
- 遥感概论
- 土地覆盖分类的深度学习
- Sundarbans 国家公园卫星图像
- CNN在土地覆盖分类中的实现
- 结论
- 参考文献
遥感概论
遥感是探测和监测一个地区的物理特征的过程,方法是测量该地区在一定距离(通常是从卫星或飞机)反射和发射的辐射。特殊摄像机收集远程遥感图像,这有助于研究人员“感知”地球上的事物。
由带电粒子振动产生的电磁能量,以波的形式在大气和真空空间中传播。这些波有不同的波长和频率,波长越短,频率就越高。有些电波、微波和红外线的波长较长。而紫外线、x射线和伽马射线的波长要短得多。可见光位于长到短波辐射范围的中间。这一小部分能量是人类肉眼所能探测到的。需要仪器来探测所有其他形式的电磁能。在不同卫星的帮助下,我们利用全范围的光谱来探索和理解发生在地球和其他行星上的过程。
一些例子是:
- 卫星和飞机上的相机拍摄了地球表面大面积的图像,使我们看到的东西比我们站在地面上看到的多得多。
- 船上的声纳系统可以在不需要潜入海底的情况下生成海底图像。
- 卫星上的照相机可以用来拍摄海洋温度变化的图像。
地球遥感图像的一些具体用途包括:
- 大型森林火灾可以从太空中绘制地图,使得护林员可以看到比地面大得多的区域。
- 追踪云层来帮助预测天气或观察喷发的火山,并帮助观察沙尘暴。
- 在数年或数十年的时间里跟踪城市的发展和农田或森林的变化。
- 发现并绘制海底崎岖的地形(例如巨大的山脉、深谷和海底的“磁条”)。
在本文中,我们将使用Sentinel-2卫星收集的数据。以下是简要信息:
Sentinel-2任务由两颗卫星组成,用于支持植被、土地覆盖和环境监测。2015年6月23日,欧洲航天局(ESA)发射了Sentinel-2A卫星,在太阳同步轨道上运行,周期为10天。第二颗相同的卫星Sentinel-2B于2017年3月7日发射,并可在EarthExplorer上获取数据。它们每隔五天就会覆盖地球所有的陆地表面、大型岛屿以及内陆和沿海水域。
Sentinel-2多光谱仪器(MSI)沿着290公里的轨道带获得了从可见和近红外(VNIR)到短波红外(SWIR)波长的13个光谱波段。MSI测量了在13个光谱波段内通过大气的反射辐射。空间分辨率取决于特定的光谱波段:
10米波段:蓝色(490 nm),绿色(560 nm),红色(665 nm),近红外(842 nm)。在20米处有6个波段:4个窄波段用于植被表征(705 nm、740 nm、783 nm和865 nm)和2个较大的SWIR波段(1610 nm和2190 nm)用于雪/冰/云探测或植被水分胁迫评估。60米波段:主要用于云层遮挡和大气校正(气溶胶为443 nm,水蒸气为945 nm,卷云探测为1375 nm)。
土地覆盖分类的深度学习
深度学习。神经网络。反向传播。在过去的一两年里,我经常听到这些流行词,最近它也确实抓住了我的好奇心。深度学习是当今一个活跃的研究领域,如果你一直关注计算机科学领域,我相信你至少一次遇到过其中的一些术语。
深度学习可能是一个令人生畏的概念,但如今它变得越来越重要。谷歌已经通过谷歌Brain项目和最近收购伦敦的深度学习初创公司DeepMind在这一领域取得了巨大进展。此外,深度学习方法几乎在每一个指标上都击败了传统的机器学习方法。
深度神经网络(Deep Neural network, DNNs)和卷积神经网络(Convolutional Neural network, CNNs)是目前广泛应用于土地覆盖分类的方法。
深度神经网络(DNN)
一般来说,神经网络是一种用来模拟人类大脑活动的技术——具体来说,就是模式识别和输入通过模拟神经连接的各个层次。
许多专家将深度神经网络定义为具有输入层、输出层和中间至少有一层隐藏层的网络。每一层在一个被称为“特性层次结构”的过程中执行特定类型的排序和排序。“这些复杂的神经网络的关键用途之一是处理未标记或非结构化数据。“深度学习”一词也被用来描述这些深度神经网络,因为深度学习代表了一种特定形式的机器学习,在机器学习中,技术使用人工智能方面寻求以超越简单输入/输出协议的方式对信息进行分类和排序。
本文对实现高光谱图像的土地覆盖分类进行了验证。
卷积神经网络(CNN)
根据《CS231n:用于视觉识别的卷积神经网络》,卷积神经网络与普通神经网络非常相似:它们由具有可学习权值和偏差的神经元组成。每个神经元接收一些输入,执行点积并有选择地进行非线性操作(激活)。整个网络仍然表示一个单一的可微分数函数:从一端的原始图像像素到另一端的分类分数。它们在最后一层(完全连接)上仍然有一个损失函数(例如SVM/Softmax),我们为学习规则神经网络开发的所有技巧/技巧仍然适用。
改变什么呢?ConvNet架构明确假设输入是图像,这允许我们将某些属性编码到架构中。这样可以使转发功能更有效地实现,并极大地减少网络中的参数数量。
