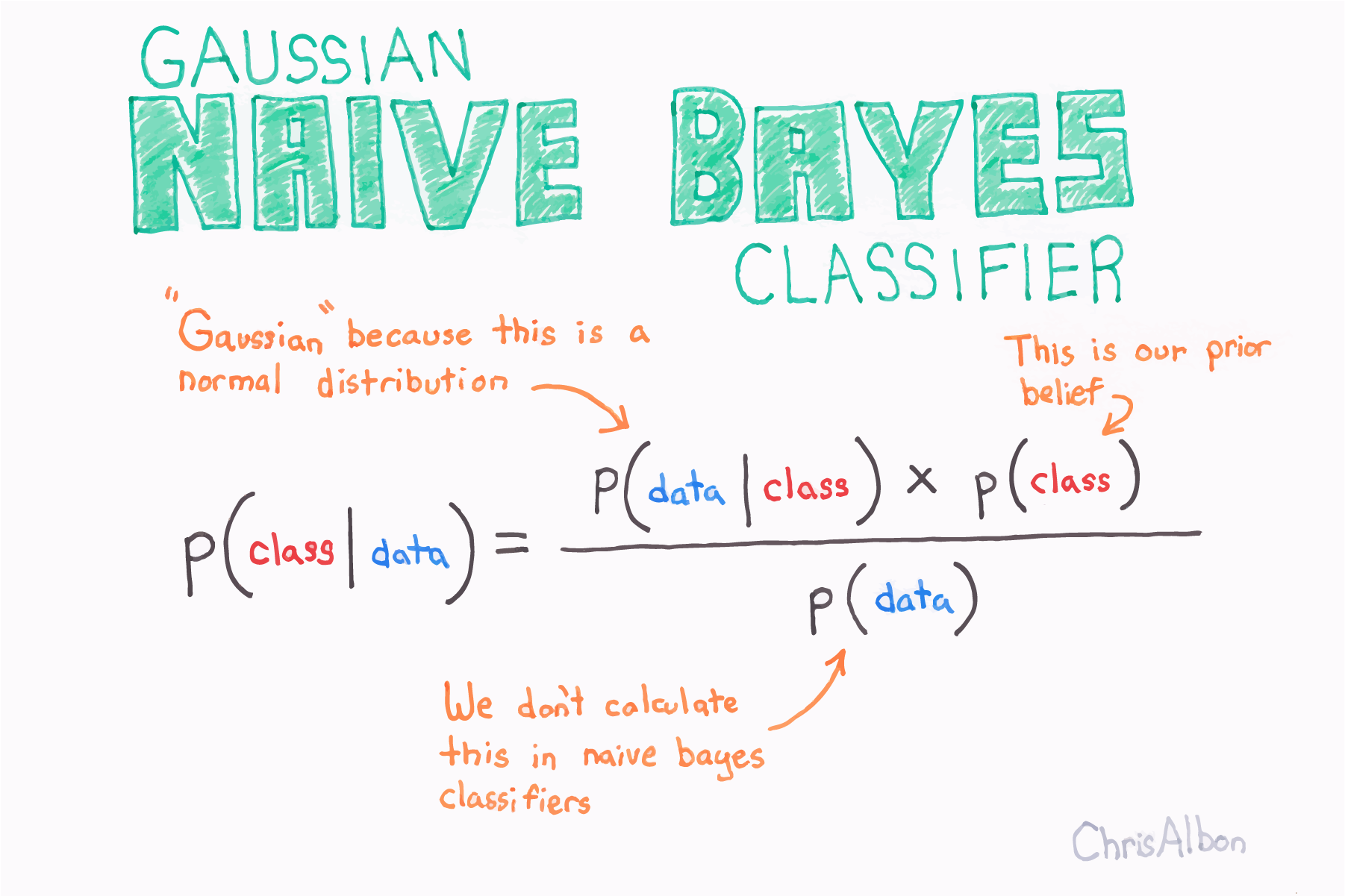
高斯朴素贝叶斯分类的原理解释和手写代码实现
朴素贝叶斯假设每个参数(也称为特征或预测变量)具有预测输出变量的独立能力。所有参数的预测组合是最终预测,它返回因变量被分类到每个组中的概率,最后的分类被分配给概率较高的分组(类)。
数据挖掘 —— 有监督学习(分类)
数据挖掘 —— 有监督学习(分类)1. KNN分类算法2. 决策树分类算法3. SVM算法简介4. 分类——集成算法4.1 随机森林参数介绍4.2 Adaboost算法参数介绍5 总结1. KNN分类算法预备知识:KD-Tree算法 (KDimensional Tree)在空间中寻找与目标点距离最
opencv透视变换,提取特征图像
目录基本介绍cv2.getPerspectiveTransforms介绍cv2.warpPerspective介绍寻找特征图像完整代码及运行效果基本介绍 注意:这篇文章的前提是学过图像仿射变换使用opencv的透视变换可以使我们简单的提取想要的信息,只需要知道原图像的4个点,通过这4个点以及想
机器学习:K-Means算法
机器学习:K-Means算法任务描述数据处理Encoder:归一化:Kmeans前置内容聚类基础概念模型运作方式模型改进方式:任务描述以竞品分析为背景,通过数据的聚类,为汽车提供聚类分类。对于指定的车型,可以通过聚类分析找到其竞品车型。通过这道赛题,鼓励学习者利用车型数据,进行车型画像的分析,为产品
