手把手教你深度学习和实战-----线性回归+梯度下降法
本文主要从基础的角度讲解线性回归算法和梯度下降算法,力求用通俗的语言和简单的例子进行算法的讲解。
手把手教你深度学习和实战-----逻辑回归算法
文本从基础的角度对逻辑回归进行了一个讲解,手动推导了逻辑回归的梯度下降法
使用Torchmetrics快速进行验证指标的计算
TorchMetrics可以为我们提供一种简单、干净、高效的方式来处理验证指标。TorchMetrics提供了许多现成的指标实现,如Accuracy, Dice, F1 Score, Recall, MAE等等,几乎最常见的指标都可以在里面找到。
Code For Better 谷歌开发者之声----谷歌云基于TensorFlow高级机器学习
谷歌云基于TensorFlow高级机器学习
一文读懂标量、向量、矩阵、张量的关系
然而,矩阵乘法的规则是,只有当第一列中的列数等于第二列中的行数时,两个矩阵才能相乘(即,内部维度相同,n为(m × n)) – 矩阵乘以(n × p)矩阵,得到(m × p)-矩阵。向量空间(也称为线性空间)是称为对象的集合的载体,其可被添加在一起,并乘以由数字(“缩放”),所谓的标量。用通俗的说法
深度学习之文本分类 ----FastText
使用FastText进行文本分类,文章解简单介绍FastText的基本介绍、使用方式,对应的数据格式,以及模型调优的方式
基于编辑距离纯逻辑实现相似地址聚类
香港公司发来的账单中,有很多相对的地址却使用的不同的派送方式采用了不同的收费,这部分数据明显存在问题需要与香港公司进行确认。上图中展示了一种极度简单的情况,只需要将文本所有空格去掉即可找出来,但是部分地址是仅仅差几个汉字字符仍然是相同的地址,为了最高的准确度我们使用编辑距离计算地址间的相似度更佳。这
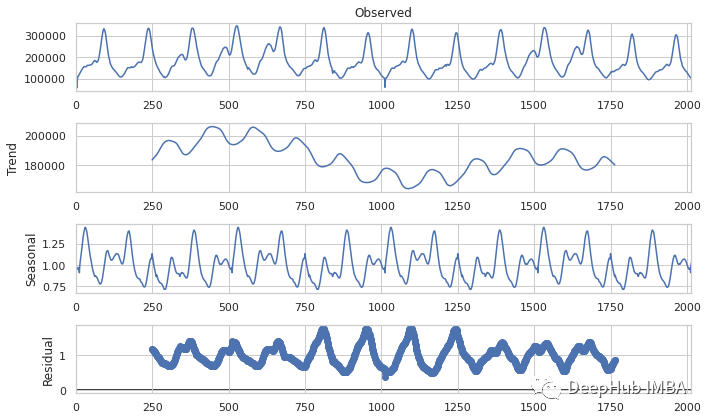
使用时间序列数据预测《Apex英雄》的玩家活跃数据
在本文中我们使用《Apex英雄》中数据分析的玩家活动时间模式,并预测其增长或下降。
猿创征文|【Python数据科学快速入门系列 | 05】常用科学计算函数
本文以鸢尾花的数据预处理为例,描述了科学计算在机器学习使用的示例。
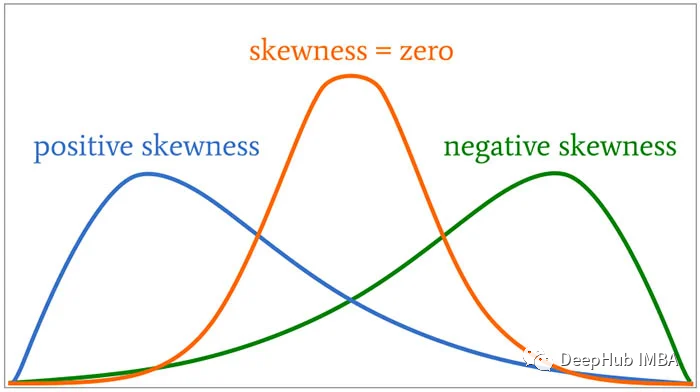
学习偏态分布的相关知识和原理的4篇论文推荐
偏态分布(skewness distribution)指频数分布的高峰位于一侧,尾部向另一侧延伸的分布。
文本特征提取专题_以python为工具【Python机器学习系列(十二)】
特征提取专题_以python为工具【Python机器学习系列(十二)】1.字典特征提取 DictVectorizer()1.1 one-hot编码1.2 字典数据转sparse矩阵2.英文文本特征提取3.中文文本特征提取4. TF-IDF 文本特征提取 TfidfVectorizer()......