池化或下采样层负责减少激活映射的空间大小。通常,在其他层(即卷积层和非线性层)的多个阶段之后使用它们,通过网络逐步减少计算需求,并最大限度地减少过拟合的可能性。
卷积网络中完全连接的层实际上是一个多层感知器(通常是两层或三层MLP),其目标是将先前不同层的组合激活量映射到一个类概率分布中。
用于卫星影像土地覆盖分类的架构有AlexNet、ResNet、Inception、U-Net等。
Sundarbans国家公园卫星图像
孙德尔本斯(Sundarbans)是孟加拉湾恒河、雅鲁藏布江和梅克纳河汇流形成的三角洲中最大的红树林地区之一。孙德尔本斯森林横跨印度和孟加拉国,面积约为1万平方公里,其中40%位于印度境内,是许多珍稀和全球濒危野生物种的家园。在本文中,我们将使用2020年1月27日Sentinel-2卫星获取的孙德本斯卫星数据的一部分。
让我们开始编码。
读取数据
让我们使用rasterio读取12个波段,并使用numpy.stack()方法将它们堆叠成一个n维数组。叠加后得到的数据形状为(12,954,298)。使用loadmat方法从scipy.io包中读取卫星图像的地面真值。真值包含6类,包括水,植物,树木,土地等。
from glob import glob
import numpy as np
from scipy.io import loadmat
import rasterio as rio
S_sentinel_bands = glob("/content/drive/MyDrive/Satellite_data/sundarbans_data/*B?*.tiff")
S_sentinel_bands.sort()
l = []
for i in S_sentinel_bands:
with rio.open(i, 'r') as f:
l.append(f.read(1))
# Data
arr_st = np.stack(l)
# Ground Truth
y_data = loadmat('Sundarbands_gt.mat')['gt']
数据可视化
这些数据具有多个波段,其中包含从可见光到红外光的数据。因此,很难对人类的数据进行可视化。通过创建RGB复合图像,可以更轻松地有效理解数据。要绘制RGB复合图像,您将绘制红色,绿色和蓝色波段,分别是波段4、3和2。由于Python使用从零开始的索引系统,因此您需要从每个索引中减去1的值。因此,红色带的索引为3,绿色为2,蓝色为1。
如果像素亮度值偏向零值,则我们创建的合成图像有时可能会很暗。可以通过使用参数Stretch = True拉伸图像中的像素亮度值以将这些值扩展到电位值的整个0-255范围以增加图像的视觉对比度来解决此类问题。另外,str_clip参数允许您指定要裁剪的数据尾部的数量。数字越大,数据将被拉伸或变亮的越多。
我们来看一下绘制RGB复合图像以及所应用的拉伸的代码。
ep.plot_rgb(
arr_st,
rgb=(3, 2, 1),
stretch=True,
str_clip=0.02,
figsize=(12, 16),
# title="RGB Composite Image with Stretch Applied",
)
plt.show()
让我们使用eathpy.plot包中的plot_bands方法可视化。
ep.plot_bands(y_data,
cmap=ListedColormap(['darkgreen', 'green', 'black',
'#CA6F1E', 'navy', 'forestgreen']))
plt.show()
下图显示了Sundarbans卫星数据的合成图像和地面真实情况。

正如我们所讨论的,数据包含12个波段。让我们使用EarhPy套件可视化每个波段。plot_bands()方法获取带和图的堆栈以及自定义标题,这可以通过使用title =参数 将每个图像的唯一标题作为标题列表传递来完成。
ep.plot_bands(arr_st,
cmap = 'gist_earth',
figsize = (20, 12),
cols = 6,
cbar = False)
plt.show()

CNN进行土地覆盖分类
让我们通过对数据应用主成分分析(PCA)来创建Sundarbans卫星图像的三维补丁。以下代码用于创建实现PCA的功能,创建3D补丁以及将数据按70:30的比例拆分为训练数据和测试数据。分割数据后,使用tensorflow.keras包中的to_categorical()方法对训练标签和测试标签进行编码。
