
论文的目标
这篇论文要解决什么问题?
大规模图像识别试图解决将Transformer架构应用于计算机视觉任务的问题,以减轻该领域对CNN的严重依赖。本文提出这样的论点,即这种转换将产生与传统CNN相当的结果,同时需要较少的计算资源进行训练。
这个问题的相关背景是什么?
transformer 已被广泛用于NLP任务,如目前最先进的BERT模型、GPT模型及其变体。在图像任务中使用transformer还做了一些其他工作,但它们通常都非常昂贵。
本文的贡献
这篇论文提出了什么方法来解决这个问题?
为了调整图像输入以适应transformer的输入,本文将2D图像重新整形为一系列平坦的2D斑块。嵌入补丁的序列之前是可学习的特征嵌入层。此令牌的作用与BERT的[class]令牌类似。然后将位置嵌入添加到补丁嵌入中以保留位置信息。
transformer编码器由多头自注意块和MLP块交替层组成。变压器编码器的输出状态作为图像表示。在预训练和微调期间,一个分类头,MLP附加到编码器的输出。在预训练期间,MLP有一个隐藏层,可以用作微调期间使用。
视觉转换器(ViT)在大型数据集上进行了预先训练,然后对较小的下游任务进行微调。微调是通过移除预先训练的预测头,并用零初始化的前馈层替换它来完成的。
本文的贡献与以往的相关工作有何不同?
这不是第一篇将变压器应用于CV的论文。Facebook实际上已经发布了一款型号DETR(检测变压器);然而,它们是与cnn联合使用的,而不是单独使用的。本文是独立transformer在CV中的一个成功应用。对于每一项主要贡献,其差别如下:
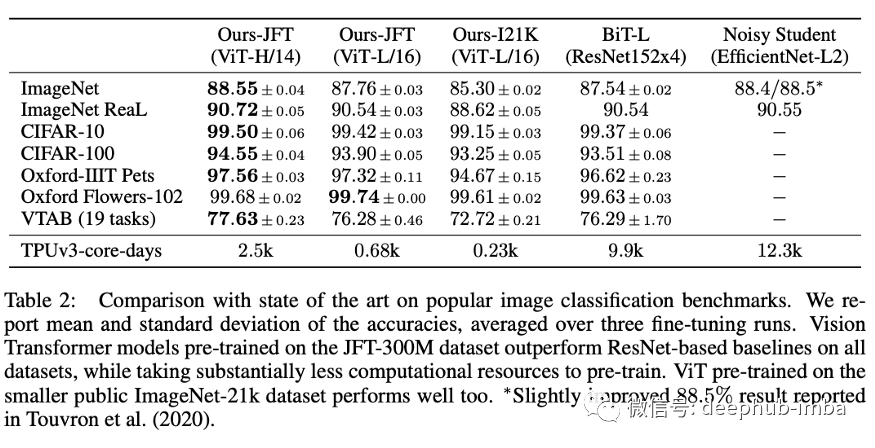
计算时间更短、精度相当:ViT对噪音较大的学生网络减少了大约5倍的训练时间(训练时间的20%)(尽管它达到了与表2大致相同的精度)。
没有卷积:理论上,MLP比CNN模型表现更好。然而,数据一直是影响MLP模型性能的一大障碍。CNN施加的归纳偏置极大地推动了CV领域的发展,并且由于作者使用了庞大的数据集,他们能够克服归纳偏置的需求。transformer与传统MLP略有不同,其核心机制是自我关注。这使变压器能够理解输入之间的关系。在NLP中使用时,它以双向的方式计算单词之间的关系,这意味着顺序不像单向RNN那样严格。
transformer的效果:本文通过查看关注头的输出来分析ViT的内部表示(类似于BERTology论文)。论文发现该模型可以使用位置嵌入来编码不同面片之间的距离。该论文还发现,ViT甚至可以在较低层中集成来自整个图像的信息,并指出:“我们发现一些头部会关注已经在最底层的大部分图像,这表明该模型确实使用了全局整合信息的能力。”此外,他们还对模型的表现进行了定量分析,并定性地可视化了模型的注意图和焦点。
论文是如何评估其结果的?
该方法在三个不同的数据集上进行:Imagenet (1k类和21k类),JFT (18k类)和VTAB。结果是通过小样本或微调精度来测量的,微调精度表示在数据集上微调模型后的精度,小样本精度表示在对图像子集进行训练和评估后的精度。
他们将转换模型与流行的图像分类基准进行了比较,例如Big Transfer和Noisy Student。在本文中,他们通过基于BERT的ViT配置了ViT,并通过使用组归一化替换批归一化以及采用标准化卷积来改进转移学习来对Resnet进行了修改。
此外,本文对自我监督训练ViT进行了初步研究,结果表明,通过自我监督的预训练,与从零开始训练相比,准确率提高了2%。
论文的局限性,进一步的研究和/或潜在的应用
本文介绍了ViT:视觉转换器的使用,而不是CNN或混合方法来执行图像任务。结果是有希望的但并不完整,因为因为除了分类之外的基于视觉的任务:如检测和分割,还没有表现出来。此外,与Vaswani等人(2017年)不同,与CNN相比,transformer 性能的提升受到的限制要大得多。作者假设进一步的预训练可以提高性能,因为与其他现有技术模型相比,ViT具有相对可扩展性。
此外,Kaplan等人提出了与NLP中的LSTMs相比,目前的缩放比例主要适用于transformers,这表明可以将变压器缩放到更大的数据集。有趣的是与CNN相比,transformers变压器是否具有相似的性能。如果是这样,那么很明显的迹象表明,基于变压器的技术也将在CV中成为SOTA。
最终,这些结果表明,transformers有可能成为通用模型,能够在广泛的人工任务中学习,并享有以超大规模扩展数据的能力。这种愿景还没有出现,也可能永远不会出现;如果可以,这篇论文将被认为是未来的先兆。
论文地址: https://arxiv.org/pdf/2010.11929.pdf
本文作者:Cornell Data Science
deephub翻译组