
统计估计的一个特征是即使估计量(弱)一致的,他们也可以包含偏差。即随着样本量的增加,估计量的值收敛(概率)为基础参数的真实值,即期望值估计量可能与真实值有所不同。
下面的例子给出了一个有偏估计。假设我们参加一次抽奖,从一个抽奖盒中抽出不同颜色的球,一次一个。我们假设球的总数很大或者每次试验后球都被放回盒中。我们不知道不同颜色的数量,但我们碰巧知道抽签是公平的,因为在每次尝试中,抽到一种特定颜色的概率是固定的,并且独立于颜色。换句话说,颜色在球之间均匀分布。通过观察试验的有限序列(不是全部,而是仅包含在盒子中所包含的球的一个样本)我们可以尝试估算不同颜色的总数,从而可以通过正确猜出所绘制的颜色来估计下一次抽取中的正确的几率。首先,我们可以记下并连续编号观察到的颜色,例如:

如果我们观察上述序列,我们可能会得出以下结论:必须至少绘制K = 4种颜色。通常,在已知K种颜色的未知参数的情况下,观察长度为N的独立试验的序列k 1,k 2,…的可能性计算为:
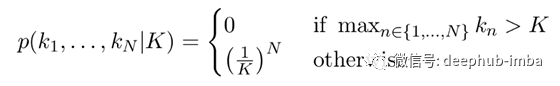
K的最大似然估计(MLE)使该似然最大化:
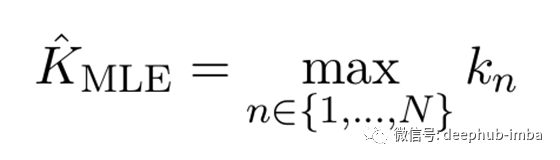
从这个意义上讲,颜色总数的下限K = 4也是颜色总数的最佳估计。
经过多次试验,几乎可以肯定会观察到所有可能的颜色,因此MLE的概率收敛到了真实的参数值:这是一个一致的估计量。但是我们也知道,估计值会系统地低估小样本的真实值。因为很明显,其值永远不会大于试验次数。我们希望明确地计算出这种偏差。设K₀为未知参数的真实值。找到颜色编号的可能性。N次独立试验中的k由下式给出:
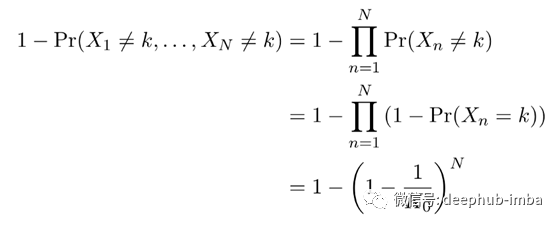
因此,MLE的偏差可计算为:

我们不能仅将这种偏差添加到我们的估计中,因为它取决于我们希望估计的未知参数值。
对于较大的样本量N,上述偏差接近零。但是,我们还看到,对于较大的参数值K₀,不仅对于小样本量而言偏差很大,而且即使对于大样本也非常缓慢地趋近于零。也许我们很幸运,并且对K₀的大小有一些先验知识;也许我们对赢得彩票最有可能的赔率有一些先入为主的观念。包含此类先入之见的标准方法是采用贝叶斯范式,并通过先验概率“校正”可能性:

选择超参数λ,使其最符合我们对K的先验,而后验分布则是在观察到证据后对我们对参数的知识进行建模。范式从惯常论转向贝叶斯论:我们已经从想象K作为具有未知但确定性值的参数转移到K作为随机变量。由于我们缺乏对其“真值”的了解,所以我们选择“随机”(使用引号是因为对于贝叶斯理论来说,这个实体已经放弃了对本体论的承诺)。但是,在本文中,我们不会采用绝对的频率主义或贝叶斯主义,而是提出一种实用的组合。
尽管如此,点估计还是有意义的,因为我们拥有最高可信度,最大的后验估计器(MAP):

形式上,MAP估计器与无信息的MLE相一致,即一致/常数先验。对于信息先验来说,没有一种公认的、“正确的”选择形状的方法,所以我们继续假设它是泊松分布:
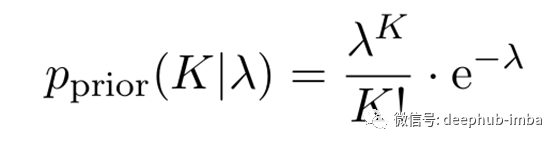
现在,我们可以希望通过先验知识的贡献来纠正偏差。下图显示了从K₀= 25种不同颜色的绘制的模拟图:
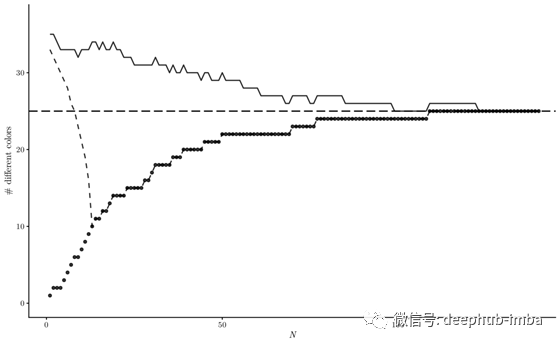
这些点表示MLE与样本大小的关系,样本量总是低估真实值,而且这种偏差对于小样本量来说特别大。虚线表示泊松先验λ = 35的MAP估计。即使先验代表了一个最初的实际高估,仅经过几次试验,最大似然和后验分布有效地吻合。另一方面,实线显示了对这种影响更强的鲁棒性。它表示带有偏差校正似然的MAP估计量。
因此,如果似然估计存在较大的偏差,我们就不能指望先验信息在没有额外修正的情况下有效地补偿。如前所述,纠正偏差并不简单,因为它取决于未知参数。但是,我们可以从先验分布中计算出该参数值的估计值,该估计值可以取代真实参数值,从而得出偏差的估计值:
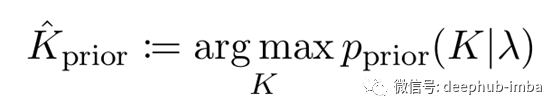
这使我们可以按先验偏差校正的可能性写出后验分布,如下所示:

当我们知道似然估计的偏差是真实参数值(包含样本大小)的函数时,可以使用这个公式。如果不知道解析,可以想象这样的函数可以通过蒙特卡罗模拟产生。
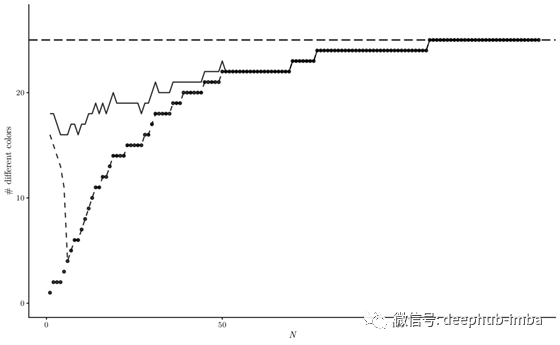
如下图所示,当先前的估计本身具有负偏差(λ= 18)时,经偏差校正的MAP也显示出更高的鲁棒性:λ= 18的MLE与MAP以及经偏置校正的MAP的关系图
总结
对于这个简单的示例,我们已经表明,通过使用先验信息来校正贝叶斯参数估计中似然性的偏差,可能意味着对小样本量的估计的准确性和鲁棒性进行了改进。该技术可以很容易地推广到这个简单示例之外,并且可能在实际应用中很有用。
作者:Matthias Plaue
deephub翻译组