
Batch Augmentation(BA):提出使用不同的数据增强在同一批次中复制样本实例,通过批次内的增强在达到相同准确性的前提下减少了SGD 更新次数,还可以提高泛化能力。
Batch Augmentation (BA)
没有 BA 的普通SGD:
一个具有损失函数 ℓ (w, xn, yn) 的模型, {xn, yn} 表示目标对的数据集 ,n 从 1 到 N(是 N 个数据样本),其中 xn ∈ X 和 T:X → X是应用于每个示例的一些数据增强变换,例如,图像的随机裁剪。每个批次的通用训练过程包括以下更新规则(为简单起见,这里使用具有学习率 η 和批次大小 B 的 普通SGD):
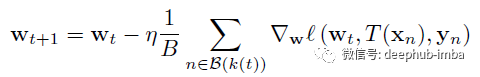
其中 k (t) 是从 [N / B] = {1,…, N / B} 中采样的,B (t) 是批次 t 中的样本集。
SGD和 BA:
BA 建议通过应用变换 Ti 来引入同一输入样本的 M 个多个实例,这里用下标 i ∈ [M] ,以表示每个变换的差异。这样学习规则则变为如下公式:
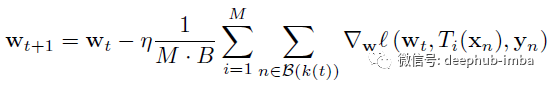
其中 M·B 是由 B 个样本通过 M 个不同的变换进行扩充并进行合并后的一个批次数据,反向传播更新的规则可以通过评估整个 M·B 批次或通过累积原始梯度计算的 M 个实例来计算。使用大批量更新作为批量扩充的一部分不会改变每个 epoch 执行的 SGD 迭代次数。
BA 也可用于在中间层上进行转换。例如,可以使用常见的 Dropout 在给定层中生成同一样本的多个实例。带有 Dropout 的 BA 可以应用于语言任务或机器翻译任务。
实验结果
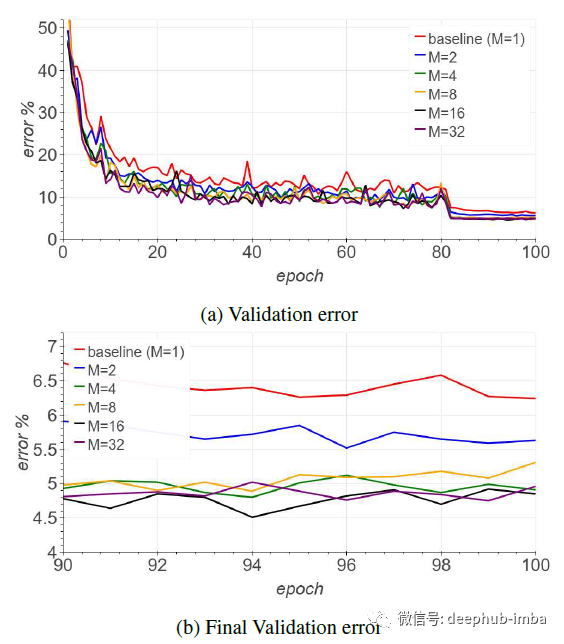
上图显示了改进后的验证收敛速度(以 epoch 计),最终验证分类错误明显降低。随着 M 的增加,这一趋势在很大程度上继续改善,与论文的预期一致。
在实验中,ResNet44 with Cutout 在 Cifar10 上进行训练。ResNet44 仅在 23 个 epoch 中就达到了 94.15% 的准确率,而baseline为 93.07%,并且迭代次数超过了四倍(100 个 epoch)。对于 M = 12 的 AmoebaNet,在 14 个 epoch 后达到 94.46% 的验证准确率,而无需使用任何的 LR 调整策略。
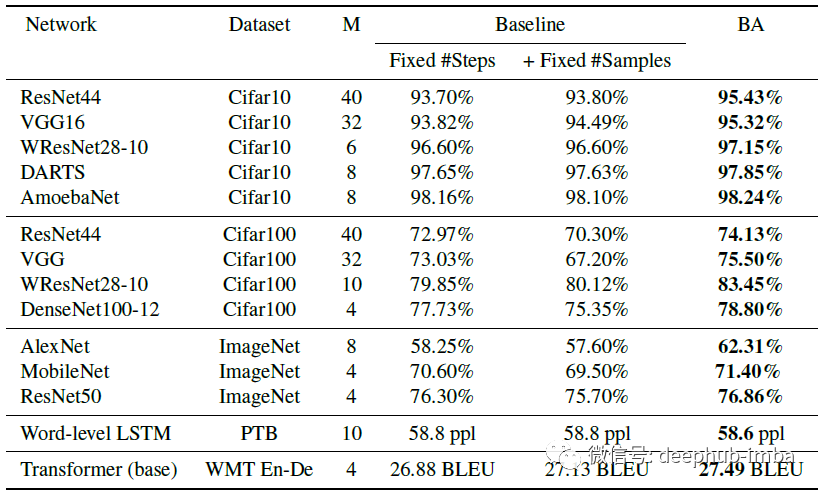
Cifar、ImageNet 模型的验证准确度 (Top1) 结果、测试性能结果和 Penn-Tree-Bank (PTB) 和 WMT 数据集上的 BLEU 分数。
图中的两个基线方案:
(1)“Fixed #Steps” - 与 BA 具有相同训练的原始方案
(2)“Fixed #Samples” - BA 相同数量的样本(使用 M·B批大小)。
PTB 和 WMT En-De为使用 Dropout 的 BA 应用于语言和机器翻译任务,从图上可以看到在 CIFAR、ImageNet、PTB 和 WMT En-De 上使用 BA 都可以提高性能。通过比较“Fixed #Steps”和“Fixed #Samples”,BA 增加批次中的样本对于提高性能至关重要
论文地址:
[2020 CVPR] [Batch Augment, BA]Augment Your Batch: Improving Generalization Through Instance Repetition
作者:Sik-Ho Tsang