图片、视频修复并超分 - Real-ESRGAN项目使用(一) | 机器学习
前段时间一直在弄golang,很少关注一些开源项目。正巧碰到一个,可以将模糊的照片或者视频修复清晰,且可以超分处理的项目。

5分钟NLP:Python文本生成的Beam Search解码
Beam Search不取每个标记本身的绝对概率,而是考虑每个标记的所有可能扩展。然后根据其对数概率选择最合适的标记序列。

GraphMAE:将MAE的方法应用到图中使图的生成式自监督学习超越了对比学习
前几天的文章中我们提到MAE在时间序列的应用,本篇文章介绍的论文已经将MAE的方法应用到图中,这是来自[KDD2022]的论文GraphMAE: Self-supervised Masked Graph Autoencoders

使用Python和OCR进行文档解析的完整代码演示
在本文中将使用Python演示如何解析文档(如pdf)并提取文本,图形,表格等信息。

高斯过程相关研究的新进展的8篇论文推荐(统计 +人工智能)
总结今年5月以来,高斯过程相关研究的新进展
ML:LIME/SP-LIME的简介、原理、使用方法、经典案例之详细攻略
引出LIME—模型需要解释在机器学习应用中,模型的透明度和可解释性,是一种是否值得信任的重要考核标准。模型的what(预测的结果)当然很重要,但是模型whytodo(为什么这样预测)更重要,尤其是模型在上线后,需要及时、准确地告诉业务人员如何营销,告诉风控人员如何识别风险点等等。金融风控领域,在19
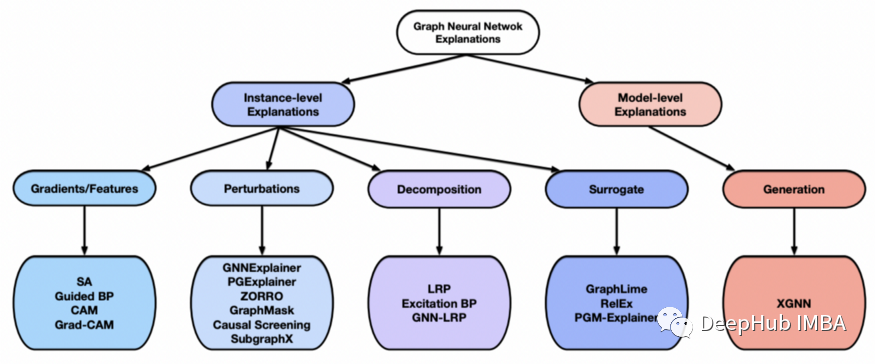
图神经网络的可解释性方法介绍和GNNExplainer解释预测的代码示例
深度学习模型的可解释性为其预测提供了人类可以理解的推理。本文将总结图神经网络模型的可解释性方法。
备赛笔记:神经网络
信息熵为信息量的量度,对于事件x的信息熵为-log(p(x)),x发生概率越小,信息熵越大,信息量越大。1独热矢量(one-hotvector)样本本身人为打的标签,这里相当于对样本分类,某一样本在这一类概率为1,其他概率为0,标签矩阵维数代表分类数量。监督学习(supervisedlearning
机器学习实战运用:速刷牛客5道机器学习题目
能使用机器学习算法模型的业务场景还是很少的,而且检验成本高,一般是建模比赛或者是其他相关赛事才能用到机器学习模型,而且衡量模型质量检测也是个问题。我们在学习阶段比较难应用到部分算法而且仅参照书本上少数例子很容易遗忘,在网上搜索有关机器学习算法练习的时候发现牛客正好有此题目分类,但是题目量比较少仅有五
