
介绍
今天,人工智能(AI)已经经历了令人印象深刻的进步。根据机器逻辑独立执行智能任务的能力,人工智能可以分为三个不同的层次:
窄AI:机器在执行非常特定的任务时比人类更有效率(但不会尝试执行其他类型的任务)。
强AI:机器在不同领域(在我们可能或根本无法执行的任务中)都比人类表现得更好。
通用AI:机器和人类一样智能。
现在,因为机器学习我们已经能够在有限的人工智能水平上获得良好的能力。主要有三种机器学习算法:
监督学习:使用有标记的训练集来训练模型,然后对没有标记的数据进行预测。
无监督学习:给一个模型一个未标记的数据集,然后模型试图在数据中找到模式来做出预测。
强化学习:通过奖励机制训练模型,在表现良好的情况下鼓励积极行为(特别是在基于agent的模拟、游戏和机器人中)。
而强化学习,现在被认为是最有前途的技术,以推动AI范式的下一个层次(图1)。
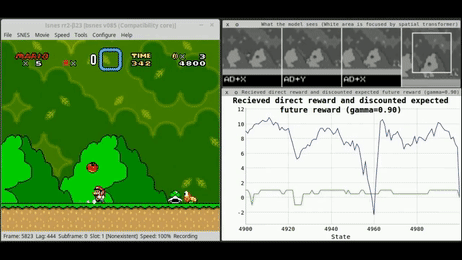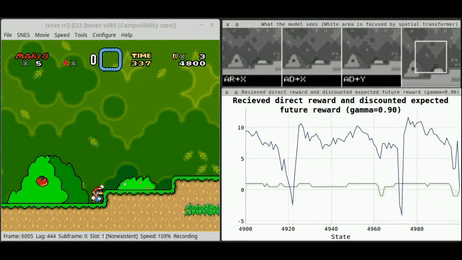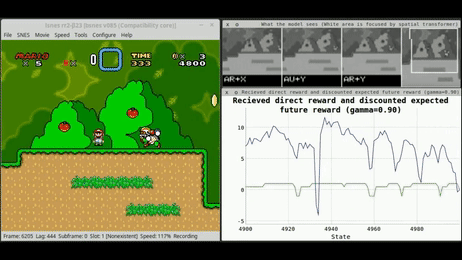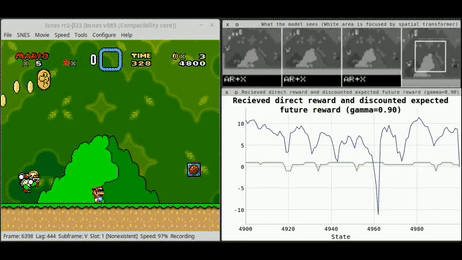
强化学习(RL)
强化学习之所以在今天获得如此多的关注,其中一个原因是它的跨学科性。这一领域的核心概念实际上遵循了基本的博弈论、进化和神经科学原则。
与所有其他形式的机器学习相比,事实上,RL可以被认为是试图复制人类和动物学习方式的最接近的方法。
强化学习提倡人类最常用于学习的主要方式是通过使用传感器并与环境互动(因此,在有监督的学习中,无需像外部指导那样,而是通过反复试验的过程)。
在日常生活中,我们试图完成新的任务,而我们尝试的结果会影响我们周围的环境。通过评估我们的尝试,我们可以从经验中学习,确定哪些行动给我们带来了更大的好处(因此最方便重复),哪些应该避免。图2总结了这种迭代过程,并表示了大多数基于强化学习算法的主要工作流程。
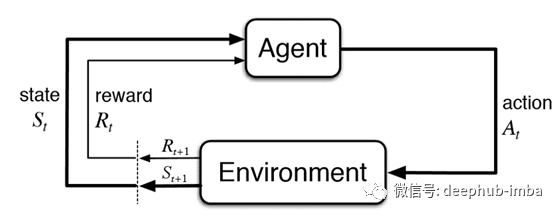
强化学习系统的两个主要挑战是:
探索与开发的问题:如果AGENT发现一个可以给他带来适度高额报酬的行动,可能会不尝试任何其他可用的行动,因为害怕这样做可能会不太成功。同时,如果AGENT甚至不尝试其他操作,则可能永远不会发现有可能获得更好的回报。
延迟奖励的处理:不告诉AGENT要采取何种行动,而应提出不同的解决方案,对其进行测试,最后根据收到的奖励对它们进行评估。AGENT不应该仅仅根据他们的立即回报来评估他们的行动。实际上,选择某种类型的行动可能会不会立即产生更大的回报,而应看长期的回报。
核心组件
根据Richard S. Sutton等人的说法。[3],强化学习算法由4个主要关键部分组成:策略,奖励,价值函数,环境模型。
策略:定义AGENT行为(将不同的状态映射到操作)。由于每个特定操作都与要选择的概率相关联,因此策略最有可能是随机的。
奖励:一种信号,用于提醒代理如何最好地修改其策略以实现已定义的目标(在短时间内)。每次执行操作时,都会从环境中收到对代理商的奖励。
价值函数:用于从长远角度了解哪些动作可以带来更大的回报。它的工作原理是为不同的状态分配值,以评估代理商从任何特定状态开始应该期望的报酬。
环境模型:模拟代理所处环境的动态,以及环境应如何响应代理所采取的不同措施。取决于应用程序,某些RL算法不一定需要环境模型(无模型方法),因为可以使用试错法进行处理。虽然基于模型的方法可以使RL算法处理需要计划的更复杂的任务。
总结
如果您有兴趣了解有关强化学习的更多信息,Richard S. Sutton和Andrew G. Barto的“Reinforcement Learning: An Introduction”和Open AI Gym(将在我的下一篇文章中讨论!)是两个不错的起点 。
作者:Pier Paolo Ippolito
原文地址:https://towardsdatascience.com/getting-started-with-reinforcement-learning-cf2f2655854
deephub翻译组