
在机器学习中,如果我们的样本数量很大,在大多数情况下,首选解决方案是减少样本量、更改算法,或者通过添加更多内存来升级机器。这些方案不仅粗暴,而且可能并不总是可行的。由于大多数机器学习算法都期望数据集(例如常用的 DataFrame)是保存在内存中的对象(因为内存读取要比磁盘读取快不止一个量级),所以升级硬件这种解决方案基本上会被否定。所以科学家们找到的一种既能够保存信息,又节省内存的方案:我们称之为“稀疏矩阵”。

背景
Pandas的DataFrame 已经算作机器学习中处理数据的标配了 ,那么稀疏矩阵的真正需求是什么?答案是空间复杂度和时间复杂度。当涉及数百万行和/或数百列时,pandas DataFrames 变得最糟糕,这时因为 pandas DataFrams 存储数据的方式。例如下面的图,这是 CSV 文件的磁盘和内存大小比较。我们在这里使用的数据集是 Santander Customer Satisfaction 数据集。 途中比较了 CSV 文件在读取为 DataFrame 之前和读取为 DataFrame 之后的磁盘/内存使用情况。
import os
import pandas as pd
#Read csv file
data = pd.read_csv("train.csv")
memory_usage = data.to_numpy().nbytes/1e6
#Read the original file size using os module
disk_usage = os.path.getsize('/content/train.csv')/1e6
#Lets plot results
plt.figure(figsize=(10,8))
plt.bar(x=["CSV","DataFrame"],height=[disk_size,memory_usage])
plt.title("Size comparison - CSV vs DataFrame")
plt.ylabel("Usage (MB)")
plt.show()
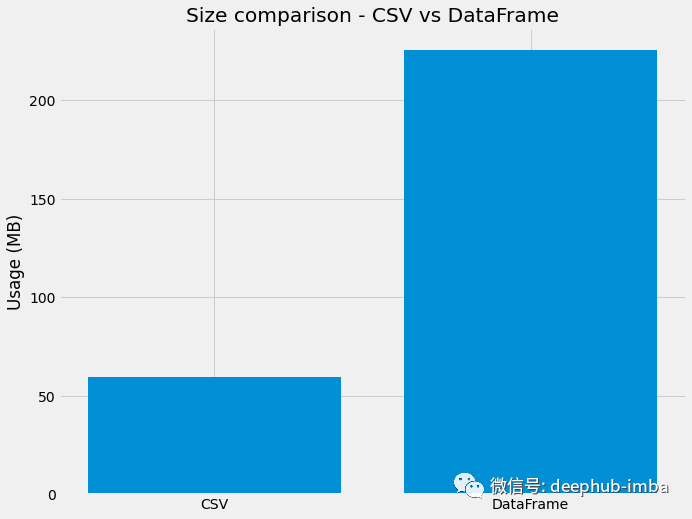
可以明显地看到数据大小的差异,可能是因为里面包含了很多0或者空值导致的,本文后面我们会有详细的分析和介绍
什么是稀疏矩阵?
有两种常见的矩阵类型,密集和稀疏。主要区别在于稀疏指标有很多零值。密集的指标没有。这是一个具有 4 列和 4 行的稀疏矩阵的示例。

在上面的矩阵中,16 个中有 12 个是零。这就引出了一个简单的问题:
我们可以在常规的机器学习任务中只存储非零值来压缩矩阵的大小吗?
简单的答案是:是的,可以!
我们可以轻松地将高维稀疏矩阵转换为压缩稀疏行矩阵(简称 CSR 矩阵)。对于这种压缩我们的要求是压缩后的矩阵可以应用矩阵运算并以有效的方式访问指标,所以CSR并不是唯一方法,还有有更多的选项来存储稀疏矩阵。例如:Dictionary of keys (DOK)、List of Lists (LIL)、Coordinate list (COO)、Compressed row storage (CRS)等。
但是稀疏矩阵的一个主要缺点是访问单个元素变得更加复杂。下面可以为选择不同的方法提供一些参考:
- 如果关心的是高效修改 - 使用 DOK、LIL 或 COO。这些通常用于构建矩阵。
- 如果关心的是有效的访问和矩阵操作 - 使用 CSR 或 CSC
上面说到了很多名词为简单起见我们深入研究一个CSR的示例。考虑下面的矩阵。
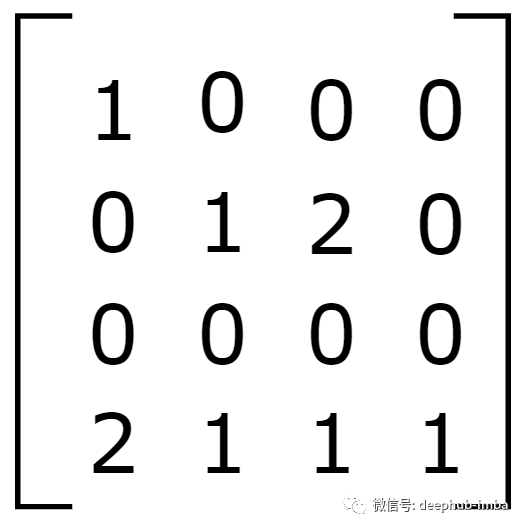
将上述矩阵转换为 CSR 矩阵的情况。在这里使用的是 scipy包的sparsemodule。
import numpy as np
from scipy import sparse#create the metrix with numpy
m = np.array([[1,0,0,0],
[0,1,2,0],
[0,0,0,0],
[2,1,1,1]])
#convert numpy array into scipy csr_matrix
csr_m = sparse.csr_matrix(m)
虽然我们的原始矩阵将数据存储在二维数组中,但转换后的 CSR 矩阵将它们存储在 3 个一维数组中。

