
UV vs pip vs Conda:Python环境管理应该怎么选
对于任何在意可维护性和可重现性的项目,请选择 uv。

2026 年开源 Agent 工具包选型指南:延迟、审计、可移植性与语言栈
2026 年用于构建 agent 的开源工具包已经已经得到了巨大的发展,所以本篇文章将从以下角度来帮助你如何选择最适合你的工具:延迟预算、审计追踪、模型可移植性、还是语言栈。
Pydantic v2 入门教程:模型、字段、验证器
本问将覆盖 API 的每个核心部分:定义模型、约束字段、写验证器、组合嵌套结构、控制序列化。所有示例基于 **Pydantic v2** 和 **Python 3.10+**,每个清单完整可运行。
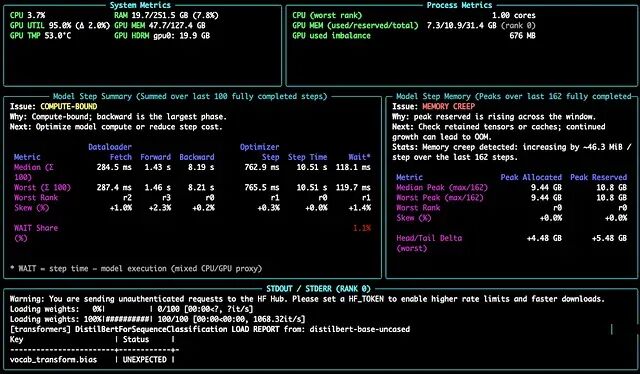
TraceML:用三行代码为训练循环加入 step 级诊断
TraceML 是开源的目前支持单 GPU 以及单节点 DDP/FSDP;多节点支持很快会推出。

让机器学习 Pipeline 更稳的 5 个 Python 装饰器代码
下面介绍 5 个适合现代 AI 开发流程的 Python 装饰器。
Feature Engineering 实战:Pandas + Scikit-learn的机器学习特征工程的完整代码示例
Feature engineering 是机器学习 pipeline 里最关键的一环。
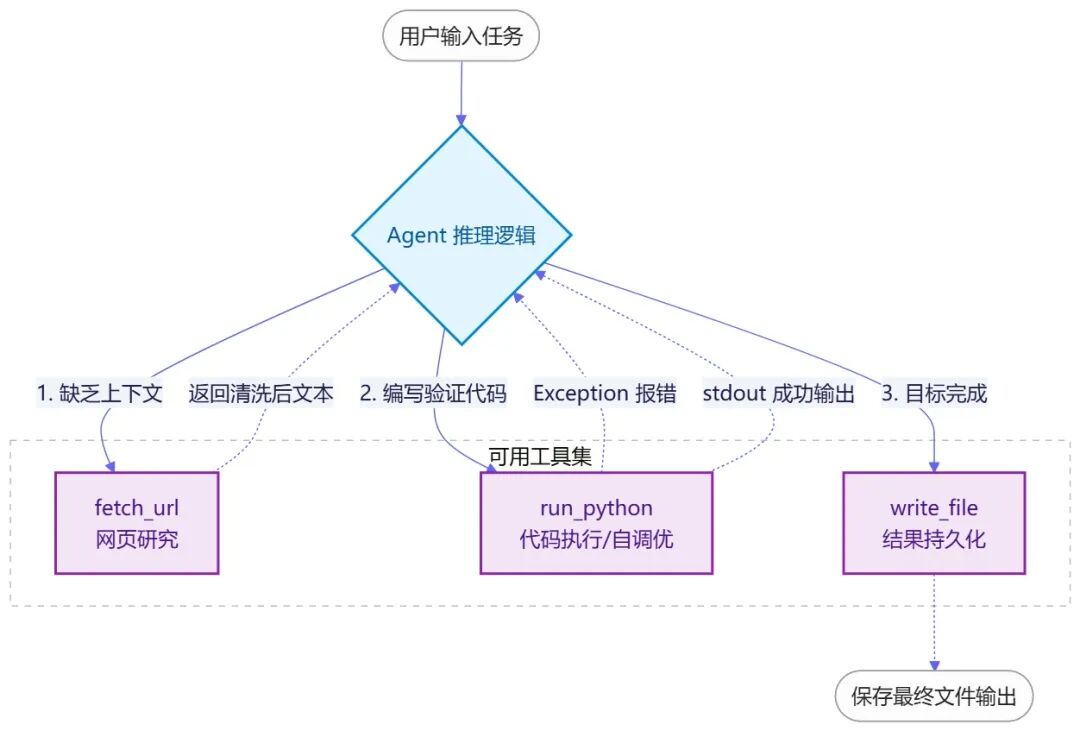
三个工具,让 agent 在一次对话里完成研究、写码、调试与保存
其实只要有三个工具就能把 agent 从聊天机器人变成能干活的东西
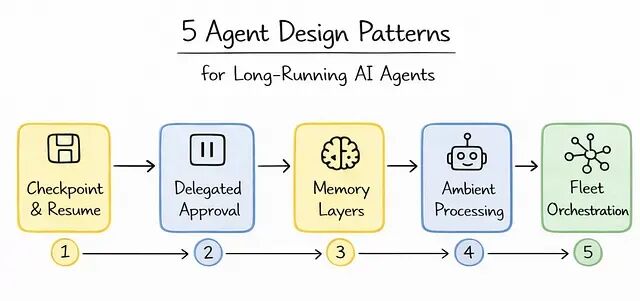
从无状态到有状态:长时运行 Agent 的 5 种架构模式
生产级 AI 不是单轮里把 agent 调得多聪明,而是看它能否在很多轮、很多天、很多次交接之间保持可靠。
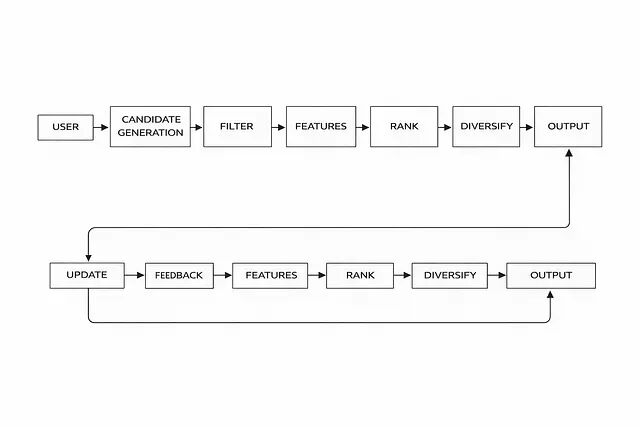
拆解推荐系统:候选生成、过滤、排序、多样性的分层设计
本文梳理一条可以实际构建并持续扩展的端到端推荐 Pipeline。