猿创征文|Python-sklearn机器学习快速入门:你的第一个机器学习实战项目
从开始学习机器学习到现在已经有三年了,建模过程以及各类模型使用场景都有个大致的掌握。其中我感觉在我所有的机器学习文章中缺少一篇真正引人入门的文章。任何情况迈开学习的第一步都是比较困难的,学习的成本是很高的,相对你学会了收益也高。尤其是机器学习这种数学和逻辑能力强关联的学科,是比较难上手的事,但是当真
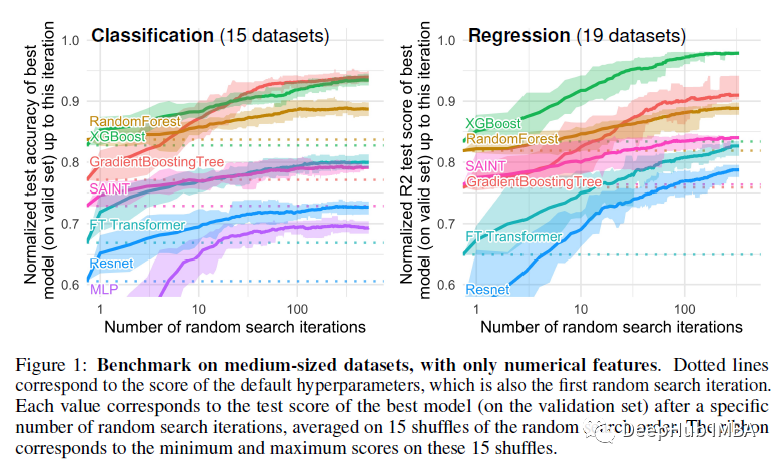
为什么基于树的模型在表格数据上仍然优于深度学习
在这篇文章中,将详细解释一个被世界各地的机器学习从业者在各种领域观察到的现象——基于树的模型在分析表格数据方面比深度学习/神经网络好得多。
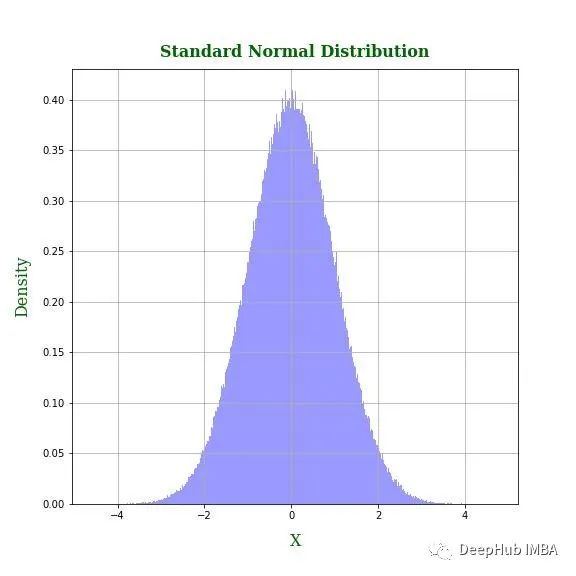
将特征转换为正态分布的一种方法示例
正态(高斯)分布在机器学习中起着核心作用,线性回归模型中要假设随机误差等方差并且服从正态分布,如果变量服从正态分布,那么更容易建立理论结果。
