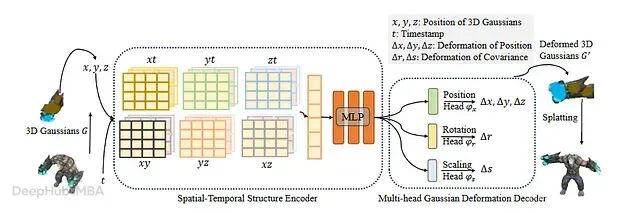
4D Gaussian Splatting 是怎么工作的:从规范 Gaussian 到形变场的原理拆解
4D-GS 靠合适的因子分解和几个关键约束,显式表示照样能搞定时间维度,而不用牺牲让它一开始就站住脚的实时性能。
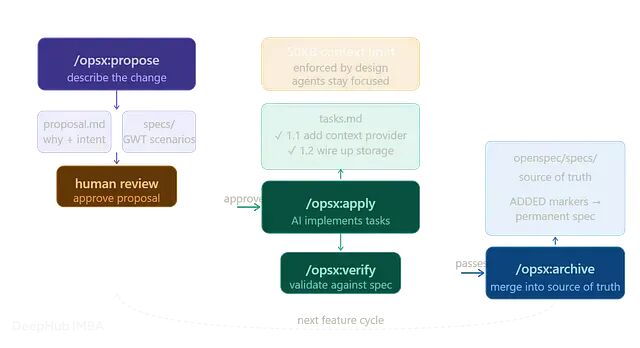
OpenSpec 三阶段工作流实操:从 Propose 到 Archive让代码返工率降到三分之一以下
这一篇讲的是 OpenSpec 在单一仓库内如何落地:一个 agent,一份代码库,三个阶段走完一个功能。
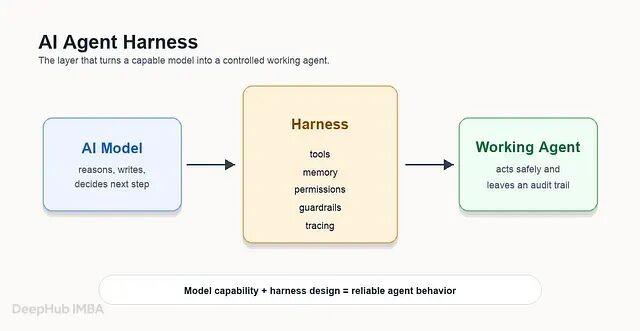
Agent Harness 到底是什么:模型之外的那层控制系统
Agent Harness 把模型的能力转化为可依赖的行为,给智能体提供工具、记忆、权限、护栏、可观测性和恢复机制。
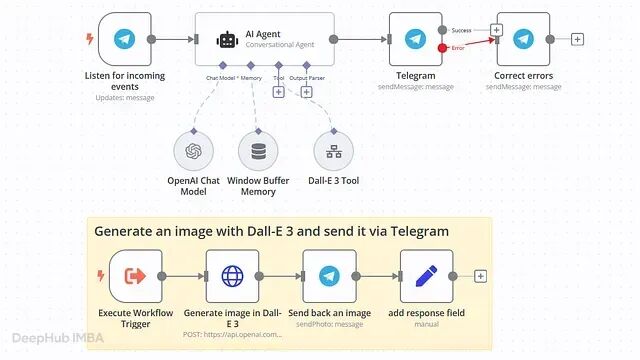
十个 AI Agent 工作流模板,照着搭就能用
AI agent 比聊天机器人更有用的地方是聊天机器人只负责回答;而agent 会完成一整条工作
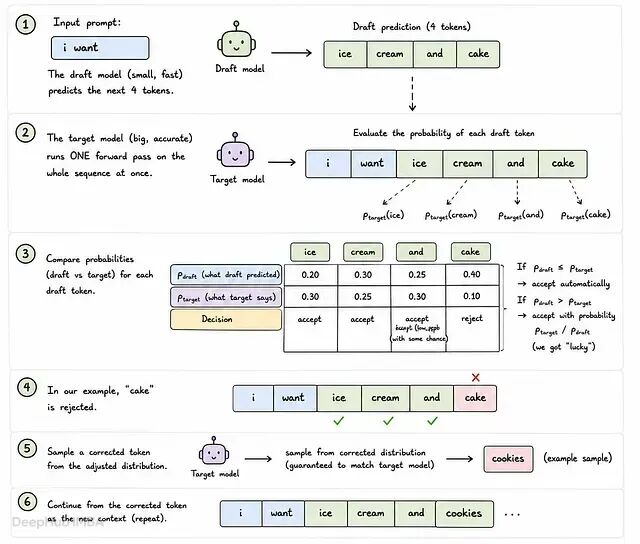
白得 2 到 3 倍加速的投机采样机制解析:草稿模型和目标模型是怎么配合的