向量数据库对比:Pinecone、Chroma、Weaviate 的架构与适用场景
本文对比三个主流方案,每个都附有 Python 代码,均来自实际在生产环境中使用三者的经验。
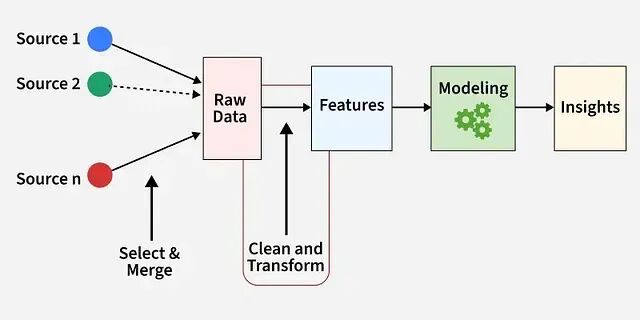
机器学习特征工程:缩放、编码、聚合、嵌入与自动化
好模型的秘诀不在于更花哨的算法,而在于更好的特征。

ADK 多智能体编排:SequentialAgent、ParallelAgent 与 LoopAgent 解析
本文讲介绍每种模式的适用场景、状态的流转机制,以及如何在不编写编排逻辑的前提下搭建一条完整的从订单到交付的流水线。