值数组 Value array:顾名思义,它将所有非零元素存储在原始矩阵中。数组的长度等于原始矩阵中非零条目的数量。在这个示例中,有 7 个非零元素。因此值数组的长度为 7。
列索引数组 Column index array:此数组存储值数组中元素的列索引。(这里使用从零开始的索引)
行索引数组 Row index array:该数组存储所有当前行和之前行中非零值的累积计数。row_index_array [j] 编码第 j 行上方非零的总数。最后一个元素表示原始数组中非零元素的数量。长度为 m + 1;其中 m 定义为原始矩阵中的行数。
这样上面的矩阵被存储为以下形式:
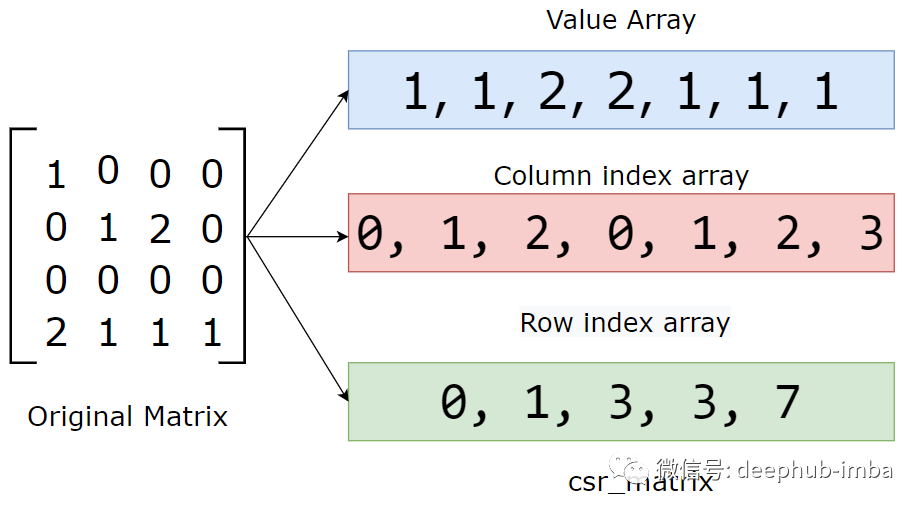
上面两个数组很好理解,但是第三个行索引数组 Row index array看起来就没有那么直观了:
Row index array的数值个数是#row + 1, 表示该行前面值在values的总数,或者说第一个值在values中的位置
咱们依次解释下:
- 第一个值0:前面的values总数是0,也就是values的index起始是0。
- 第二个值1:表示第3行起始,前一行的只有一个非0值,所以前面的values总数是1,也就是values的index起始是1。
- 第三个值3:表示第3行起始,前二行的非0值为3(1,1,2),所以前面的values总数是3,也就是values的index起始是3。
- 第四个值3:表示第4行起始,因为第3行没有非0值,所以非0值的总数还是3
- 第五个值4:没有第5行,所以可以认为这个值是整个矩阵中所有非0值的总数
绘制样本数据
同样我们也可以对稀疏的矩阵进行可视化
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
#read dataset
data = pd.read_csv("train.csv")
#plot samples
plt.figure(figsize=(8,8))
plt.spy(data.head(500).T)
plt.axis('off')
plt.grid(False)
plt.show()