投机采样的精妙之处在于:不改模型、不动训练、不碰权重,纯粹是利用了"验证比生成便宜"这个事实

Harness Engineering 实践案例:如何Agent 写一份行为规范
OpenAI 的 Ryan Lopopolo 那发布了一篇关于Harness 的官方文章,我们来用手头的一个任务来测试下效果怎么样。
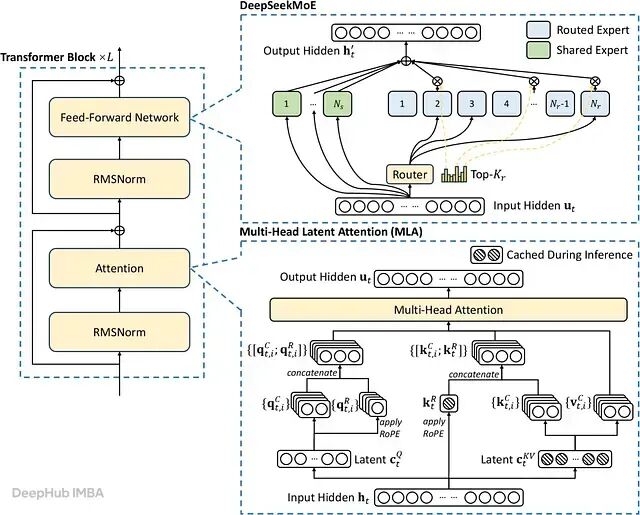
注意力架构变迁总结:稀疏、线性、SSM、混合架构如何摆脱 O(L²) 的代价
本文将介绍四条路线的原理、经过验证的基准测试数据,以及各自目前的生产落地情况。
Polars vs Pandas 在生产 Pipeline 中的对比
Pandas 不是遗留技术,它是精准的专用工具;Polars 是另一种工作的精准专用工具。为每项工作选择合适的,不是迁移项目,是工程判断力。

UV vs pip vs Conda:Python环境管理应该怎么选
对于任何在意可维护性和可重现性的项目,请选择 uv。
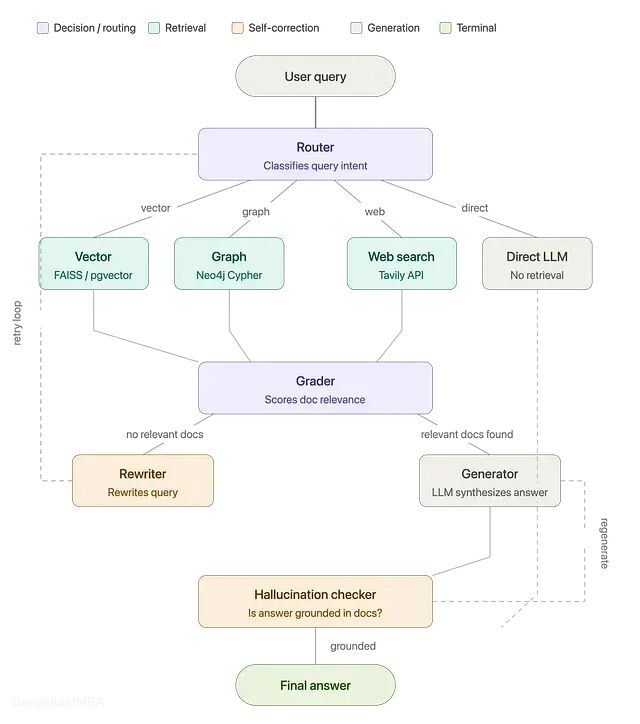
用 LangGraph 改造单一 RAG 架构:让 Agent 决定调用向量、图遍历还是网络搜索
向量搜索、图遍历还是网络搜索 -- 本文介绍如何用 LangGraph 让智能体为每个问题选择合适的工具。