10个内置在 Pandas 中却常被忽略的向量化操作
本文整理了10个这样的写法,每个都附带常见的冗长版本作为对照。

10个内置在 Pandas 中却常被忽略的向量化操作
本文整理了10个这样的写法,每个都附带常见的冗长版本作为对照。
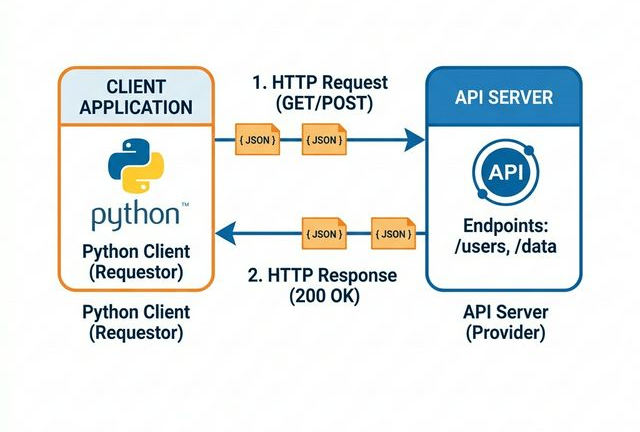
腾讯微信OpenClaw插件API通信过程剖析与Python原生代码复刻原理
本文将介绍如何不装 OpenClaw,直接把协议扒出来,并用 Python 复刻 。
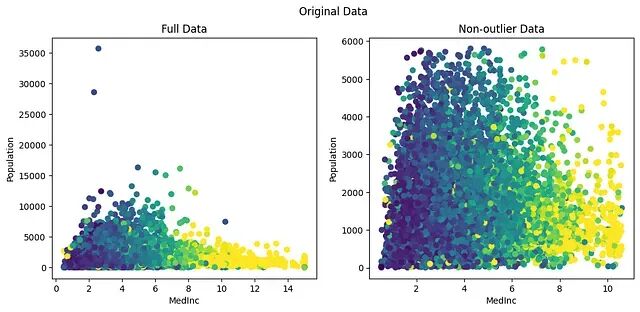
数值特征工程中的四种缩放方法:原理、适用场景与局限性
数值特征工程是机器学习模型训练中不可跳过的预处理环节。处理数值数据时需要面对两个核心问题:特征的量级差异和异常值。

9个提升Python代码生产质量的第三方库
这9个库覆盖了日常开发中几个反复出现的痛点:嵌套数据访问、标准库功能缺失、运行时类型安全、错误处理模式、时区陷阱、性能分析、测试断言、重试机制和数据管道。
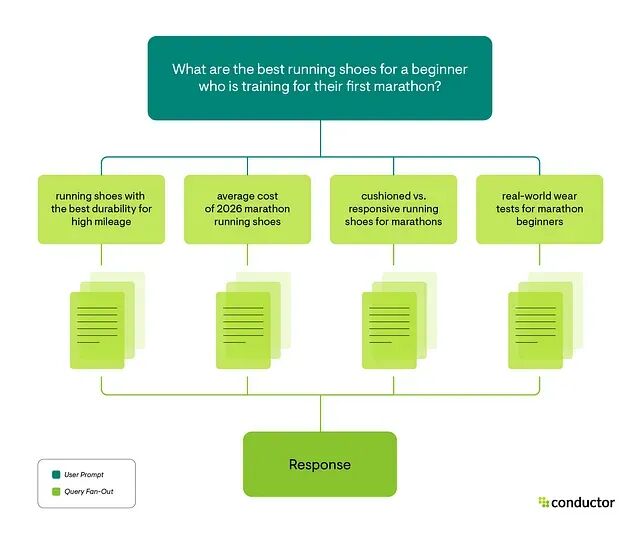
高级 RAG 技术:查询转换与查询分解
基础 RAG 的准确性受制于查询质量,查询模糊、表述不当,或者用户对问题的抽象层次把握不准,检索结果就会出偏差,LLM 拿到的上下文也跟着失真。
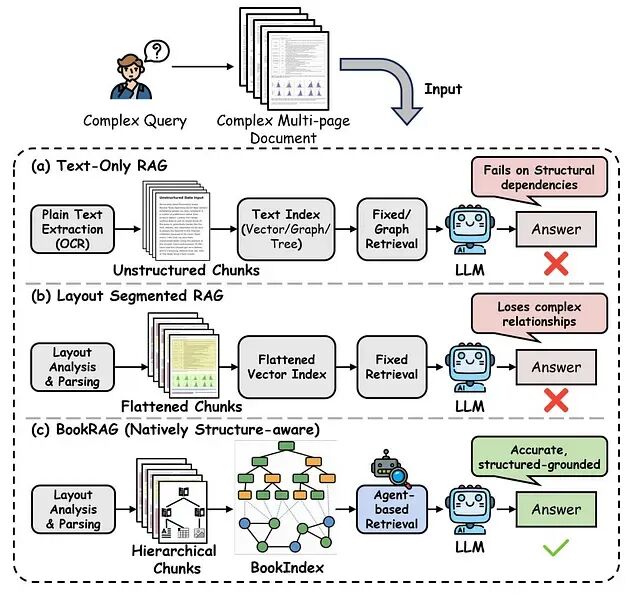
BookRAG:面向层级文档的树-图融合RAG框架
本文介绍的BookRAG或许能提供一个有用的视角。

Python标准库里藏着的7个代码简化利器
开始使用它们之后,项目体积缩小了,维护成本降低了,自动化也顺畅得多。以下是改变一切的七个技巧。



