Pytorch 常见运算(mul、mm、dot、mv)
Pytorch 常见运算1.矩阵与标量2.哈达玛积(mul)3.矩阵乘法4.幂与开方5.对数运算6.近似值运算7.剪裁运算1.矩阵与标量矩阵(张量)每一个元素与标量进行操作。import torcha = torch.tensor([1,2])print(a+1)>>> tenso
机器学习教程前言
机器学习教程前言该机器学习教程将从最基本的概率论开始,逐步深入的讲解机器学习的有关数学理论以及相关的一些实际的应用。
TensorFlow2 入门指南 | 14 网络模型的装配、训练与评估
本专栏在保证内容完整性的基础上,力求简洁,旨在让初学者能够更快地、高效地入门TensorFlow2 深度学习框架!

Pokémon AI,使用DALL-E生成神奇宝贝图鉴
还记得我们上次分享的使用DALL-E生成神奇宝贝的文章吗,这次Reddit的网友又给出了效果更好的版本。
R语言使用t.test函数计算两组独立数据的t检验(Independent t-test)
R语言使用t.test函数计算两组独立数据的t检验(Independent t-test)
浅谈股价预测模型(二):全能大明星——神经网络模型
本文主要讨论将神经网络的理念运用在股价预测或估值上
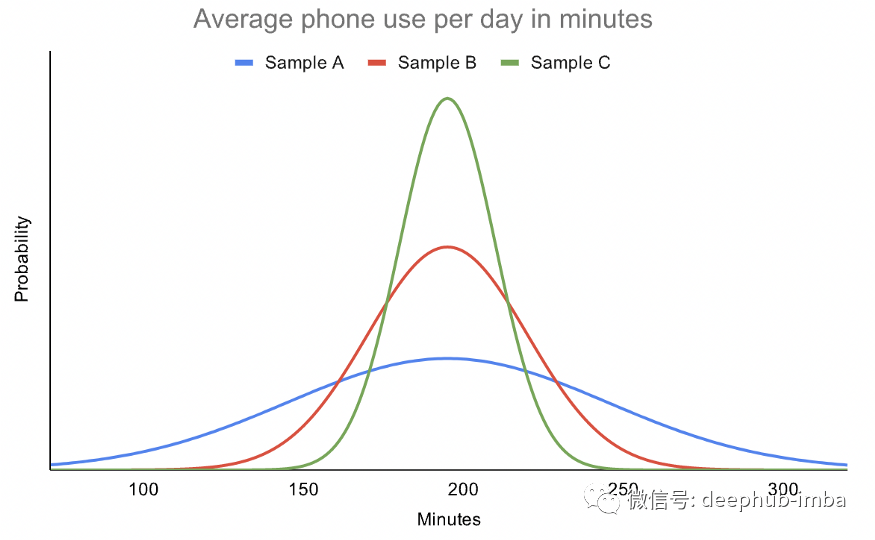
数据变异性的度量 - 极差、IQR、方差和标准偏差
variability被称作变异性或者可变性,它描述了数据点彼此之间以及距分布中心的距离。它告诉你点是倾向于聚集在中心周围还是更广泛地分散。
2022年除了深度学习,人工智能算法有可能突破的10个方向
千脑理论、自由能原理、Tstelin 机器、层级实时存储算法、脉冲神经网络、联想记忆 / 预测编码、分形人工智能、超维计算、双曲机器学习、复值神经网络
多元线性回归模型的各种诊断
多元线性回归模型的各种诊断(没有原理,只有代码、运行结果和部分结果解读)
【一起入门NLP】中科院自然语言处理期末考试*总复习*:考前押题+考后题目回忆
明天期末考试,胡玥老师亲自出题,整理一下我觉得最最最重点的地方押押题????????目录题型第三章:深度学习基础第四章:语言模型+词向量第五章:注意力机制第六章:NLP基础任务第七章:预训练语言模型题型填空题 1分x20个简答题 7分x6个综合题 38分计算题:维特比算法设计题第三章:深度学习基础?
我有一个朋友仅用了30min就搞清楚了冯诺依曼体系结构
冯诺依曼体系结构1、冯诺依曼人物简介2、冯诺依曼体系结构发展背景3、冯诺依曼体系结构4、冯诺依曼体系结构分析5、冯诺依曼体系实际应用(QQ通信)6、总结1、冯诺依曼人物简介 约翰·冯·诺依曼(John von Neumann,1903年12月28日-1957年2月8日),美籍匈牙利数学家、计算机科
最简单的人脸检测(免费调用百度AI开放平台接口)
远程调用百度AI开放平台的web服务,快速完成人脸识别
Matplotlib进行数据可视化的快速上手指南
Python 有许多可视化库用于制作静态或动态图。在本教程中,我将尽力帮助你理解 matplotlib 逻辑。
2021年总结,2022我来了。。。
之前一直没有想好总结该怎么写,元旦假期就在我犹豫的时候,不管不顾的来了。在元旦期间,我除了研究一个项目外,还追了一部电视剧《输赢》。虽然是个讲销售的爱情剧,但里面还是有不少引人思考的东西。什么是输?什么是赢?怎么算输?怎么又算赢呢?回想整个2021年,我陷入了沉思。
pandas这么多实用又常用的技能,还不快快收藏起来
自从我整理完这两篇关于pandas的博文之后,我从博文的阅读以及收藏的数据中不难得知,大家对于这类实用性的博文的认可,同时我自己在工作中有时也会发现,即使我整理了这么多有关于pandas的内容,但或多或少还是会遗漏一些知识点,毕竟pandas实在是太多实用的功能了。那么今天这篇博文呢,我进一步整理了
Python 大白的课题报告:OpenCV 抠图项目实战(1)
本系列是 Python 小白的课题作业《基于OpenCV 的图像分割和抠图》。需要说明的是,本系列并不能算是 OpenCV 的抠图项目教程,只是以此为主题的课题报告。其中包括了一个较为完整的 PyQt 项目介绍和例程。从学生课题作业报告的角度,还是可以晒出来给大家参考的。
python使用列表推导式(list comprehension)和itertools生成浮点数列表
python使用列表推导式(list comprehension)和itertools生成浮点数列表目录python使用列表推导式(list comprehension)和itertools生成浮点数列表#使用列表推导式(list comprehension)生成浮点数列表#itertools生成浮
神经网络学习小记录66——Vision Transformer(VIT)模型的复现详解
神经网络学习小记录66——Vision Transformer(VIT)模型的复现详解学习前言什么是Vision Transformer(VIT)代码下载Vision Transforme的实现思路一、整体结构解析二、网络结构解析1、特征提取部分介绍a、Patch+Position Embeddin
一文速览-数据分析基本思维以及方法
前言数据分析个人认为可以算是逻辑思维的分流强化型应用,了解了逻辑和基本思维方法其他方法基本大同小异,有些许其区别。个人最近有些空闲时光正好抓紧学习一波数据分析基本思维做建模的时候好思维逻辑清晰。本文仅供参考。提示:以下是本篇文章正文内容,下面案例可供参考一、数据分析的基本概念数据分析是指用适当的统计
EE4408: Machine Learning:
#########update to Lec 10##########################目录EE4408: Machine Learning:Lecture1Types of machine learningProbability ReviewLecture 2Graphical Mo