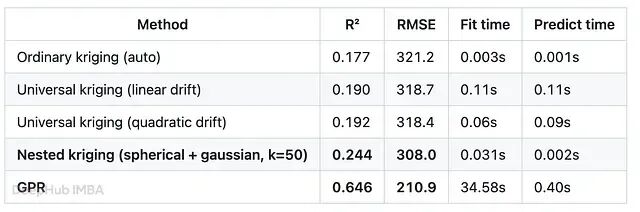
为什么Kriging 与高斯过程回归出自同一数学框架,但实际效果却差很远
本文将在 SPE9 数据集上跑了一套正面对比,覆盖多种 Kriging 变体、GPR 以及几个 ML 基线,还包括用 5 折和 20 折交叉验证重复了一遍,看稳定性。
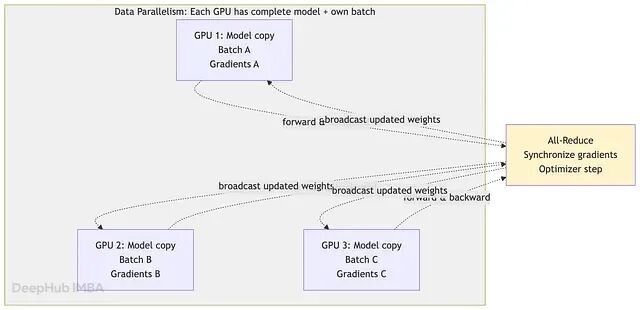
百亿参数模型的并行训练:节点内张量并行、节点间数据并行
瓶颈不在于数据移动的速度,而在于内存里能存多少、以及在移动数据的同时能让 GPU 保持多忙

DiffusionGemma:用离散文本扩散和双向注意力,把推理瓶颈从内存带宽转移到算力
DiffusionGemma 则是离散文本扩散(discrete text diffusion)的实验性模型,可以同时生成并精炼整个文本块,绕过了历史上制约本地 AI 性能的主要硬件瓶颈。
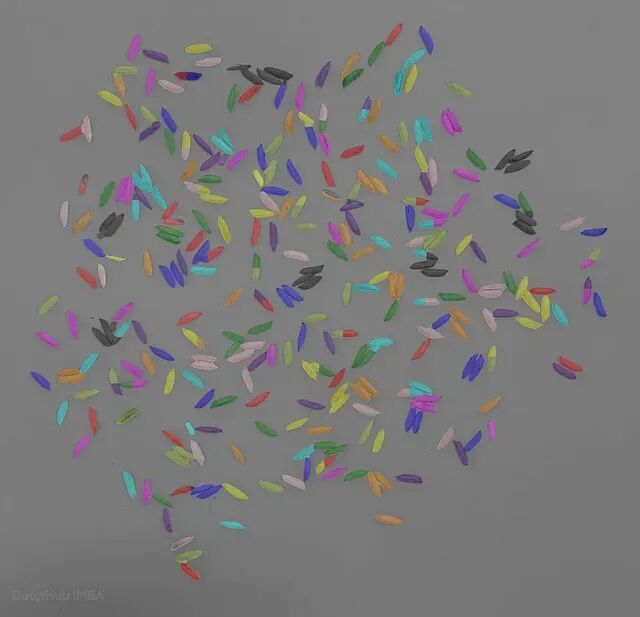
微调LocateAnything-3B 实现超高密度的目标检测
微调LocateAnything-3B,实现当图像中有 300+ 个密集重叠目标、人工标注不可行时的实用方案。
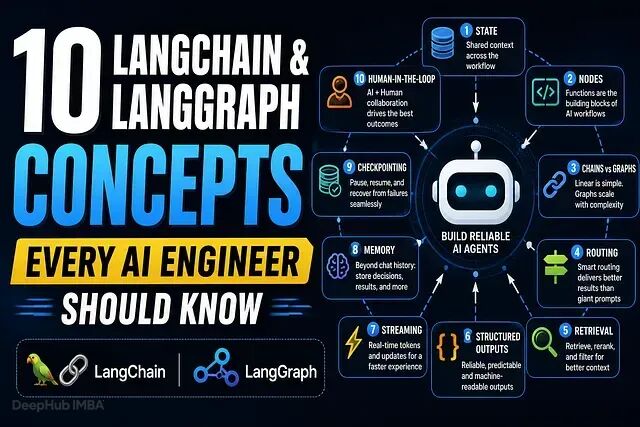
10 个 AI 工程师必须掌握的 LangChain & LangGraph 概念