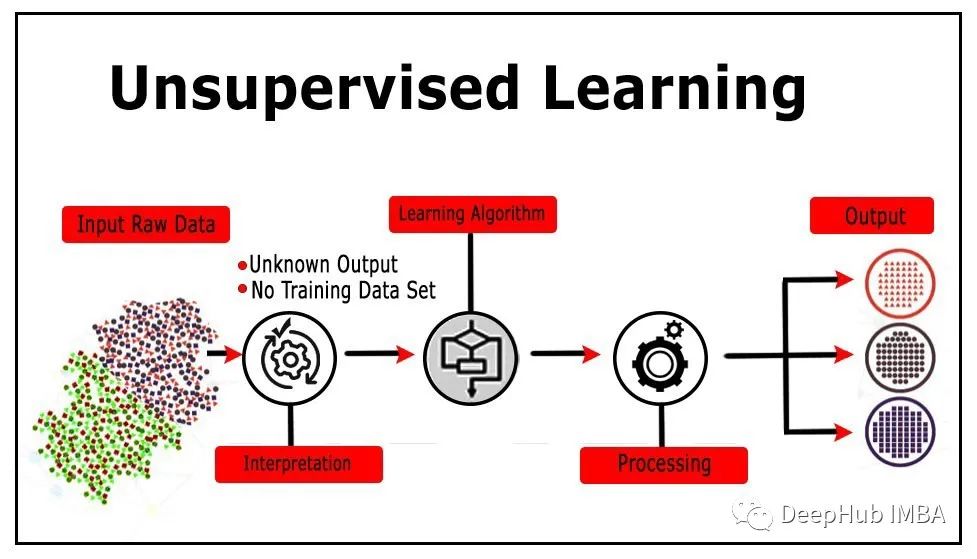
无监督学习的12个最重要的算法介绍及其用例总结
无监督学习(Unsupervised Learning)是和监督学习相对的另一种主流机器学习的方法,无监督学习是没有任何的数据标注只有数据本身。
AI遮天传 ML-无监督学习
无监督学习入门。
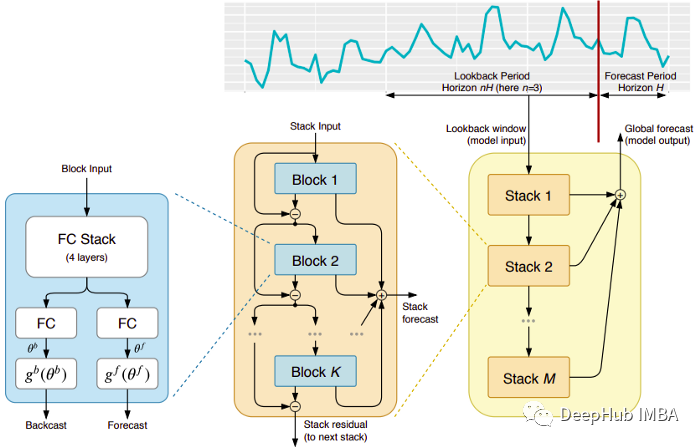
5个时间序列预测的深度学习模型对比总结:从模拟统计模型到可以预训练的无监督模型
时间序列预测在最近两年内发生了巨大的变化,尤其是在kaiming的MAE出现以后,现在时间序列的模型也可以用类似MAE的方法进行无监督的预训练
空间转录组 STAGATE
空间转录组论文STAGATE简介与代码介绍
以数据为中心和模型为中心的AI是贝叶斯论和频率论的另一种变体吗?
在这篇文章中,我将对这两种方法提供一个新的视角。我将从统计的角度来看它们,看看它是否可以阐明哪种方法更好以及在什么情况下更好。
机器学习强基计划0-1:教程导读
订阅专栏前,请先看本文章简介
深度学习第一周总结
机器学习概述,Pytorch基础,Sprial Classfication
两个简单的代码片段让你的图表动起来
使用 plotly 和 gif库 在 Python 中创建动画图
SVM(Support Vector Machines)支持向量机算法原理以及应用详解+Python代码实现
博主大大小小参与过数十场数学建模比赛,SVM经常在各种建模比赛的优秀论文上见到该模型,一般直接使用SVM算法是比较少的,现在都是在此基础理论之上提出优化算法。但是SVM的基础理论是十分重要的思想,放眼整个分类算法中,SVM是最好的现成的分类器。这里说的‘现成’指的是分类器不加修改即可直接使用。在神经
机器学习笔记(十三)-异常检测
异常检测
【MOCO基础】Pointer Networks原理及代码实现分析(Oriol Vinyals, 2015)
Pointer Networks天生具备输出元素来自输入元素这样的特点,于是它非常适合用来实现“复制”这个功能,这就造成了目前Ptr-Nets成为文本摘要方法中的利器的局面。此外,在组合优化领域,Ptr-Nets也得到了广泛的应用,并已成为组合优化问题的端到端方法的入门模型,后来基于此模型,研究者也