R语言使用is.unsorted函数判断向量数据是否有序
R语言使用is.unsorted函数判断向量数据是否有序
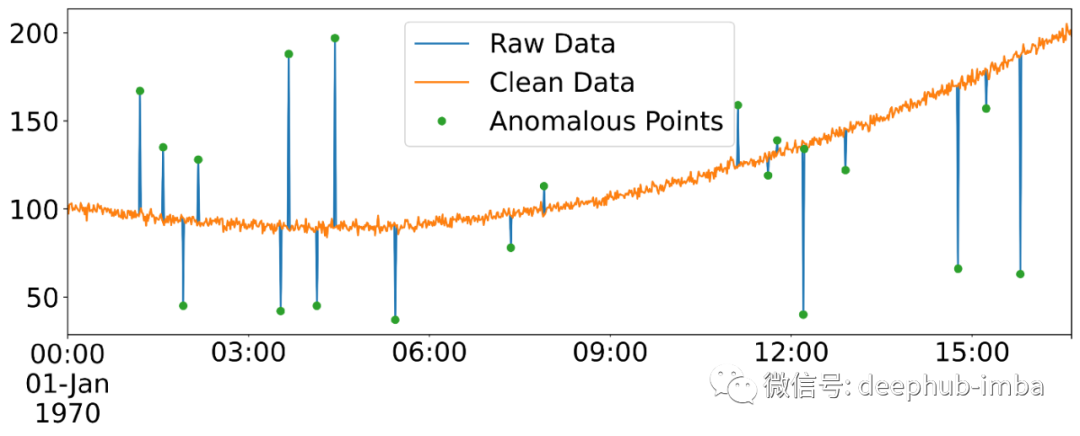
用于时间序列异常检测的学生化残差( studentized residual)的理论和代码实现
学生化这个词其实就是studentized的中文直译,因为约定俗成了所以也没什办法,studentized就是把其他分布转换成t分布,所以其实 studentized residual 翻译为 化残差,要比 学生化残差 更自然,也更好理解
R语言使用barplot函数可视化柱状图、使用因子变量作为x轴坐标标签
R语言使用barplot函数可视化柱状图、使用因子变量作为x轴坐标标签
R语言使用order函数降序排序向量数据、设置decreasing参数进行降序排序
R语言使用order函数降序排序向量数据、设置decreasing参数进行降序排序
机器学习——决策树(一)
决策树;剪枝策略;ID3算法;C4.5算法;CART算法
python 机器学习 sklearn——一起识别数字吧
啊哈哈哈,写了一个数字识别的机器学习,有兴趣的可以看看,附源码

