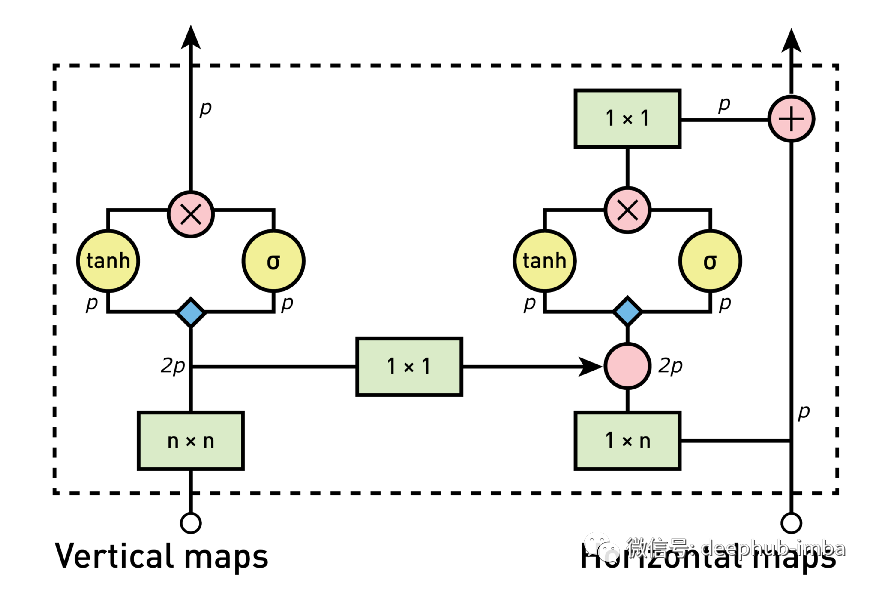
自回归模型PixelCNN 的盲点限制以及如何修复
本篇文章我们将关注 PixelCNNs 的最大限制之一(即盲点)以及如何改进以修复它。
【预测模型】基于麻雀算法改进广义回归神经网络(GRNN)实现数据预测matlab代码
1 简介为实现精准施肥"减施增效"的数字化农业施肥技术,本文基于并运用了麻雀搜索算法,对广义回归神经网络(GRNN)进行了结合与改进,并构建作物广义回归神经网络(GRNN)结合麻雀搜索算法的预测施肥量模型.通过采集得到的数据样本会被用来输入MATLAB进行仿真和实验验证.仿真和实验结果表明,基于麻雀
目标检测进阶:使用深度学习和 OpenCV 进行目标检测
使用深度学习和 OpenCV 进行目标检测基于深度学习的对象检测时,您可能会遇到三种主要的对象检测方法:Faster R-CNNs (Ren et al., 2015)You Only Look Once (YOLO) (Redmon et al., 2015)Single Shot Detecto
谱聚类算法
谱聚类算法小组作业
初识Pytorch使用transforms
首先,这次讲解的tansforms功能,通俗地讲,类似于在计算机视觉流程里的图像预处理部分的数据增强。transforms的原理:说明:图片(输入)通过工具得到结果(输出),这个工具,就是transforms模板工具,(tool=transforms.ToTensor()具体工具),使用工具resu
JavaCV的摄像头实战之十二:性别检测
实现性别检测并在预览窗口实时展现
5分钟 NLP:使用 OpenNRE 进行关系提取
关系提取、知识图谱、实体和 OpenNRE
5个很少被提到但能提高NLP工作效率的Python库
本篇文章将分享5个很棒但是却不被常被提及的Python库,这些库可以帮你解决各种自然语言处理(NLP)工作。
【论文笔记】OPTIPROMPT:用prompt提取预训练模型中的客观事实
目录引言论文介绍1. Continuous prompt2. Prompt是否真的有用思考总结引言像BERT这样的预训练模型学习了大规模语料的词分布,同时也学习了语料中的客观事实。基于这样的直觉,Petroni et al. (2019)提出LAMA模型,首次从BERT中以完形填空的方式提取客观事实
互联网大厂指标体系构建及分析方法
帮助互联网创业公司搭建从0到1的指标体系建设,重点关注第一关键指标(One Metric)、AARRR(海盗)模型;根据自身产品的MVP阶段、增长阶段、变现阶段的划分以及数据的大、全、细、时特点,利用代码埋点、可视化埋点、无埋点等方式进行全部数据源采集,方便后续的多维数据建模及数据分析。
对圆和椭圆进行边缘检测
霍夫梯度:检测的圆与原始图像具有相同的大小检测到的相邻圆的中心的最小距离(如果参数太小,除了一个真实的圆外,还可能会错误地检测到多个相邻圆。如果太大,可能会漏掉一些圆。)在#HOUGH梯度的情况下,它是较高的. 两个阈值传递到Canny边缘检测器(较低的一个小两倍)。在#HOUGH梯度的情况下,它是
