
改进后的Transformers只有在一定的规模下才能与同类产品竞争,而且如果规模足够大,则会变差。
8、Discrete Key-Value Bottleneck
Frederik Träuble, Anirudh Goyal, Nasim Rahaman, Michael Mozer, Kenji Kawaguchi, Yoshua Bengio, Bernhard Schölkopf.
https://arxiv.org/abs/2207.11240
ML中的重点将慢慢转移到域外泛化,归纳偏差将变得更加相关。
将高维输入(例如,图像)编码为在大数据集中预先训练的编码器的嵌入。将嵌入分解为低维头部C,并从训练时被冻结的一组预定义向量中寻找最近邻。然后利用最近邻在头部上的表示来重建嵌入。解码器将重建的嵌入作为输入,并产生特定于任务的输出:
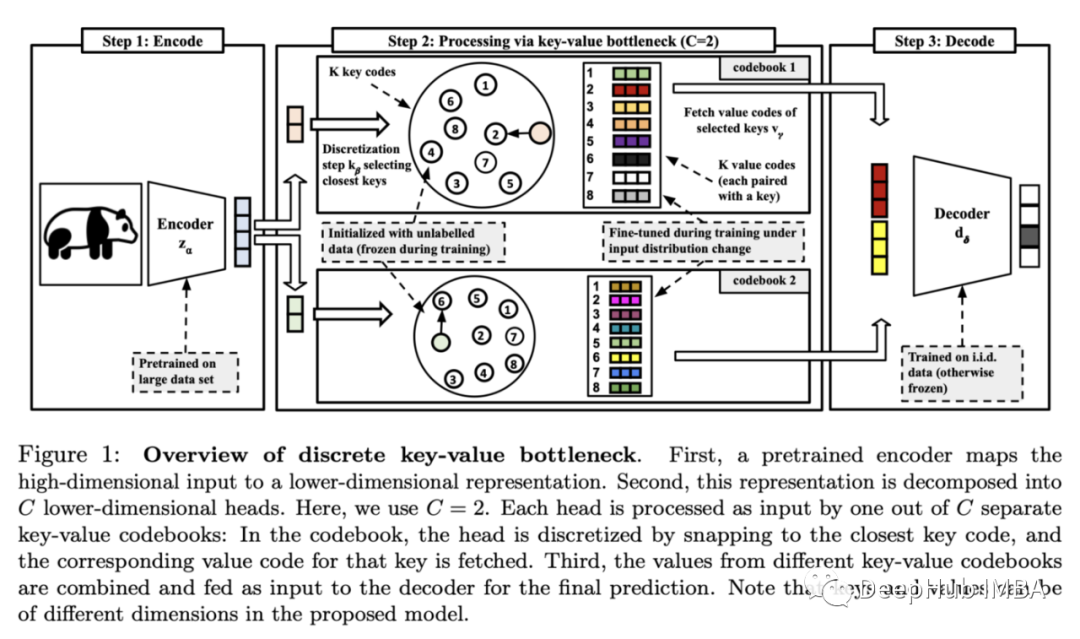
该实验集中在为一个分布的训练数据上进行训练的模型,适应另外一个新的分布,如下图所示。该模型是通过在I.I.D上进行训练来初始, 当使模型适应新的分布时,解码器被冻结,只更新codebook。
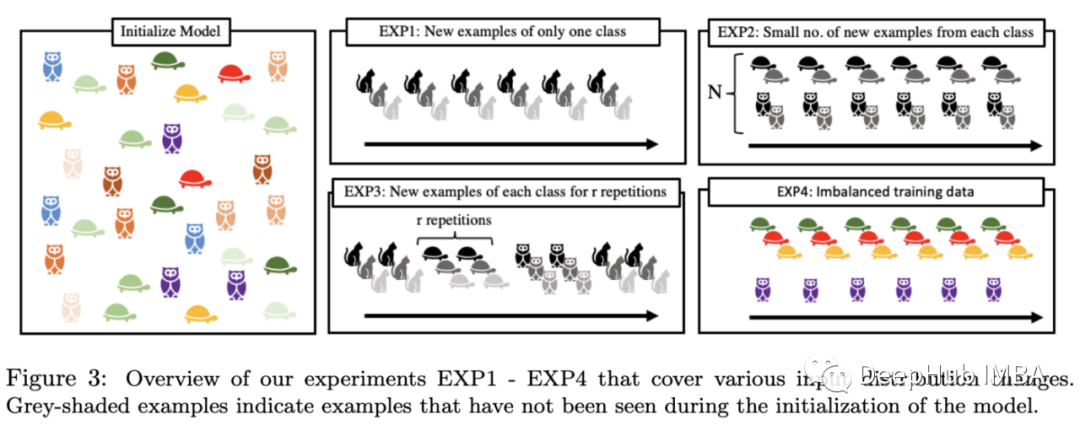
他们的实验证明了这种方法如何减少灾难性遗忘,并获得更稳健的预测。这项工作不会有很大的短期影响——结果不是开创性的——但其中一些想法可能是下一个飞跃的关键催化剂。
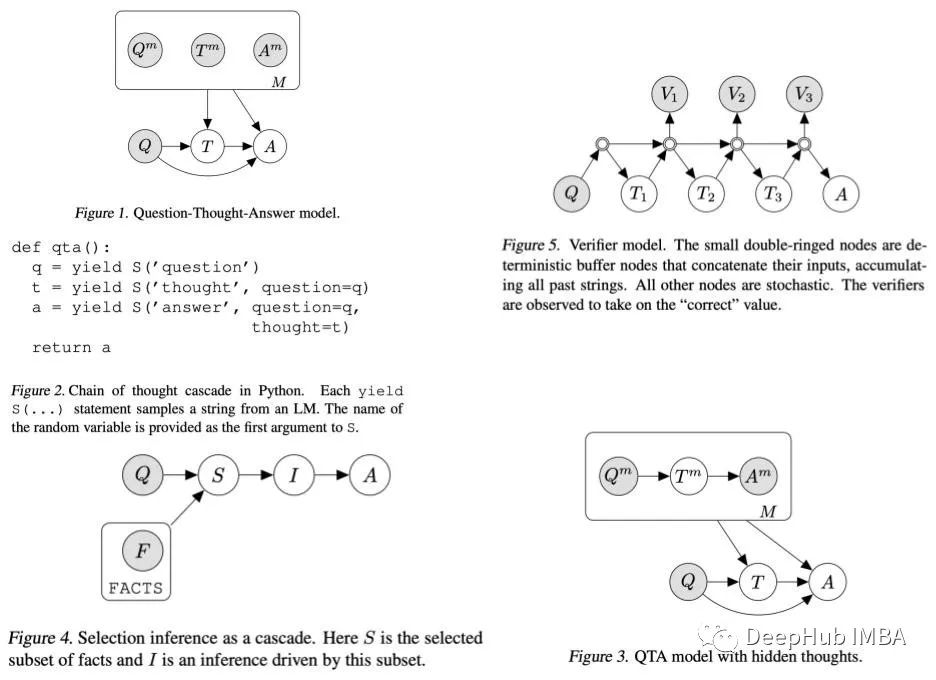
9、Language Model Cascades
