
最近我在自己训练的墙体检测的网络中添加了自注意力,这提高了墙分割的dice分数。我写这篇短文是为了总结cnn的自注意力机制,主要是为了以后可以回顾一下我做了什么,但我也希望对你们有用。
为什么Self-Attention
这篇文章描述了CNN的自注意力。对于这种自注意力机制,它可以在而不增加计算成本的情况下增加感受野。
它是如何工作的
对前一隐含层的特征进行重塑,使之:

其中,C是通道的数量,N是所有其他维度的乘积(稍后我们将看到代码)
对x进行1x1卷积,得到f, g, h。这将改变通道的数量从C到C*:


计算f(x)和g(x)中像素位置之间的一系列softmax权重:
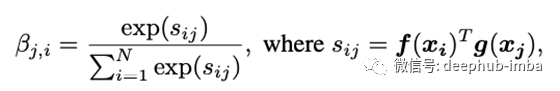
这些权重称为“注意力图”,本质上是量化图像中像素j相对于像素i的“重要性”。由于这些权重(β)是在特征集的整个高度和宽度上计算的,因此接收场不再局限于小内核的大小。
将自我注意层的输出计算为:

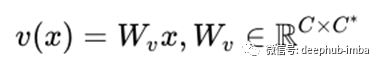
这里,v是另一个1x1卷积的输出。请注意,输出的通道数量与自关注的输入相同。
这是论文中的一张图,这些图将这些操作可视化了
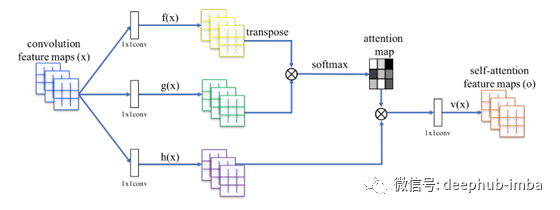
通常,我们设置:C * = C / 8。
作为最后一步,我们将输入特征x添加到输出的加权中(gamma是另一个可学习的标量参数):

使用pytorch的实现
以下简短有效的实现方法来自Fast.ai
class SelfAttention(Module):
"Self attention layer for `n_channels`."
def __init__(self, n_channels):
self.query,self.key,self.value = [self._conv(n_channels, c) for c in (n_channels//8,n_channels//8,n_channels)]
self.gamma = nn.Parameter(tensor([0.]))
def _conv(self,n_in,n_out):
return ConvLayer(n_in, n_out, ks=1, ndim=1, norm_type=NormType.Spectral, act_cls=None, bias=False)
def forward(self, x):
#Notation from the paper.
size = x.size()
x = x.view(*size[:2],-1)
f,g,h = self.query(x),self.key(x),self.value(x)
beta = F.softmax(torch.bmm(f.transpose(1,2), g), dim=1)
o = self.gamma * torch.bmm(h, beta) + x
return o.view(*size).contiguous()
第4行:定义三个1x1转换层来创建f(x),g(x),h(x)。这些通常称为查询,键和值(请参见第14行)
第13行:重塑为C x N大小的张量。
第15行:按照上述定义计算softmax注意权重(“ bmm”是pytorch的批矩阵乘法)。
第17行:恢复特征的原始形状
此实现与本文中描述的算法有所不同(但等效),因为它将1x1卷积v(x)和h(x)组合在一起,并且调用为h(x)或“值”。组合的1x1转换层具有C个输入通道和C个输出通道。此实现与本文中的算法等效,因为学习两个1x1转换层等效于学习一个具有兼容大小的转换层。
结果测试
通过在UNet块中替换conv层,我在UNet体系结构中使用了自注意力层。自我注意层的引入提高了用于分割墙壁的DICE得分。这是“ Wall Color AI”应用程序中的一个示例:
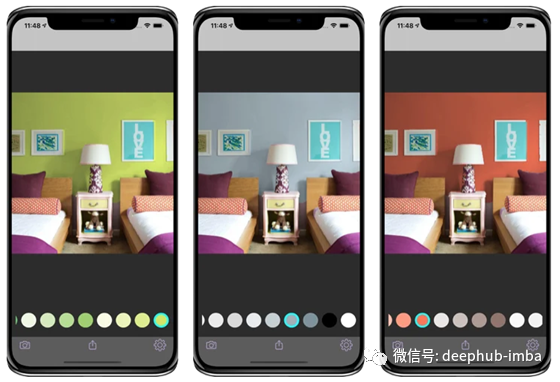
作者:Ramin
原文地址:https://maadotaa.medium.com/self-attention-in-convolutional-neural-networks-172d947afc00
deephub翻译组