def applyPCA(X, numComponents=75):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0],X.shape[1], numComponents))
return newX, pca
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
def createImageCubes(X, y, windowSize=5, removeZeroLabels = False):
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=42):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test
## GLOBAL VARIABLES
dataset = 'SB'
test_size = 0.30
windowSize = 15
MODEL_NAME = 'Sundarbans'
path = '/content/drive/MyDrive/Sundarbans/'
X_data = np.moveaxis(arr_st, 0, -1)
y_data = loadmat('Sundarbands_gt.mat')['gt']
# Apply PCA
K = 5
X,pca = applyPCA(X_data,numComponents=K)
print(f'Data After PCA: {X.shape}')
# Create 3D Patches
X, y = createImageCubes(X, y_data, windowSize=windowSize)
print(f'Patch size: {X.shape}')
# Split train and test
X_train, X_test, y_train, y_test = splitTrainTestSet(X, y, testRatio = test_size)
X_train = X_train.reshape(-1, windowSize, windowSize, K, 1)
X_test = X_test.reshape(-1, windowSize, windowSize, K, 1)
# One Hot Encoding
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print(f'Train: {X_train.shape}\nTest: {X_test.shape}\nTrain Labels: {y_train.shape}\nTest Labels: {y_test.shape}')
CNN模型
让我们构建一个具有不同图层(例如卷积,dropout和密集图层)的三维CNN。以下代码用于使用TensorFlow创建用于土地覆盖分类的3D-CNN。
S = windowSize
L = K
output_units = y_train.shape[1]
## input layer
input_layer = Input((S, S, L, 1))
## convolutional layers
conv_layer1 = Conv3D(filters=16, kernel_size=(2, 2, 3), activation='relu')(input_layer)
conv_layer2 = Conv3D(filters=32, kernel_size=(2, 2, 3), activation='relu')(conv_layer1)
conv2d_shape = conv_layer2.shape
conv_layer3 = Reshape((conv2d_shape[1], conv2d_shape[2], conv2d_shape[3]*conv2d_shape[4]))(conv_layer2)
conv_layer4 = Conv2D(filters=64, kernel_size=(2,2), activation='relu')(conv_layer3)
flatten_layer = Flatten()(conv_layer4)
## fully connected layers
dense_layer1 = Dense(128, activation='relu')(flatten_layer)
dense_layer1 = Dropout(0.4)(dense_layer1)
dense_layer2 = Dense(64, activation='relu')(dense_layer1)