但是应用需要检索文档、调用工具、处理故障、路由请求、记住历史操作,还要在关键决策节点引入人工审核。这时这个聊天机器人已经变成了一套工作流。

Flash-KMeans:快速且内存高效的精确 K-Means,可在单张 GPU 进行亿级数据的聚类
本文介绍 Flash-KMeans是一个近期提出的框架,它受 Flash(最小化数据移动)的启发,论文给出了一种执行精确 K-Means 的方案,速度更快内存效率也远优于 FAISS 等行业标准实现
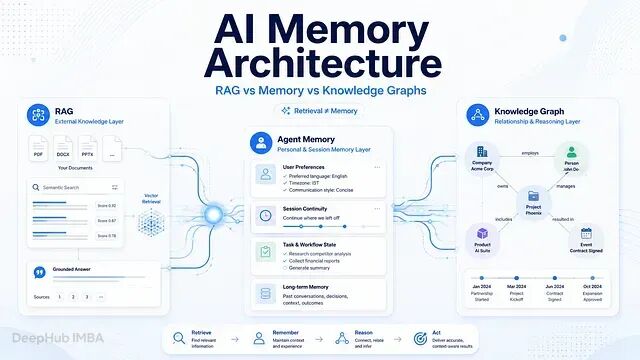
AI Agent的三重记忆机制:打造高可用的多维记忆系统
本文是一份实用指南,帮助你选择合适的记忆层。
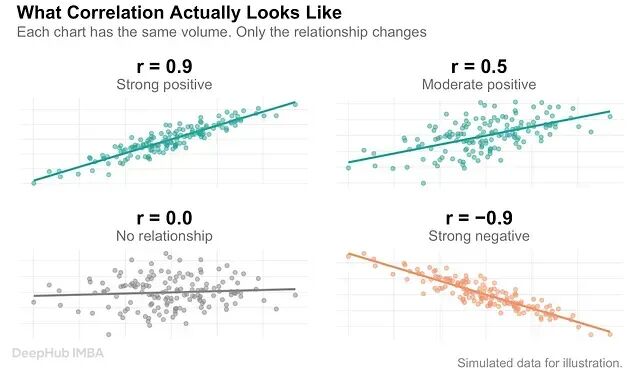
相关性与因果性:识别伪相关以提升模型在真实环境的可用性
相关性表示两个指标存在同步变动趋势,因果性则代表一件事直接促成了另一件事。两者之间有着一道需要用严谨论证来填补的鸿沟。测算相关性毫无门槛但是证明因果关系却极度困难。

2026 年开源 Agent 工具包选型指南:延迟、审计、可移植性与语言栈
2026 年用于构建 agent 的开源工具包已经已经得到了巨大的发展,所以本篇文章将从以下角度来帮助你如何选择最适合你的工具:延迟预算、审计追踪、模型可移植性、还是语言栈。



