
统计学小抄:常用术语和基本概念小结
统计学是涉及数据的收集,组织,分析,解释和呈现的学科。

Pycaret 3.0的RC版本已经发布了,什么重大的改进呢?
Pycaret是Python中的一个开源可自动化机器学习工作流程的低代码机学习库。 它是一种端到端的机器学习和模型管理工具。要了解有关Pycaret的更多信息,可以查看官方网站或GitHub。
python机器学习从入门到高级:超参数调整(含详细代码)
Python机器学习🌸个人主页:JoJo的数据分析历险记📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生💌如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏在我们选择好一个模型后,接下来要做的是如何提高模型的精度。因此需要进行超参数调整,一种方法是手动处
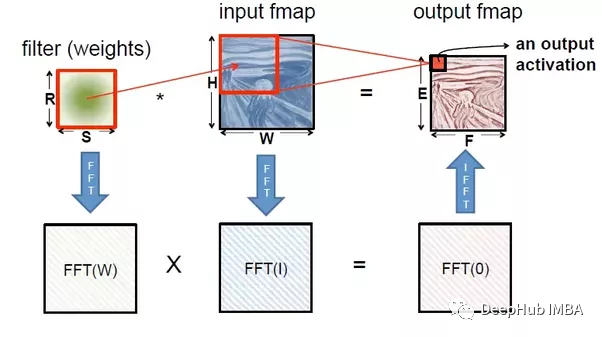
神经网络与傅立叶变换有关系吗?
傅里叶变换可以视为一种有助于逼近其他函数的函数,神经网络被也认为是一种函数逼近技术或通用函数逼近技术。 本文将讨论傅里叶变换,以及如何将其用于深度学习领域。
Python机器学习从入门到高级:模型评估和选择(含详细代码)
之前我们介绍了机器学习的一些基础性工作,介绍了如何对数据进行预处理,接下来我们可以根据这些数据以及我们的研究目标建立模型。那么如何选择合适的模型呢?首先需要对这些模型的效果进行评估。本文介绍如何使用`sklearn`代码进行模型评估
【人工智能】话说人工智能与人工神经网络的历程
人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。那么,它的发展历程是经历了什么过程呢?
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow第2版》-学习笔记(5):支持向量机
第五章 支持向量机· Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition, by Aurélien Géron (O’Reilly). Copyright 2019 Aurélien Géro
机器学习决策树作业
机器学习决策树作业
机器学习之分类方法K近邻(KNN)
详解KNN原理及步骤,针对K值的选取,距离度量法的选择进行说明,并利用sklearn对手写体进行预测。
Python机器学习从入门到高级:玩转日期型数据(含代码)
Python机器学习:日期型数据处理🌸个人主页:JoJo的数据分析历险记📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生💌如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏文章目录Python机器学习:日期型数据处理💮1. 将字符串转换成日期🏵️2.
Micro-Outlier Removal: 一种Kaggle快速提分的小技巧
Micro-Outlier Removal:这个词听起来不错。但是这个术语是本文的作者首创的。所以应该找不到其他相关的资料,但是看完本篇文章你就可以了解这个词的含义。

Pandas 对数值进行分箱操作的4种方法总结对比
使用 Pandas 的between 、cut、qcut 和 value_count离散化数值变量
Python机器学习从入门到高级:带你玩转特征转换(含详细代码)
本文介绍如何使用python进行特征转换,建议收藏!!!本文介绍如何使用python进行特征转换,建议收藏!!!本文介绍如何使用python进行特征转换,建议收藏!!!
[KO机器学习] Day4 特征工程:如何有效地找到组合特征?
本文介绍一种基于决策树的特征组合寻找方法(关于决策树的详细内容过段时间为大家更新)。以点击预测问题为例,假设原始输入特征包含年龄、性别、用户类型(试用期、付费)、物品类型(护肤、食品等)4个方面的信息,并且根据原始输入和标签( 点击 / 未点击 )构造出了决策树,如下图所示。
机器学习系列7 基于Python的Scikit-learn库构建逻辑回归模型
🎄🎄本文中,你将学到逻辑回归的数学原理,使用Seaborn库可视化数据寻找数据间的相关性,并基于Scikit-learn库构建逻辑回归模型预测南瓜颜色。
[机器学习面试] Day3: 什么是组合特征?如何处理高维组合特征?
什么是组合特征?如何处理高维组合特征?难度:★★☆☆☆分析与解答:为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高阶组合特征。以广告点击预估问题为例,原始数据有语言和类型两种离散特征。表1.2是语言和类型对点击的影响。为了提高拟合能力,语言和类型可以组成二阶特征,表1.3
机器学习入门-01快速学会使用Matplotlib绘图
快速学会使用Matplotlib绘图使用Matplotlib的基本功能实现图形显示使用Matplotlib实现多图显示使用Matplotlib实现不同画图种类1. Matplotlib之HelloWorld1.1 什么是MatplotlibMatplotlib 是 Python 的绘图库,它能让使用

1行代码完成可视化:Seaborn3个常用方法示例
只需一行 Seaborn 代码,我们就能够创建最常用的绘图并对其进行自定义,这是我们将在本文中重点介绍的内容。
【机器学习】交叉验证详细解释+10种常见的验证方法具体代码实现+可视化图
【机器学习】交叉验证详细解释+10种常见的验证方法具体代码实现+可视化图一、使用背景由于在训练集上,通过调整参数设置使估计器的性能达到了最佳状态;但在测试集上可能会出现过拟合的情况。 此时,测试集上的信息反馈足以颠覆训练好的模型,评估的指标不再有效反映出模型的泛化性能。 为了解决此类问题,还应该准备
教你通过计算图看懂反向传播
看恩达老师的反向传播视频没有看很明白,于是搜寻发现了宝藏资源**《深度学习入门:基于Python的理论与实现》**,现将书中反向传播部分的内容截取出来供大家参考。图5-15练习答案:...