dense_layer2 = Dropout(0.4)(dense_layer2)
dense_layer3 = Dense(20, activation='relu')(dense_layer2)
dense_layer3 = Dropout(0.4)(dense_layer3)
output_layer = Dense(units=output_units, activation='softmax')(dense_layer3)
# define the model with input layer and output layer
model = Model(name = dataset+'_Model' , inputs=input_layer, outputs=output_layer)
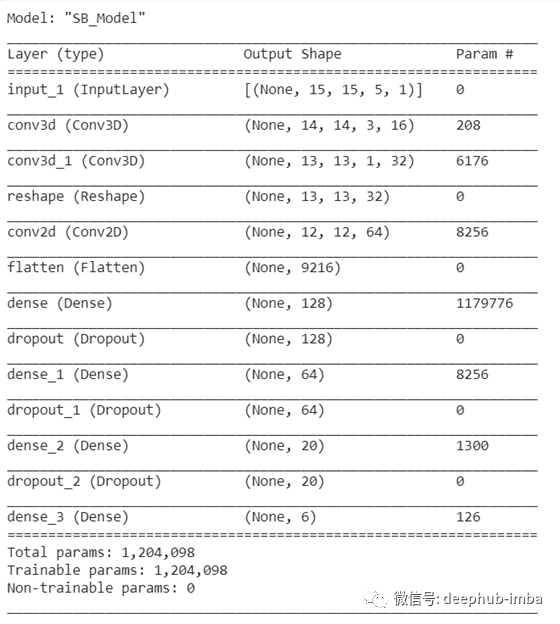
model.summary()
3D-CNN模型总共具有1,204,098个可训练参数。下图显示了已开发的3D-CNN模型的摘要。
训练
为了训练定义的DNN,我使用了Adam优化器,分类交叉熵,准确性作为度量以及回调。对用于训练3D-CNN的优化器,丢失和回调的简要说明。
Adam优化器
Adam是一种优化算法,可以代替经典的随机梯度下降过程来基于训练数据来更新网络权重。使用adam优化器的优点是:
- 计算效率高。
- 很少的内存需求。
- 梯度的对角线重标不变。
- 非常适合于数据和/或参数较大的问题。
- 适用于非固定目标。
- 适用于非常嘈杂/或稀疏梯度的问题。
- 超参数具有直观的解释,通常需要很少的调整。
分类交叉熵
交叉熵是用于多类分类问题的默认损失函数。在这种情况下,它适用于目标值位于{0,1,3,…,n}集中的多类分类,其中为每个类分配一个唯一的整数值。从数学上讲,它是最大似然推理框架下的首选损失函数。损失函数是第一个评估的函数,只有在有充分理由的情况下才可以更改。
交叉熵将计算得分,该得分总结问题中所有类别的实际概率分布与预测概率分布之间的平均差。分数被最小化,理想的交叉熵值为0。可以在编译模型时通过指定“ categoical_crossentropy”将交叉熵指定为Keras中的损失函数。
回调
EarlyStopping:减少神经网络过度拟合的一种技术是使用早期停止。尽早停止会在模型没有真正学习到任何东西的情况下终止训练过程,从而防止模型过度训练。这是非常灵活的-您可以控制要监视的指标,需要更改多少才能被视为“仍在学习”,以及在模型停止训练之前它可能连续震荡多少个时期。
ModelCheckpoint:此回调将在每个成功的时期之后将模型作为检查点文件(hdf5或h5格式)保存到磁盘。您实际上可以将输出文件设置为根据轮次动态命名。您也可以将损失值或准确性值写入日志文件名的一部分。
TensorBoard:此回调在每批训练后记录,以监控您的指标,图形,直方图,图像等
以下代码用于编译和训练模型。
# Compile
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Callbacks
logdir = path+"logs/" +model.name+'_'+datetime.now().strftime("%d:%m:%Y-%H:%M:%S")
tensorboard_callback = TensorBoard(log_dir=logdir)
es = EarlyStopping(monitor = 'val_loss',
min_delta = 0,
patience = 1,
verbose = 1,
restore_best_weights = True)
checkpoint = ModelCheckpoint(filepath = 'Pavia_University_Model.h5',
monitor = 'val_loss',
mode ='min',
save_best_only = True,
verbose = 1)
# Fit
history = model.fit(x=X_train, y=y_train,
batch_size=1024*6, epochs=6,
validation_data=(X_test, y_test), callbacks = [tensorboard_callback, es, checkpoint])
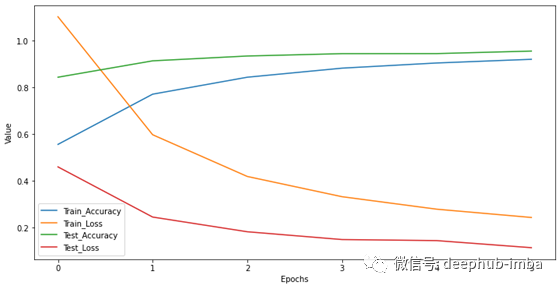
训练期间的准确性和损失图的代码以及输出如下所示,X轴表示时期,Y轴表示百分比。
import pandas as pd
history = pd.DataFrame(history.history)