0基础搭建ROS智能移动机器人小车
为什么要写这个文章呢,因为我花了999在赵虚左老师的店铺买了他的底盘,然后我想加一层底盘,问客服要一下底盘的一个CAD图,他不给,把我气坏了。然后我想让其他小伙伴少走一点坑。就是这样没错,哈哈。赵老师的课还是不错的。狗头阿克曼底盘价格在219-779元,可以参考自己的钱包差速底盘118-168元下位
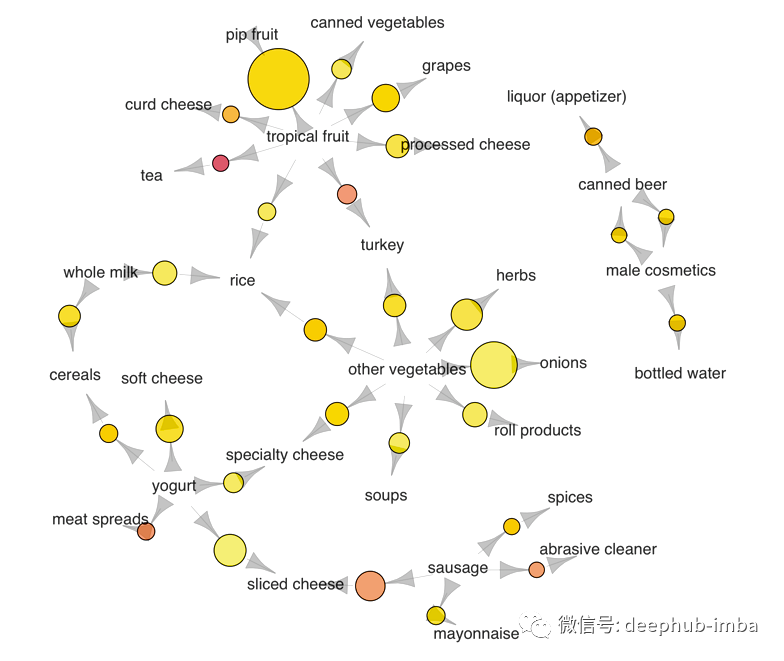
利用关联规则实现推荐算法
关联规则是以规则的方式呈现项目之间的相关性,关联规则的经典例子是通过发现顾客放入其购物篮中的不同商品之间的联系,在医学方面也能够从已有病历中找到患某种疾病的病人的共同特征
程序员的圣诞献礼:AI黑科技带你感受从年少到白头的浪漫!
圣诞节迫在眉睫,你的圣诞礼物准备好了么?不会还在某宝、某书、某博上来来回回翻看依然毫无头绪吧?不愿意陷入送花吃饭看电影老三样,想要清新脱俗又能打动人心?那么,作为浪漫的程序猿/媛,如果你的...
神经网络做MNIST手写数字识别代码
代码(python+pytorch)import torchfrom torchvision import transformsfrom torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.op
作业——机器学习教你预测商品销售额
(一)作业要求advertising.csv文件是某商品的广告推广费用(单位为元)和销售额数据(单位为千元),其中每行代表每一周的广告推广费用(包含微信、微博和其他类型三种广告费用)和销售额。若在未来的某两周,将各种广告投放金额按如下分配,请预测对应的商品销售额:(1)微信:100,微博:100,其
数据挖掘复习要点整理
复习要点:回归课本 个人总结仅供参考简答题:1. Apriori算法主要步骤:2.数据挖掘流程3.数据预处理4.信息熵5.K-Means 聚类算法基本思想:工作步骤:计算题1.朴素贝叶斯2.BP神经网络3.Apriori算法4.代码分析复习要点:回归课本 简答题:1. Apriori算法主要步骤:(
【参赛作品93】openGauss-An Autonomous Database【PVLDB论文阅读分享】
本文基于openGauss在VLDB2021上最新发表的论文《openGauss: An Autonomous Database System》,从学术的角度来探究openGauss如何基于各种AI技术构建一个智能的自治数据库系统。论文作者是清华大学李国良教授,他同时也是openGauss的总架构师
python在球面上随机生成均匀点最简单的方法
python在球面上随机生成均匀点最简单的方法
恒源云_文本数据扩增时,哪些单词 (不) 应该被选择?
文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)原文地址 | 论文笔记原文作者 | Mathor我在,或者我不在,大佬就在那里,持续不断的发文!所以,我还是老老实实的搬运吧!正文开始:文本扩增(Text Augmentation)现在大部分人都在用,因为它可以帮助提升文本分类的效果



