
在Transformers颠覆了自然语言处理和计算机视觉之后,他们现在把目光投向了最大的数据类型:表格数据。
在这篇文章中,我们将介绍亚马逊的最新论文TabTransformer。
首先,我们将回答为什么可以将transformer应用于表格数据。然后,我们将看到他们如何处理表格数据。
那么下面就开始吧:汽车人,变形出发!
为什么我们可以将Transformers应用于表格数据?
transformer最初是作为一种建模语言的方法被提出的。那么,表格数据是一种语言吗?把普通的表格和人类的语言进行比较感觉很奇怪。
事实是,统计模型并不关心我们的感觉。
他们所关心的只是表征数据的统计属性。这里我们要展示的是表格数据和语言有很多相同的属性。在某种意义上,分类表数据是一种超结构化的语言子集。
假设每一行都是一个“句子”,每一列值都是一个“单词”或一个标记。从语言到表格数据的额外约束如下:
这些句子都是固定长度的:每一行都有相同数量的列。
单词的顺序并不重要,但在定义表格语言时已达成共识。重要的是语言的真实顺序。
在每个位置,一个单词可以采用的值都是固定的,并且每个单词的取值都不同:每个单词都是一个分类特征。使用常规语言,您可以在字典中的所有单词之间进行选择,甚至可以根据需要创建新的单词。

事实证明,这些限制并没有限制Transformers的使用。事实正好相反。
当令牌的顺序不重要时,Transformers变得更加完美的。它甚至简化了模型。现在可以省去原始论文中的位置编码步骤。
这也解释了为什么递归神经网络(RNN)不能很好地处理表格数据。RNNs本身就使用令牌的顺序性和位置。
下图显示了TabTransformer的模型架构:
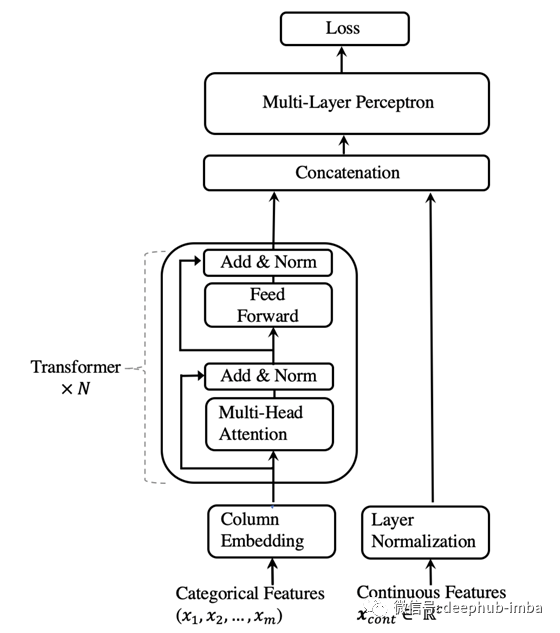
因此,我们都同意至少在表格数据上尝试Transformers是有意义的。现在让我们看看它们与其他表格数据模型的比较情况。
Transformers的三个优点
模型特征与上下文嵌入的交互
在许多列表“语言”中,都存在有意义的特性交互。一个特性的值会影响另一个特性的解释方式。
由于决策树具有连续的决策制定过程,因此它可以很自然地为这些交互行为建模。树中更深层次的决策依赖于从根开始的所有以前的决策,因此以前的特征值会影响当前特征的解释。
其他模型,比如线性支持向量机,无法捕捉这些交互作用。
在自然语言中,这个概念(称为一词多义)也是至关重要的。正如英国语言学家约翰·r·弗斯所说:
“你应该根据一个词的语境来认识它。”
这就是为什么transformer还通过它的多头自注意机制来显式地建模令牌交互。通过这种方式,模型产生了上下文嵌入。
DeepEnFM的研究人员是第一个解决多头注意力表格数据中特征交互问题的研究人员。
使用了强大的半监督学习技术
在关于TabTransformer的文章中,作者指出可以从自然语言处理中复制两种强大的半监督训练技术。
第一个是BERT介绍的一种技术,称为掩蔽语言建模。与语言模型一样,您也可以通过屏蔽输入句子中的标记并学习预测屏蔽标记来训练表格数据上的transformers。
第二种是基于关于ELECTRA的论文的学习技术。这是“替换令牌检测”。他们没有掩盖功能,而是将其替换为替代类别。然后对TabTransformer进行训练,以预测哪些功能已换出。
处理缺失和嘈杂的数据
transformers的最后一个优点是,它们在处理缺失和嘈杂的特征方面表现出色。这些来自TabTransformer的图表显示了MLP和transformers之间的比较。
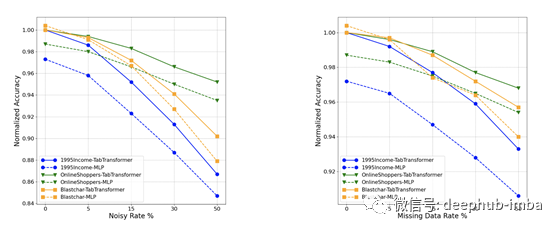
因为transformers使用上下文嵌入,所以它们可以从上下文中提取信息以纠正丢失或嘈杂的数据。
MLP还可以学习嵌入,但是它们无法对矢量方向的功能交互进行建模。它们的体系结构将它们限制为按位交互,但是这会损害其性能。
结论
TabTransformer打开了表示学习天堂的大门,同时匹配了基于树的集成模型的性能。这是MLP无法提供的。
很好奇,看看接下来的几个月还会有什么!
论文地址:TabTransformer: Tabular Data ModelingUsing Contextual Embeddings https://arxiv.org/pdf/2012.06678.pdf
本文作者:Jakob Cassiman
原文地址:https://blog.ml6.eu/transformers-for-tabular-data-hot-or-not-e3000df3ed46
deephub翻译组