这张图他能告诉我们什么?首先,这里是 plt.spy () 函数的介绍:绘制二维数组的稀疏模式。这可视化了数组的非零值。
在上图中,所有黑点代表非零值。所以可以理解为将这些数据转换为稀疏矩阵是值得得,因为能够节省很多得存储。
那么如何判断数据的稀疏程度呢?使用NumPy可以计算稀疏度。
sparsity = 1- np.count_nonzero(data)/ data.size
print(sparsity)
在我们使用的数据集运行代码后,会得到 0.906 作为稀疏度。这意味着,超过 90% 的数据点都用零填充。回到嘴上面的图,这就是上面我们看到为什么pandas占用内存多的原因。
我们为什么要关心稀疏矩阵?
好吧,使用稀疏矩阵有很多很好的理由。他们主要是,
- 与基本方法相比,可节省大量内存。
- 与传统方法相比,它通常会减少模型训练时间。
sklearn API 中的几乎所有算法现在都支持 csr_matrix 作为输入,这是一个非常好的消息
例如下面:这是来自 sklearn.ensemble.RandomForestClassifier 的示例
X {array-like, sparse matrix} 形状 (n_samples, n_features)
训练输入样本。在函数内部它的 dtype 将被转换为 dtype = np.float32。如果提供了稀疏矩阵,则将其转换为稀疏的 csc_matrix。
让我们继续使用数据集进行实验。
内存压缩比较
def get_mem_usage(train,test,labels=['Train','Test'],plot=True):
"""Helper function for plotting in-disk memory usage for pandas df"""
#get the original memory usage
train_original_size = train.to_numpy().nbytes/1e6
test_original_size = test.to_numpy().nbytes/1e6
#convert into csr_metrix
train_csr = sparse.csr_matrix(train)
test_csr = sparse.csr_matrix(test)
#get memory usage
train_csr_size = (train_csr.data.nbytes+train_csr.indptr.nbytes+train_csr.indices.nbytes)/1e6
test_csr_size = (test_csr.data.nbytes+test_csr.indptr.nbytes+test_csr.indices.nbytes)/1e6
original_sizes = [train_original_size, test_original_size]
sparse_sizes = [train_csr_size, test_csr_size]
if plot:
width = 0.35
x = np.arange(len(labels))
fig, ax = plt.subplots(figsize=(10,8))
rects1 = ax.bar(x - width/2, original_sizes, width, label='Original')
rects2 = ax.bar(x + width/2, sparse_sizes, width, label='Sparse')
ax.set_ylabel('Memory Usage(MB)')
ax.set_title('Memory Usage Comparison'.title())
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
plt.grid(False)
plt.show()
else:
return sparse_sizes+original_sizes
from sklearn.model_selection import train_test_split
#train test split
xtrain,xtest,ytrain,ytest = ( train_test_split(X,y,test_size=0.3,random_state=1997))
#plot compressed memory vs original memory
get_mem_usage(xtrain,xtest)
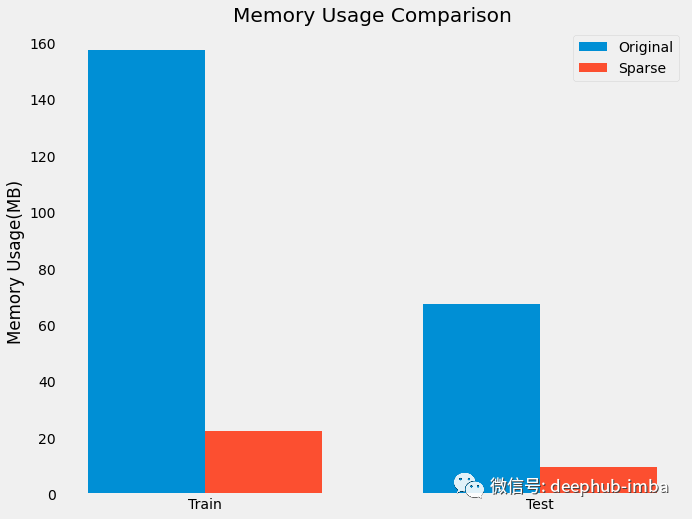
我们的数据集大致压缩为 0.9 倍,上面计算出的数据集的稀疏度也是 0.96,基本类似
通过这个简单的技巧,我们减少了数据集的内存使用量。让我们继续进行模型训练时间比较。
模型训练时间对比
在这里将使用 sklearn API 测试流行的机器学习算法。
LogisticRegression

GradientBoostingClassifier

LinearSVC
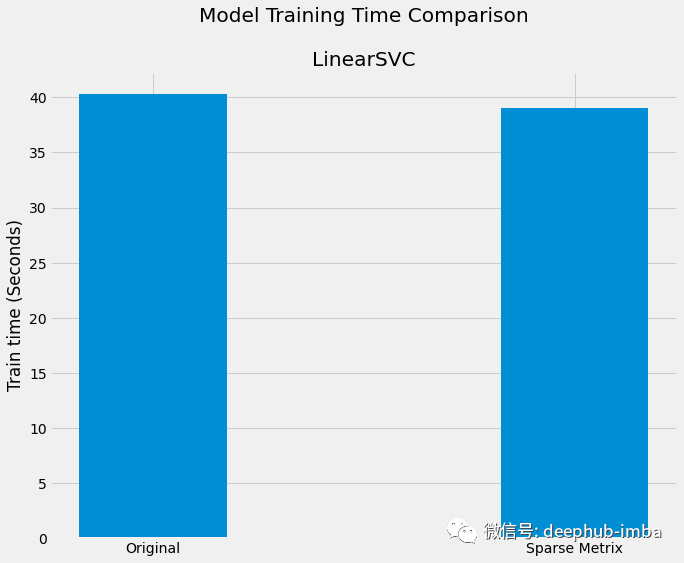
上图中可以看到,LogisticRegression和GradientBoostingClassifier可以明显地提高效率但是,LinearSVC效率不明显,这可能是因为LinearSVC需要投影到更高的维度有关(这个不确定,但是它的算法和LR和GBC不太一样),但是总之,使用稀疏矩阵不仅可以降低内存占用还可以提高训练的效率。
作者:Ransaka Ravihara