
什么是双向RNN?
双向RNN是RNN的一种变体,它对于自然语言处理任务特别有用,并且有时可以提高性能。
BD-RNN使用两个常规的RNN,其中一个是顺序数据向前移动,另一个是数据向后移动,然后合并它们的表示。
此方法不适用于时间序列数据,因为按时间顺序表示的含义更抽象。例如,在预测接下来会发生什么时,最近的事件应该具有更大的权重确实是有意义的。
而在语言相关问题中,“tah eht ni tac”和“cat in the hat”显然不应该具有真正的更高的抽象意义。“Tah”和“hat”都指的是同一个物体。
当我们谈论回文,比如“Bob”或“racecar”时,它也是一个非常有意思的问题。
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras import layers
from keras.models import Sequential
max_features = 10000
maxlen = 500
(x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features)
x_train = [x[::-1] for x in x_train]
x_test = [x[::-1] for x in x_test]
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
model = Sequential()
model.add(layers.Embedding(max_features, 128))
model.add(layers.LSTM(32))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
当我们在反向文本上使用相同的模型时,我们得到的结果在准确性方面非常相似。更酷的是这个模型通过学习与前面训练的非常不同的表示来完成任务。
在这里有一个专门的LSTM层对象,它创建了第二个实例(Bidirectional 反向RNN),翻转数据训练它并为我们合并。所以我们不需要为它写代码。
model = Sequential()
model.add(layers.Embedding(max_features, 32))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
并且通过一些正则化,该模型可以达到90%的准确率,这真是太好了。
一个简单的文本处理示例
我们的模型只能区分数值数据,因此我们首先需要将文本数据转换为向量和张量。我们可以在3个不同级别上执行此操作:
- 字符级 Character level
- 单词级 Word level
- 短语级 N-gram level
我们使用并为每个级别其分配唯一的向量。现在,此数字向量已编码为短语,我们可以对其进行编码和解码。这种唯一的抽象被称为令牌,而这个处理的过程称为令牌化(Tokenization)。
例如,一个大型英语语料库的每个字母可能具有26个字符。您可以为每个字符创建一个频率。现在,这26个字符中的每一个都是令牌。
在单词级别,同一语料库可能包含数千个单词。诸如“ the”,“ in”之类的常见词可能会出现多次。但是,尽管如此,我们还是会将每个事件编码为相同的向量。
在n-gram级别(n = 2),我们从每个连续的对中创建一个2个单词的短语。然后,我们可以再次创建频率表,某些二元组可能会出现多次。我们将每个双字母组编码为唯一标记,并使用数字向量对其进行编码。频率表在这里并不重要,我只提供它来说明它的性质。
一旦我们确定了抽象级别(字符,单词,短语)并完成了标记化。我们可以决定如何向量化令牌。我们可以:
- One hot encode
- Token embed
对于独热编码,我们只需计算文本中所有唯一的单词,将其称为N,然后将N下的唯一整数分配给一个单词。只要没有重复就可以,在单词和短语上这样做也是可以的。
One-hot
00000001
00000010
00000100
00001000
00010000
00100000
01000000
10000000
对于单词级别,你可以自己简单地实现它,或者使用预构建的keras方法来实现它:
import numpy as np
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
token_index = {}
for sample in samples:
for word in sample.split():
if word not in token_index:
token_index[word] = len(token_index) + 1
max_length = 10
results = np.zeros(shape=(len(samples),
max_length,
max(token_index.values()) + 1))
for i, sample in enumerate(samples):
for j, word in list(enumerate(sample.split()))[:max_length]:
index = token_index.get(word)
results[i, j, index] = 1.
keras
from keras.preprocessing.text import Tokenizer
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(samples)
sequences = tokenizer.texts_to_sequences(samples)
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
另一件需要考虑的事情是,有时我们可能会在分布方面削减单词的下端,只取最常见的1000个单词。因为这节省了我们的计算时间。
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
在词嵌入中,我们创建的向量看起来更像是[0.243,0.33454,…0.5553],而不是看起来像[0,0,0,…1,0]。
虽然独热编码向量的大小可以为1000,但嵌入向量可以小得多。
但是,我们如何学习向量的这些分数呢?