5篇关于强化学习在金融领域中应用的论文推荐
近年来机器学习在各个金融领域各个方面均有应用,其实金融领域的场景是很适合强化学习应用
使用 Python 进行数据清洗的完整指南
在本文中将列出数据清洗中需要解决的问题并展示可能的解决方案,通过本文可以了解如何逐步进行数据清洗。
入门机器学习(西瓜书+南瓜书)神经网络总结(python代码实现)
入门机器学习(西瓜书+南瓜书)神经网络总结(python代码实现)一、神经网络1.1 通俗理解这次的内容较难理解,因此,笔者尽量通过通俗的话来说说清楚什么是神经网络?他是怎么来的?为什么近几年会如此之热?在此基础之上的深度学习,有是怎么回事?下面让我们一步步来揭开神经网络的神秘面纱。神经网络模型其实
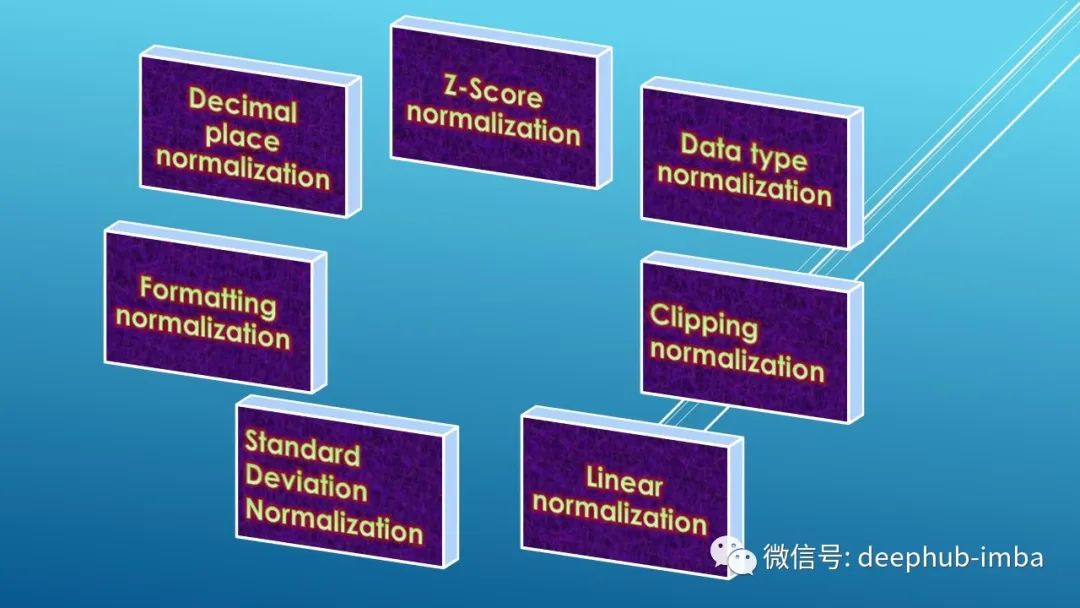
7种不同的数据标准化(归一化)方法总结
本文总结了 7 种常见的数据标准化(归一化)的方法。
程序员的数学【概率论】
本文其实值属于:程序员的数学【AIoT阶段二】 (尚未更新)的一部分内容,本篇把这部分内容单独截取出来,方便大家的观看,本文介绍 概率论,本文涵盖了一些计算的问题并使用代码进行了实现,安装代码运行环境见博客:最详细的Anaconda Installers 的安装【numpy,jupyter】(图+文
