
在越来越多的领域中机器学习模型已开始需要更高的标准, 例如模型预测中公司需要对模型产生的任何虚假预测负责。有了这种转变,可以说模型的可解释性已经比预测能力具有更高的优先级。 诸如准确率和R2分数之类的指标已经排在了后面,而能够解释模型预测变得越来越重要。 我们研究了几种方法来解释的模型,并更好地了解它们的工作方式。 在这里,我们将研究SHAP值,这是一种解释来自机器学习模型的预测的有效方法。
SHAP —表示SHapley Additive ExPlanations是一种解释来自机器学习模型的单个预测的方法。
它们如何运作?
SHAP基于Shapley值,Shapley值是经济学家Lloyd Shapley提出的博弈论概念。通过允许我们查看每个特征对模型的预测有多大贡献,该方法可以帮助我们解释模型。我们模型中的每个特征都将代表一个“玩家”,而“游戏”将是该模型的预测。实际上,我们将尝试查看每个玩家对游戏的贡献。
这样做的过程涉及计算具有特征而不具有每个特征的模型的预测。通过获得这两个预测之间的差异,我们可以看到该特征对模型的预测有多大贡献。这是特征的边际贡献。我们对特征的每个子集都执行此操作,并取这些贡献的平均值,以获得特征的Shapley值。
计算边际分布
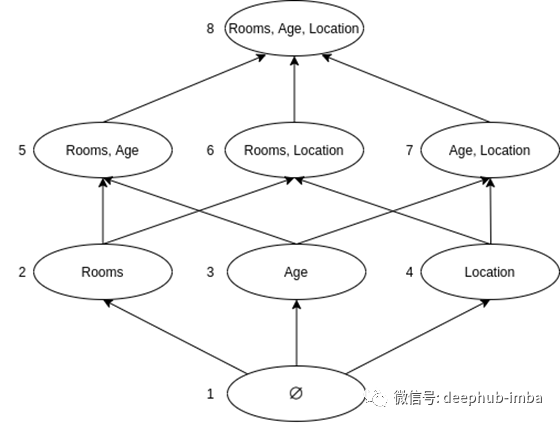
对于我们的示例,假设我们有一个可以预测房屋价格的模型。上图以图形形式显示了这一点。我们将具有三个特征:房间,年龄和位置。总共我们将有8个不同的特征子集。图中的每个节点将代表一个单独的模型,因此我们还将有8个不同的模型。我们将在其相应的子集上训练每个模型并预测相同的数据行。
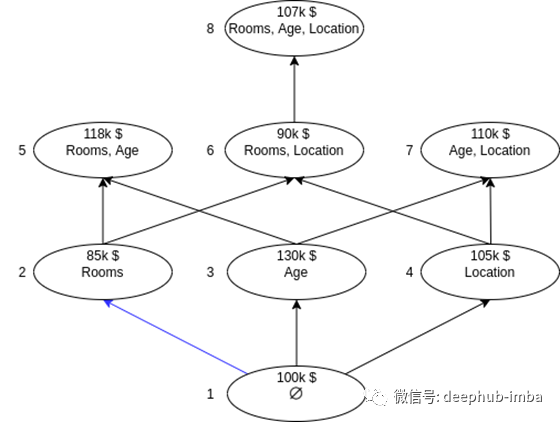
图中的每个节点都通过有向边连接到另一个节点。节点1将没有任何特征,这意味着它将仅预测在训练数据中看到的平均值(100k $ )。沿着到达节点2的蓝色边缘,我们看到具有单个特征“房间”的模型预测的较低值为85k $。这意味着,对于以“房间”作为唯一特征的模型,“房间”的边际贡献为-15k $(85k $-100k $)。我们已经针对一个模型执行了此操作,但是有多个模型具有“房间”特征。我们将对添加了“房间”特征的每个模型进行此计算。
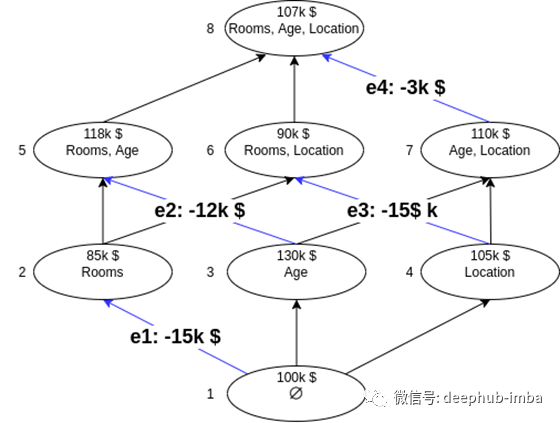
上图突出显示了添加了“房间”特征的每个边缘,还显示了每个模型中该特征的边际贡献。我们要做的下一件事是取这些边际贡献的平均值。唯一的问题是,我们将如何在平均水平上权衡它们中的每一个。您可能会认为我们可以平等地权衡每个因素,但事实并非如此。具有较少特征的模型将意味着每个特征的边际贡献将更大。因此,具有相同数量特征的模型应具有相同的权重。

我们可以将我们的图形分成行,如上所示。每行将包含其中具有不同数量特征的模型。在平均边际贡献时,我们希望每一行都具有相同的权重。由于我们有3行因此每行的权重为1/3。对于具有2个特征模型的行,我们有两个具有“房间”的模型,因此每个模型的权重应为1/6。我们对每种“类型”的模型的权重的细分如下:
1个特征模型:1/3
2个特征模型:1/6
3个特征模型:1/3
我们的最终计算将如下所示:
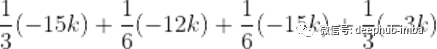
因此,我们的“房间”特征的SHAP值为-10.5k $。然后,我们可以对模型中的每个特征重复此过程,以找到所有特征的值。这种特定方法的优点在于,我们可以看到特征如何影响单个预测,而不仅仅是对数据集中所有示例的平均影响。
使用样例
上面的算法看着很复杂,很难从头开始实现所有这些, 但是是与Python的好处就是我们可以使用一个称为shap的库来完成此任务。与上面的示例一致,我们将使用Kaggle的房地产数据集(https://www.kaggle.com/arslanali4343/real-estate-dataset)。代码如下
# Import train_test_split and regressor
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# Separate features and target
