
神经网络机器翻译(NMT)是目前最先进的机器翻译技术,通过神经网络的处理可以产生流畅的翻译。然而非机器翻译模型受到词汇外问题和罕见词问题的影响,导致翻译质量下降。OOV词是语料库中未出现的词,而rare词是语料库中出现次数很少的词。在翻译这些未知单词时,这些单词将被替换为无用的标记。因此,这些无意义的符号破坏了句子结构,增加了歧义使翻译变得更糟。
字符分割是机器翻译中为了避免词层翻译的缺点而采用的一种技术。字符分割的主要优点是它可以对任何字符组成进行建模,从而能够更好地对罕见的形态变体进行建模。但是由于缺少重要信息,因此改进可能不会有太大意义,因为字符级别更细。
为了缓解这些问题,Sennrich等人(2016)通过提供更有意义的表示,引入了将单词分割成子词单元序列的概念。举个分词的例子,看看“look”这个词。这个词可以分为“look”和“ed”。换句话说,用两个向量来表示“looked”。因此,即使这个词是一个未知的词,模型仍然可以通过将它作为一个子词单元的序列来准确地翻译这个词。

随着自然语言处理技术的发展,各种分词算法被提出。以下的子词技术会在这篇文章中进行全面的描述。
- Byte Pair Encoding (BPE)
- Unigram Language Model
- Subword Sampling
- BPE-dropout
字节对编码(BPE)
Sennrich等。(2016)提出了这种基于Byte Pair Encoding压缩算法的分词技术。这是使NMT模型能够翻译稀有单词和未知单词的有效方法。它将单词分解为字符序列,然后将最频繁出现的字符对迭代地组合为一个。
以下是BPE算法获取子词的步骤。
步骤1:初始化词汇表
步骤2:对于词汇表中的每个单词,附加单词标记的结尾</ w>
第3步:将单词拆分为字符
步骤4:在每次迭代中,获取最频繁的字符对并将其作为一个令牌合并,然后将此新令牌添加到词汇表中
步骤5:重复步骤4,直到完成所需的合并操作数量或达到所需的词汇量

Unigram Language Model
Kudo(2018)提出了一种基于Unigram语言模型的子词分段算法,该算法可输出多个子词分段及其概率。该模型假定每个子词独立出现。子字序列x =(x1,...,xM)的概率是通过将子字出现概率p(xi)乘以得到的。

在此,V是预定的词汇。句子X的最可能分割x *由下式给出:
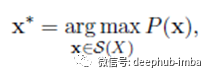
S(X)是使用句子X获得的一组分割候选。x *是通过维特比算法(一种动态规划算法)获得的。
使用期望最大化(EM)算法通过最大化以下似然度L估计子词出现概率p(xi)。
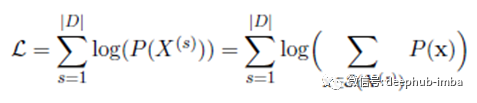
以下步骤描述了获得所需大小的词汇表V的过程。
步骤1:初始化相当大的种子词汇。
步骤2:定义所需的词汇量。
步骤3:通过修正词汇表,使用EM算法优化子词出现概率。
步骤4:计算每个子字的损失。子词的损失表示为:当从词汇表中删除该子词时,上述可能性L会递减多少。
步骤5:按损失对子词进行排序,并保留前n%个子词。子词应使用单个字符,以避免出现词汇问题。
步骤6:重复步骤3至5,直到达到步骤2中定义的所需词汇量。
准备种子词汇的最常见方法是使用语料库中最常见的子字符串和字符。这种基于unigram语言模型的子词分割由字符,子词和词组成。
Subword(子词)采样
在这种技术中,模型是基于unigram语言模型进行多个子词分割的训练,并且在训练过程中概率地对它们进行采样。L最佳分割是一种可用于近似采样的方法。首先,获得l最佳分割,并在执行l最佳搜索之后,对一个分割进行采样。
子字正则化有两个超参数,分别是采样候选的大小(l)和平滑常数(α)。从理论上讲,设置l→∞意味着考虑所有可能的分割。但这是不可行的,因为字符数会随着句子的长度呈指数增长。因此,使用前向过滤和后向采样算法进行采样。另外,如果α小,则分布更均匀,如果α大,则倾向于维特比分割。
BPE-dropout
BPE-dropout是一种有效的基于BPE的子词正则化方法,它可以对特定词进行多次分割。这将使BPE词汇表和合并表保持原始,同时更改分段过程。在此,在每个合并步骤中以p的概率随机删除了一些合并,从而为同一单词提供了多个分段。以下算法描述了该过程。

如果概率为零,则子词分割等于原始BPE。如果概率为1,则子词分割等于字符分割。如果概率从0变到1,它将给出具有不同粒度的多个细分。由于此方法将模型暴露于各种子词分割中,因此可以更好地理解词和子词。BPE删除是一个简单的过程,因为无需训练即可进行训练,而无需训练除BPE之外的任何细分,并且推理使用标准BPE。
引用
- R. Sennrich, B. Haddow, and A. Birch, “Neural Machine Translation of Rare Words with Subword Units,” in Proc. 54th Annual Meeting of the Association for Computational Linguistics, Berlin Germany, Aug. 2016, pp. 1715-1725.
- T. Kudo, “Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates, “ in Proc. 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, July 2018, pp. 66-75.
- I. Provilkov, D. Emelianenko and E. Voita, “BPE-Dropout: Simple and Effective Subword Regularization,” in Proc. 58th Annual Meeting of the Association for Computational Linguistics, July 2020, pp. 1882-1892.
作者:Rashmini Naranpanawa
原文地址:https://rashmini.medium.com/subword-techniques-for-neural-machine-translation-f55e4506a728
deephub翻译组