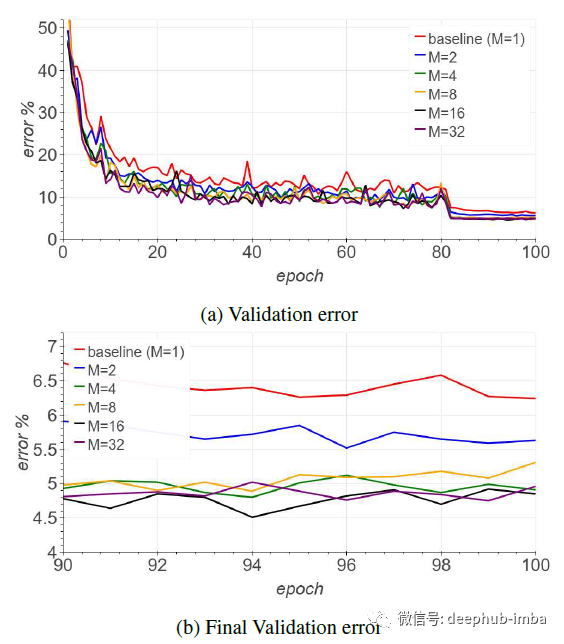
论文回顾:Batch Augmentation,在批次中进行数据扩充可以减少训练时间并提高泛化能力
Batch Augmentation(BA):提出使用不同的数据增强在同一批次中复制样本实例,通过批次内的增强在达到相同准确性的前提下减少了SGD 更新次数,还可以提高泛化能力。
一张照片,AI生成抽象画(CLIPasso项目安装使用) | 机器学习
最近看到一个比较有意思的项目,可以将照片生成对应的抽象画。AI帮你一键生成一张抽象画。
R语言使用names函数将dataframe的数据列名称修改为数据说明标签、而通过数值索引访问dataframe数据列
R语言使用names函数将dataframe的数据列名称修改为数据说明标签、而通过数值索引访问dataframe数据列

特征工程:基于梯度提升的模型的特征编码效果测试
树形结构为什么不需要归一化?使用独热编码和标签编码对模型的表现影响大吗?
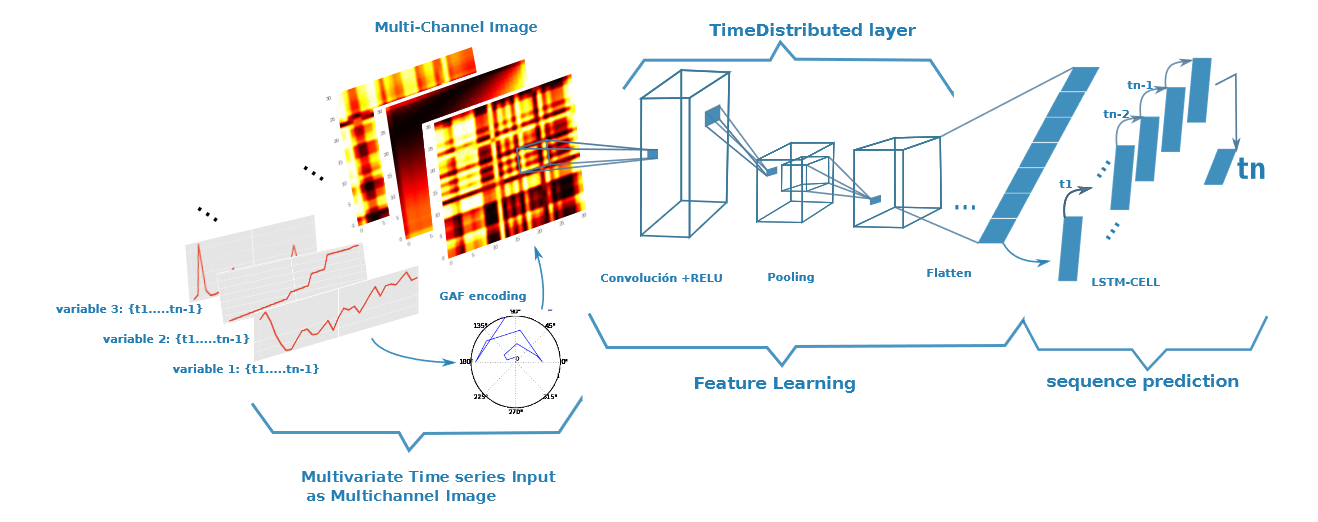
使用格拉姆角场(GAF)以将时间序列数据转换为图像
这篇文章将会详细介绍格拉姆角场 (Gramian Angular Field),并通过代码示例展示“如何将时间序列数据转换为图像”。