一般情况下我们会在处理数据的时候一起进行处理,也可以使用预训练的词嵌入。使用嵌入的好处是它们可以学习单词的含义,尤其是经过预训练的嵌入,已经帮我们训练好了单词的含义。
向量映射到几何空间
向量是可以映射到几何空间。如果你把词嵌入向量画进几何空间我们就能看到相关单词之间的几何关系。
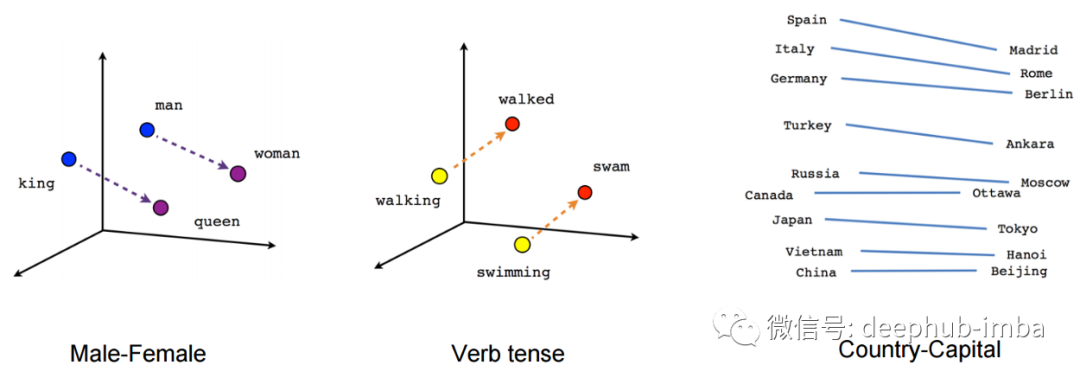
为什么在理论上用你的训练数据或者更接近你手头任务的上下文来训练词嵌入更好?
语言不是同构的,英语和俄语没有相同的映射。存在于一种语言中的特性可能不完全存在于另一种语言中。
此外,在两个英语使用者之间,他们可能不同意词的定义,因此该词与其他词的语义关系。
甚至,同一个人可能会在不同的语境中使用不同的单词。所以语境在语义学中很重要。
词嵌入向量
from keras.layers import Embedding
embedding_layer = Embedding(1000, 64)
1000和64在某种程度上表示你的独热向量有多大以及它们现在有多大。一个独热编码就像数字信号,而嵌入就像连续信号的模拟。只不过它被训练成模拟信号,然后冻结它,把它用作独特数字信号。
我们可以只使用词嵌入和分类器来看看我们得到了什么样的精度:
from keras.datasets import imdb
from keras import preprocessing
max_features = 10000
maxlen = 20
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
from keras.models import Sequential
from keras.layers import Flatten, Dense
model = Sequential()
model.add(Embedding(10000, 8, input_length=maxlen))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
我们得到了76%的准确率。还不错,是吧
使用预先训练的词嵌入呢?
在此之前,我们需要得到标签:
import os
imdb_dir = '/Users/username/Downloads/imdb_dataset'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
Word2vec是第一个也是最成功的预训练的词嵌入。另一个很棒的是GloVe。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
maxlen = 100
training_samples = 200
validation_samples = 10000
max_words = 10000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
如果使用GloVe的话需要手动下载(https://nlp.stanford.edu/projects/glove/),然后:
glove_dir = '/Users/fchollet/Downloads/glove.6B'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
为了说明一些要点,我们首先定义我们的模型:
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
我们需要将embeddings加载到嵌入层中:
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
我们冻结了嵌入层,这样在训练时他的权重不会更新。我们只需要得到他的输出即可
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
现在我们准备训练:
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')
验证精度达到50%左右。我们可以用LSTM或GRU进行改进,甚至可以在LSTM训练后对词的嵌入进行微调。
这里还有一个主要的原因是,我们挑选的200个训练样本太少了。
作者:Jake Batsuuri
原文地址:https://tbatsorry.medium.com/language-processing-with-recurrent-models-4b5b53c03f1
deephub翻译组