
当你查看任何社交媒体平台时,你很可能会从其中看到很多建议,例如“为你推荐”。这些建议主要取决于你当前的兴趣,或者取决于以前的类似兴趣,甚至是将来可能会引起你兴趣的内容。这里总结了大多数公司将新产品推荐给客户的两种主要不同方法,它们是:
基于内容的过滤:这种方法的建议与你感兴趣的主题及其属性高度相关。例如:假设你喜欢阿森纳足球俱乐部及其在YouTube上的内容,那么你更有可能看到AFTV,英超联赛等建议,因为所有这些都具有足球,阿森纳等共同的属性。
协同过滤:这更多是基于多个用户及其兴趣的推荐。例如:假设你的朋友喜欢曼彻斯特联队,皇家马德里和英超,而你喜欢阿森纳,巴塞罗那和德甲联赛,那么你的朋友很有可能会收到有关拜仁慕尼黑的建议,而你可能会收到涉及巴黎圣日耳曼的建议,因为你们俩都喜欢足球反之亦然。
因此,我尝试在youtube趋势视频数据集上创建一个基于内容的推荐系统,该数据集从以下Kaggle来源获得:Trending videos 2021,其中我只使用了英国版本。数据集包含主要的特性,如标题,描述,观看统计,喜欢等。下面是数据集的示例:

对于任何涉及文本的机器学习任务,都必须对文本进行处理,并将其转换成数字,让机器进行解释。因为我们将只使用数据集的标题,所以我们将做一些基本的预处理步骤,包括删除特殊字符、降低字符等。下面的代码片段执行所需的预处理步骤。
df_yt = pd.read_csv('/content/GB_videos_data.csv')
df_yt = df_yt.drop_duplicates(subset = ['title'])
df_yt = df_yt[['title', 'description']]
df_yt.columns = ['Title', 'Description']
df_yt['cleaned_title'] = df_yt['Title'].apply(lambda x: x.lower())
df_yt['cleaned_title'] = df_yt['cleaned_title'].apply(lambda x: re.sub('[^A-Za-z0-9]+', ' ', x))
为了创建单词嵌入,我们将使用Tensorflow hub上托管的预训练BERT嵌入,可以将其下载以进行微调,迁移学习等。请访问tf-hub,以获取有关如何使用各种模型的更多说明。在这里,我使用了较小版本的bert un_cased进行预处理,例如去除停用词等。然后使用small_bert预训练的嵌入为数据集中存在的每个标题创建对应于内核的嵌入向量。最终的嵌入将既包含整个序列/标题的合并输出,也包含序列中每个标记的输出,但是在这里,我们将仅使用合并的输出来减少计算能力的使用,并且模型是 无监督学习模型。代码段如下所示:
preprocessor = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3")
encoder = hub.KerasLayer("https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1", trainable=True)
def get_bert_embeddings(text, preprocessor, encoder):
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string)
encoder_inputs = preprocessor(text_input)
outputs = encoder(encoder_inputs)
embedding_model = tf.keras.Model(text_input, outputs['pooled_output'])
sentences = tf.constant([text])
return embedding_model(sentences)
df_yt['encodings'] = df_yt['cleaned_title'].apply(lambda x: get_bert_embeddings(x, preprocessor, encoder))
如你在上面看到的,我为数据集中存在的所有标题生成了编码。因此,我们需要为感兴趣的单词创建编码,并在我们的兴趣和标题的编码之间找到相似之处。我使用余弦相似度来确定向量之间的相似度。简单单词中的余弦相似度是两个给定向量的内积,它的值越大表示两个向量越相似。因此,现在让我们使用各种兴趣来查询数据集,并对余弦相似度得分及其对应的标题进行排名。
def preprocess_text():
text = input()
text = text.lower()
text = re.sub('[^A-Za-z0-9]+', ' ', text)
return text
query_text = preprocess_text()
query_encoding = get_bert_embeddings(query_text, preprocessor, encoder)
df_yt['similarity_score'] = df_yt['encodings'].apply(lambda x: metrics.pairwise.cosine_similarity(x, query_encoding)[0][0])
df_results = df_yt.sort_values(by=['similarity_score'], ascending=False)
让我们假设我们的兴趣为:Action, Hollywood, Thrillers,并查看模型中的相应建议
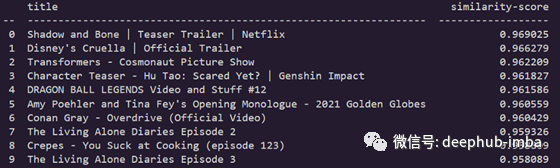
该模型的结果似乎令人满意,其中一些与电影预告片和纪录片有关,其中包含一些含糊不清的内容
现在,让我们针对以下兴趣点看到相同的内容:Arsenal, Europa league, Premier league
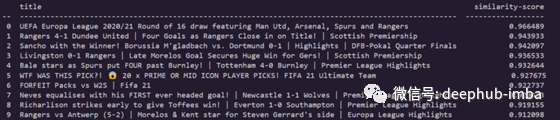
是的,结果与这里高度相关
让我们再检查一次:Music, Taylor Swift, Imagine Dragons
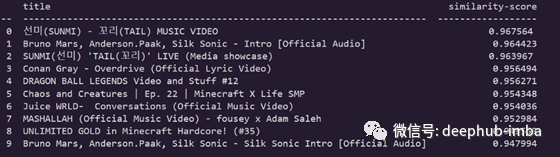
当然,我们的模型可以正常的工作了。
在这里,我们使用youtube标题创建了自己的推荐系统,而这些视频只是英国流行的视频,我们可以利用更多的数据和推荐频道来做得更好,而不是直接推荐视频。谢谢大家花宝贵的时间在阅读本文章上。
作者:Vishnu Nkumar
原文地址:https://medium.com/analytics-vidhya/recommendation-system-using-bert-embeddings-1d8de5fc3c56
deephub翻译组