David Dohan, Winnie Xu, Aitor Lewkowycz, Jacob Austin, David Bieber, Raphael Gontijo Lopes, Yuhuai Wu, Henryk Michalewski, Rif A. Saurous, Jascha Sohl-dickstein, Kevin Murphy, Charles Sutton.
https://arxiv.org/abs/2207.10342
大型语言模型已经变得很强大,它们越来越多地被用作其他应用(如强化学习或数据增强)的黑盒构建块。
这项工作从概率编程的角度形式化了语言模型的交互:随机变量的定向图模型,它映射到自然语言字符串。
10、ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
Tailin Wu, Megan Tjandrasuwita, Zhengxuan Wu, Xuelin Yang, Kevin Liu, Rok Sosič, Jure Leskovec.
https://arxiv.org/abs/2206.15049
ZeroC是一种将概念表示为组成模型的图方法。本文的主要目的是建立一个能够在推理时识别不可见概念的系统。例如在下面的图中,字母F没有被模型看到,但它能够解开它的组件(线)和它们的关系(角度和位置),将它们表示为一个包含3个节点和3条边的显式图
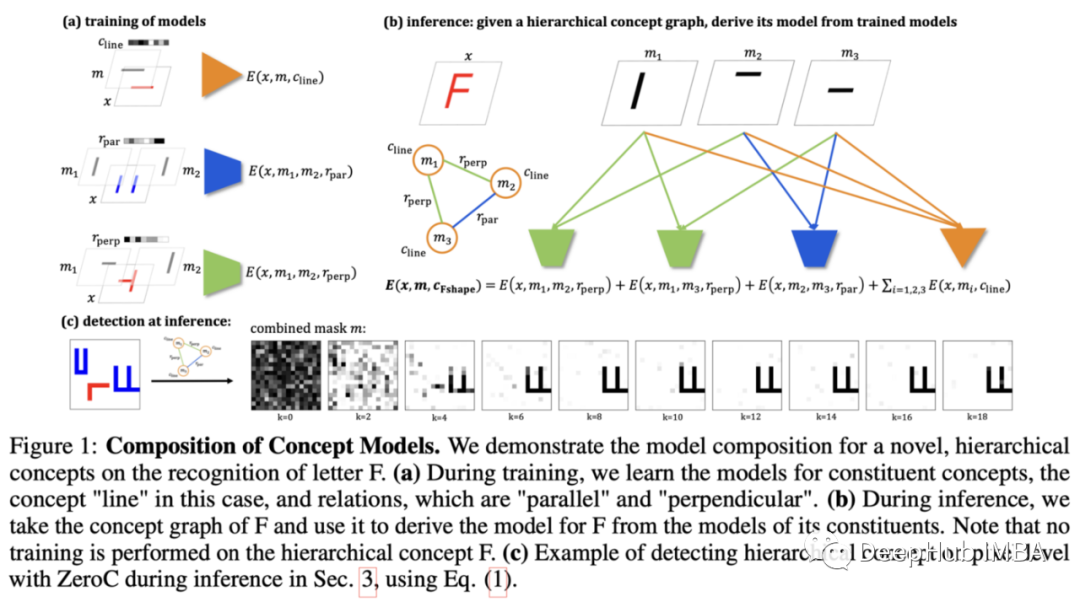
训练这样一个系统的方法依赖于基于能量的模型(EBMs):输入正图像/图表示对和负图像/图表示对,最小化正图像对的能量。实验表明,在基本形状和关系相当简单的环境中取得了成功,这代表了向学习结构丰富的表示迈出的第一步,在少样本学习和泛化的背景下,这可能会变得有用。
作者:Sergi Castella i Sapé