大数据分析-零基础学Tableau+超详细讲解+示例练习(三)
零基础学Tableau+超详细讲解+示例练习(三):凸显表、树形图、气泡图、词云图绘制
机器学习笔记一. 特征工程
sklearn 库加载数据集小数据集sk.datasets.load_iris();大数据集sk.datasets.fetch_20newsgroups()数据集返回值datasets.base.Bunch(继承自字 典类型)使用数据集# 数据集使用def datasets_demo(): i
机器学习【西瓜书/南瓜书】--- 第1章绪论(学习笔记+公式推导)
本博客为博主在学习 机器学习【西瓜书/南瓜书】过程中的学习笔记,每一章都是对《西瓜书》、《南瓜书》内容的总结和提炼笔记,博客可以作为各位读者的辅助思考,也可以做为读者快读书籍的博文,本博客对西瓜书所涉及公式进行详细的推理以及讲解,本人认为,不推导公式所学得的知识是没有深度的,是很容易忘记的,有些公式
基于LBP的图像特征提取并PCA降维后的分类研究
基于python写LBP提取图片数据信息,PCA降维数据后进行图片分类
目标检测性能指标(完全版)
目标检测任务的性能指标通常分为两大类,一方面要判断检测是否准确,另外一方面要评估算法是否足够高,具体如下:检测精度:Precision,Recall,Accuracy,F1 Score,IoU(Intersection over Union),P-R curve(Precision-Recall c
大数据分析-零基础学Tableau+超详细讲解+示例练习(二)
零基础学Tableau+超详细讲解+示例练习(二):折线图饼图环形图
Python 数学运算库Numpy入门基础(一)创建数组
安装c:\> pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple官方指南NumPy quickstart — NumPy v1.22 Manualhttps://numpy.org/doc/stable/user/quic
寒假回归篇——C语言学习感悟2022.1.16
Everybody!欢迎来到一飞的博客!没错,历经将近三个礼拜的间隔,我又回来啦!废话不多说,依然是像往常一样!用最朴实的语言为大家分享我在编程路上学习的一点一滴和心得感受!

深入了解 TabNet :架构详解和分类代码实现
Google发布的TabNet是一种针对于表格数据的神经网络,它通过类似于加性模型的顺序注意力机制(sequential attention mechanism)实现了instance-wise的特征选择,还通过encoder-decoder框架实现了自监督学习。
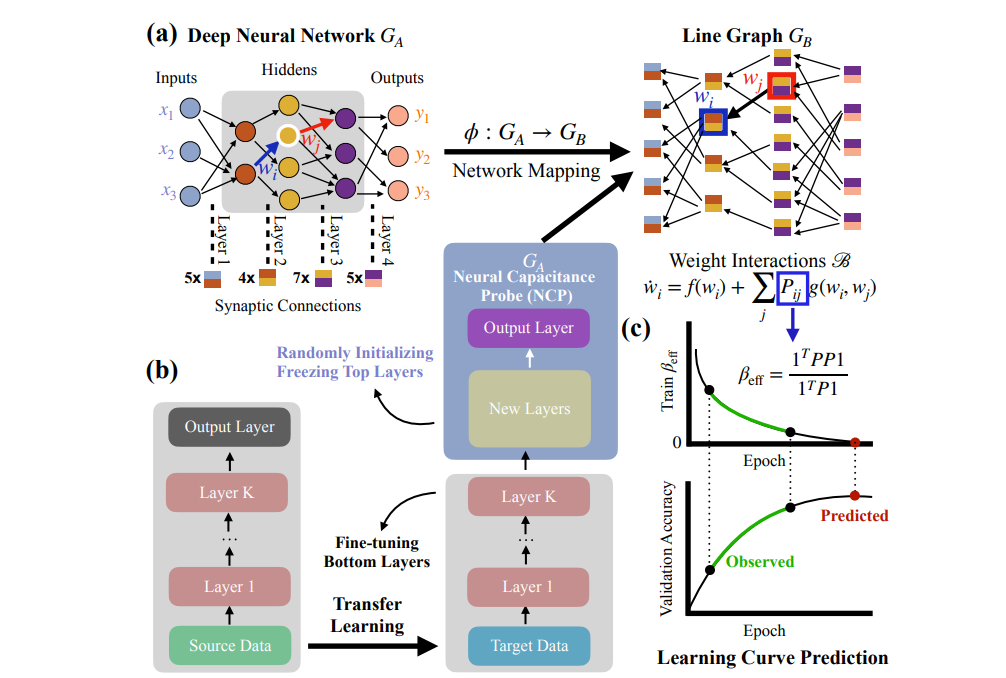
论文推荐:在早期训练阶段预测下游模型性能
22年1月的新论文提出了基于边缘动态系统的神经网络选择的新视角
上手华为云ModelArts | 与人工智能时代共鸣
上手华为云ModelArts | 与人工智能时代共鸣
Numpy 高级
本文其实属于:Python的进阶之道【AIoT阶段一】的一部分内容,本篇把这部分内容单独截取出来,方便大家的观看,本文介绍 NumPy 高级,学习之前需要学习:NumPy入门,关于NumPy和jupyter的安装在 NumPy入门一文中也有想详细的介绍
服务机器人语音对话的实现
基于语音的人机交互是服务机器人交互的最主要表现形式之一,它主要解决以语音作为信息载体,让机器人具有像人一样的“能听会说”的能力,降低使用门槛,且能够解放双手双眼的问题。所以把对话交互功能做好,是服务机器人的基础。交互功能实现步骤包括:麦克风数据采集、麦克风音频降噪和定向、功放声音回馈、关键词唤醒、语
利用seaborn画带数值分布的箱型图
多类别箱型图,分类数据可视化、利用python的seaborn
基于Python的这个库,我实现了“隔空操物“
???? 作者 :“大数据小禅” 大数据领域作者,华为认证云享专家,阿里云专家博主???? 文章简介 :本篇文章的实战部分中主要使用到了 MediaPipe 与 OpenCv 两个库,实现了隔空操作的效果,主要有**隔空操作鼠标,隔空绘画,隔空控制音量与隔空手势识别 **???????? 文章源码
基于OpenBMI的运动想象分类
基于openBMI的运动想象分类,运用的openBMI的MI范式,csp特征提取,LDA分类器,不跨被试的交叉验证。
ConvNeXt:超越 Transformer?总结涨点技巧与理解代码(附注释)
CNN or Transformer?研究证明通过对 CNN 一步步改进也可以达到超越 Transformer 的表现。
AI平民化之路 - 华为云ModelArts和AI Gallery体验指南
在校期间主学机器学习和算法,在一次偶然的机会接触了大数据,而后便入门大数据,至今也从事大数据平台开发工作。可是,仍然对AI技术念念不忘呀,平常也会做点机器学习相关的小东西,尝试一些demo,想着某一天还能回到曾经熟悉的领域,正如我博客名称,从大数据到人工智能。由于我的工作也是平台相关的,所以本次Mo



