
什么是注意力机制?为什么RFA比Softmax更好?
Google最近发布了一种新方法-Random Feature Attention-用来取代transformers中的softmax注意力机制,以实现相似或更好的性能,并显着改善时间和空间复杂度。
在此文章中,我们将探讨transformers的背景,什么是注意力机制,以及为什么RFA可以更好地替代softmax注意力机制。我们将通过RFA的一些总结来结束本文章。
背景
目前,transformers是序列到序列机器学习模型的最佳模型。它专门研究数据序列使其在自然语言处理,机器翻译,时间序列建模和信号处理中特别有用。
注意力机制是transformers成功的基石。这些机制研究输入序列并确定最重要的元素。这些元素在对序列进行编码时将具有较重的权重,即应引起更多关注。
注意机制是什么?
可以认为这就像我们在开会中写笔记以编写后续电子邮件一样。当记笔记时,我们几乎不可能写下所有内容。我们可能需要用缩写词或图画代替单词;我们可能还需要跳过可以在意义上损失最小的情况下推断出的词。此过程会将一个小时的会议压缩到仅一页的笔记中。本质上,注意力机制在尝试通过更加重要的嵌入(单词的缩写或图标表示)来尝试编码序列的过程中也是如此。
什么是Softmax注意机制?
假设我们有这样一个句子"注意力机制到底是什么"
注意机制的目标是计算一个相对矩阵,该矩阵涉及序列的不同部分应如何相互链接。例如,“注意”和“机制”应该联系在一起,但两者都不应该与“实际”和“是”紧密联系在一起。
该机制将从输入句子的数字形式开始,即一个词嵌入矩阵
注意:词嵌入是一个词的向量表示,它包含该词的不同属性。这些属性的一个过于简单的例子可以是情感、词性和字符数。
然后,它将初始化查询W_q、键W_k和值W_v的三个权重矩阵。
然后,我们可以计算查询矩阵Q、键矩阵K和值矩阵V,分别作为词嵌入矩阵与W_q、W_k和W_v的点积。正如论文中所述,最初的注意力矩阵可以计算如下:
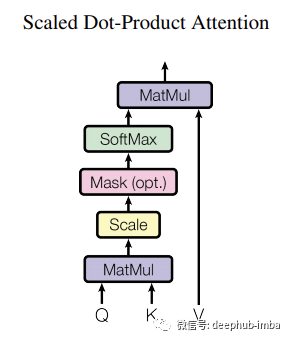
数学公式如下:
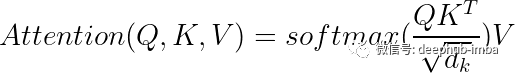
为了帮助理解矩阵的操作流程,下面是底层矩阵的图形流程:
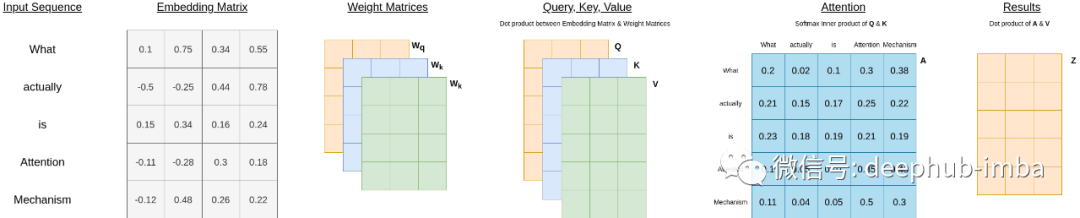
这种注意力也被称为softmax注意力,因为它使用softmax激活函数将Q和K的缩放点积转化为注意力的相对测量,即a,其中每一个单词将分享一个比例的注意力,然后总和为1(或100%)。softmax结果将与V结合,为其提供基于注意力的语义结果。
但是什么是查询、键和值呢?
要理解查询、键、值三人组背后的概念,一种过于简单的方法是将transformer理解句子的能力视为最大化以下条件可能性:
当输入序列为[y, "actually", "is", "attention", "mechanism"]时,y = " What "的概率
当输入序列为["what", y, "is", "attention", "mechanism"]时,y = " actually "的概率
当输入序列为["what", "actually", y, "attention", "mechanism"]时,y = " is "的概率为
当输入序列为["what", "actually", "is", y, "mechanism"]时,y = " attention "的概率
当输入序列为["what", "actually", "is", "attention", y]
而推断可能性的方法是注意输入句子中的其他单词(单词嵌入)。在训练过程中,transformers将学习如何在嵌入的基础上通过精炼三个权重矩阵来链接单词。
这种架构的好处在于,我们可以通过创建多组查询、键、值三元组(也称为多头注意)或堆叠这些注意层来捕获更复杂的语义结构。
为什么Softmax的注意力机制不够好?
在一个典型的transformer中,部署多头注意力来解压缩更复杂的语言模式。softmax注意力机制的时间和空间复杂度变成O(MN),并以输入序列长度的二次速率增长。

为了解决这个问题,来自Google Deepmind的小组利用了Bochner定理,并扩展了Rahmi&Recht(2008)的工作,softmax函数与指数函数的随机特性映射ϕ(独立和正态分布的随机向量w与输入语句x之间的内积的傅立叶特征)。

softmax函数

随机特征映射
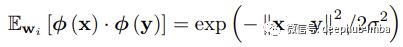
随机特征图的点积可用于估计指数函数
在不深入过多数学推导细节的情况下,softmax注意机制可以近似为以下结构:
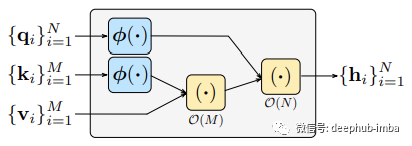
通过将softmax近似为RFA,谷歌Deepmind将时间和空间复杂度降低到O(M + N),即从二次到线性。
Deepmind的研究成果
由于RFA具有相同的输入和输出尺寸要求,可以作为softmax注意机制的替代。
随着复杂度从二次型下降到线性型,RFA在输入文本序列较长的情况下得到了更显著的改善。
RFA背后的基本原理可以用来近似高斯核之外的其他核函数。在谷歌Deepmind的论文中,他们演示了如何将同样的方法应用于近似弧余弦核。
与softmax一样,RFA本身并不考虑输入句子中的位置距离。在Deepmind的谷歌论文中,他们讨论了如何将递归神经网络的灵感应用于RFA,从而使单词的重要性根据它们在句子中的相对位置呈指数衰减。
最后但并非最不重要的是,机器学习看起来非常出色,但它都是关于数学和统计的。多亏了优秀的研究人员和程序员,我们才有了像TensorFlow和PyTorch这样的高级软件包。尽管如此,我们仍然需要不断学习最新的发展和修改核心概念,以确保我们正在开发可解释的机器学习模型和管道。
作者:Louis Chan
deephub翻译组