python numpy(二)
numpy索引 高级索引 布尔索引
Python ML实战-工业蒸汽量预测01-赛题理解
python机器学习实战阿里云天池大赛 工业蒸汽量预测
【NLP】一文了解词性标注CRF模型
NLP 自然语言之一文了解词性标注CRF模型
西瓜书第四章阅读笔记
Datawhale小组打卡学习,西瓜书第四章决策树部分学习笔记
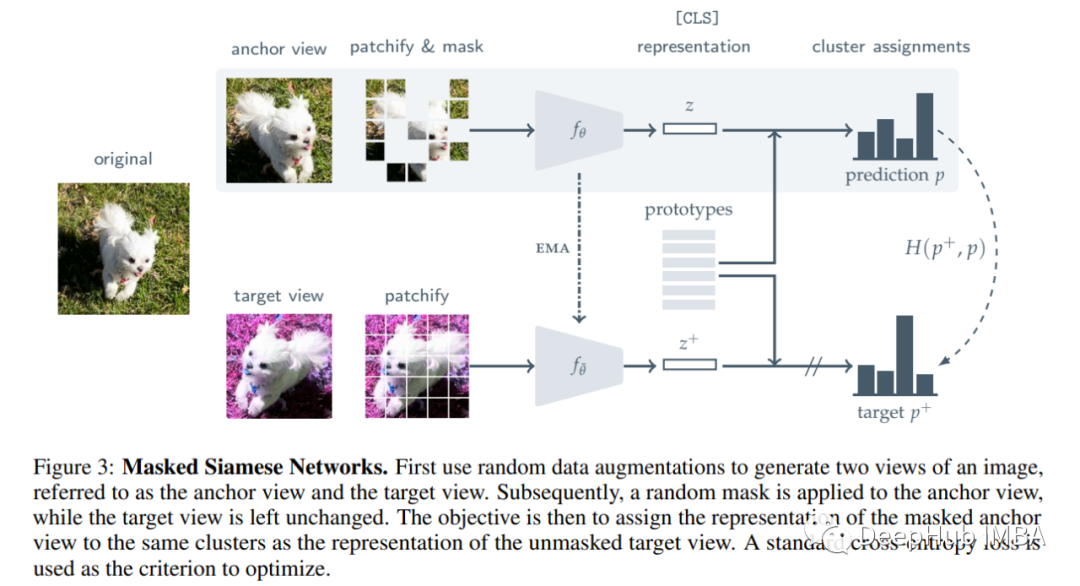
论文推荐:使用带掩码的孪生网络进行自监督学习
本篇文章将介绍Masked Siamese Networks (MSN),这是另一种用于学习图像表示的自监督学习框架。MSN 在 ImageNet-1K 上的线性评估方面优于 MAE 和其他模型
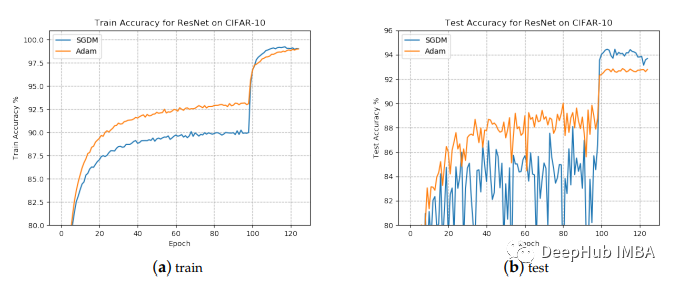
为什么Adam 不是默认的优化算法?
本文这并不是否定自适应梯度方法在神经网络框架中的学习参数的贡献。而是希望能够在使用Adam的同时实验SGD和其他非自适应梯度方法