features = df.drop('MEDV', axis=1)
target = df['MEDV']
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(features, target, random_state=42)
# Fit the regressor
reg = RandomForestRegressor(random_state=42)
reg.fit(X_train, y_train)
# Choose a row of data to analyze
row_num = 7
row_data = X_test.iloc[row_num]
# Import the shap library
import shap
# Use the TreeExplainer to get shap values then plot them
tree_explain = shap.TreeExplainer(reg)
shap_vals = tree_explain.shap_values(row_data)
shap.initjs()
shap.force_plot(tree_explain.expected_value, shap_vals, row_data)

上图显示了一些重要的信息。这座房子的价值预计为15.42。在图的右侧,我们看到了23.16的基值。我们还看到了两组不同的特征,分别是红色和蓝色。红色突出显示的功能有助于提高预测,而蓝色突出显示的功能则有助于降低预测。每个特征在图中占据的大小显示了它对预测的影响程度。我们看到,特征LSTAT(较低的人口百分比)对降低预测值的贡献最大,而特征CRIM(城镇居民的人均犯罪率)对增加预测值的贡献最大。
您可能已经注意到的另一件事是,我使用了一个名为TreeExplainer的类。这是因为在此示例中,我们使用了基于树的模型(Random Forest)。在shap库中有几个“解释器”。适用于非基于树的模型的更通用的解释器是KernelExplainer。另外,您也可以将DeepExplainer用于深度学习模型。
# Train a regression model
reg = RandomForestRegressor(random_state=42)
reg.fit(X_train, y_train)
# Choose a random row number to analyze
row_num = 20
row_data = X_test.iloc[row_num]
# Calculate shap values using the TreeExplainer
tree_explain = shap.TreeExplainer(reg)
shap_vals = tree_explain.shap_values(row_data)
# Create a decision plot
shap.decision_plot(tree_explain.expected_value, shap_vals, X_test.columns)
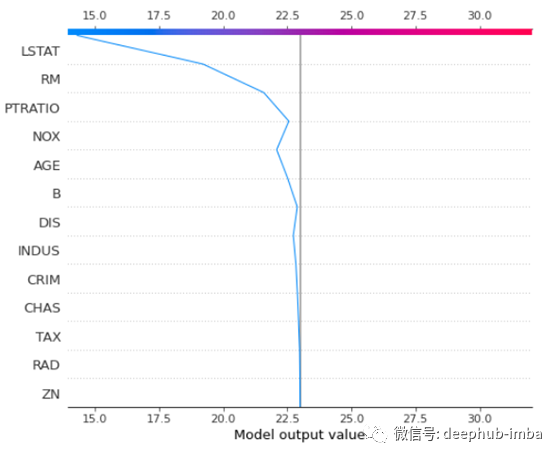
我们可以通过上面的决策图来查看此单个预测的另一种方法。我们在基准值为23.16处看到一条黑色实线。从底部开始并向上移动图,我们看到遇到的每个特征如何影响模型的预测,直到到达顶部,这是对特定数据行的最终预测。还有许多其他方法可以可视化模型中的SHAP值。
总结
我们已经研究了SHAP值,这是一种解释来自机器学习模型的预测的方法。通过这种方法,我们可以查看各个预测,并了解每个功能如何影响结果。通过查看确定房屋价格的模型,我们逐步完成了SHAP值的示例计算。我们还查看了Python中的shap库,以便能够快速计算和可视化SHAP值。特别是,我们介绍了用于可视化SHAP值的force_plot和Decision_plot。
感谢您的阅读!
作者:Zito Relova
原文地址:https://towardsdatascience.com/shap-values-for-model-interpretation-268680a25012
deephub翻译组