
目录:
前言
本文参考书籍:《人工智能原理及其应用》第四版
✨你好啊,我是“ 怪& ”,是一名在校大学生哦。
🌍主页链接:怪&的个人博客主页
☀️博文主更方向为:课程学习知识、作业题解、期末备考。随着专业的深入会越来越广哦…一起期待。
❤️一个“不想让我曾没有做好的也成为你的遗憾”的博主。
💪很高兴与你相遇,一起加油!
一、定义
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
- 是一种归纳分类算法
- 隶属于有监督的学习
- 它通过对训练集的学习,挖掘出有用的规则,用于对新集进行预测。
二、原理
其基于贪心算法,树状结构,层层筛选。
贪心法性质及特点详见文章链接:【算法设计与分析】3、贪心法
1、性质:
- 自上而下、分而治之
- 开始时,所有数据皆在根节点
- 属性都是离散值字段(若其连续,则将其离散化)
- 所有记录用所选属性递归的进行分割
- 属性的选择基于一个启发式规则或者一个统计的度量
2、停止分割
- 一个节点上的数据都是属于同一个类别
- 没有属性可以再用于数据进行分割
三、结构
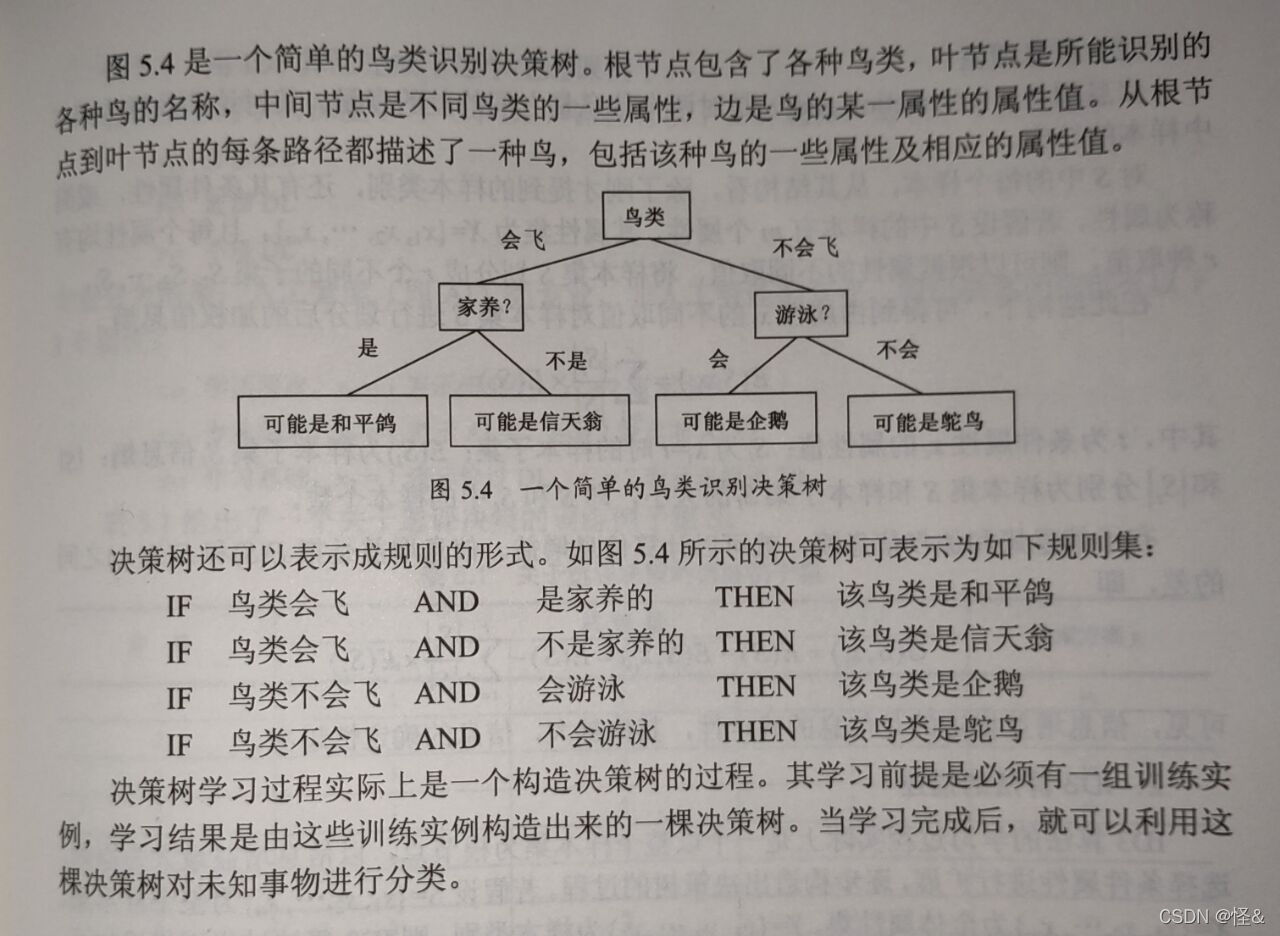
1、结构示例

2、问题示例
四、阶段
1、训练阶段
从给定的训练数据集DB,构造出一颗决策树。
DT = fitctree(data,class)2、分类阶段
从根开始,按照决策树的分类属性逐层往下划分,直到叶节点,获得概念(决策、分类)结果。
y = predict(DT,x)
五、划分优劣的判断
1、不纯性度量
分类划分的优劣用不纯性度量来分析。
对于所有的分支,划分后选择相同分支的所有实例都属于相同的类,则该划分是纯的。2、熵
- 系统愈发混乱,熵愈大
- 若一节点上数据类值在可能的类值上均匀分布,则节点的熵最大
- 若一个节点上的数据的类值对于所有数据都相同,则熵最小
- 决策树通过分裂选择,得到尽可能纯的节点,这相当于降低系统的熵。
六、信息增益

常用算法
1、ID3
2、C4.5
3、CART
意义
1、非参数学习。
2、其实决策树的性能并不是很好,但其逻辑易理解。
3、在集成学习中发挥重要作用。(不同数据训练出不同决策树,多个数量综合其结果。)
本文转载自: https://blog.csdn.net/qq_21471309/article/details/123491101
版权归原作者 怪& 所有, 如有侵权,请联系我们删除。
版权归原作者 怪& 所有, 如有侵权,请联系我们删除。