plt.figure(figsize = (12, 6))
plt.plot(range(len(history['accuracy'].values.tolist())), history['accuracy'].values.tolist(), label = 'Train_Accuracy')
plt.plot(range(len(history['loss'].values.tolist())), history['loss'].values.tolist(), label = 'Train_Loss')
plt.plot(range(len(history['val_accuracy'].values.tolist())), history['val_accuracy'].values.tolist(), label = 'Test_Accuracy')
plt.plot(range(len(history['val_loss'].values.tolist())), history['val_loss'].values.tolist(), label = 'Test_Loss')
plt.xlabel('Epochs')
plt.ylabel('Value')
plt.legend()
plt.show()
结果
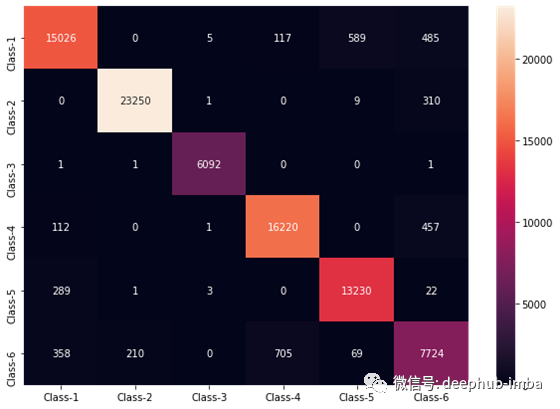
训练后的CNN模型具有96.00%的准确度,让我们看一看混淆矩阵-通常用表格表示来描述分类模型(或“分类器”)对一组已知真实值的测试数据的性能。
pred = model.predict(X_test, batch_size=1204*6, verbose=1)
plt.figure(figsize = (10,7))
classes = [f'Class-{i}' for i in range(1, 7)]
mat = confusion_matrix(np.argmax(y_test, 1),
np.argmax(pred, 1))
df_cm = pd.DataFrame(mat, index = classes, columns = classes)
sns.heatmap(df_cm, annot=True, fmt='d')
plt.show()
分类报告显示准确性以及分类精度,召回率,f1得分和支持。输出如下所示:
# Classification Report
print(classification_report(np.argmax(y_test, 1),
np.argmax(pred, 1),
target_names = [f'Class-{i}' for i in range(1, 7)]))
precision recall f1-score support
Class-1 0.95 0.93 0.94 16222
Class-2 0.99 0.99 0.99 23570
Class-3 1.00 1.00 1.00 6095
Class-4 0.95 0.97 0.96 16790
Class-5 0.95 0.98 0.96 13545
Class-6 0.86 0.85 0.86 9066
accuracy 0.96 85288
macro avg 0.95 0.95 0.95 85288
weighted avg 0.96 0.96 0.96 85288
最后,让我们可视化Sundarbans卫星的分类图。以下代码用于创建分类图。
pred_t = model.predict(X.reshape(-1, windowSize, windowSize, K, 1),
batch_size=1204*6, verbose=1)
# Visualize Groundtruth
ep.plot_bands(np.argmax(pred_t, axis=1).reshape(954, 298),
cmap=ListedColormap(['darkgreen', 'green', 'black',
'#CA6F1E', 'navy', 'forestgreen']))
plt.show()
下图显示了Sundarbans卫星数据的RGB复合图像,真实情况和分类图。

结论
本文介绍了用于卫星图像的土地覆盖分类的各种深度学习方法,并且还展示了3D-CNN在Sundarbans卫星图像的土地覆盖分类中的实现和训练。
可以从下面的GitHub存储库访问本文中使用的代码。
https://github.com/syamkakarla98/Satellite_Imagery_Analysis
作者:Syam Kakarla
deephub翻译组