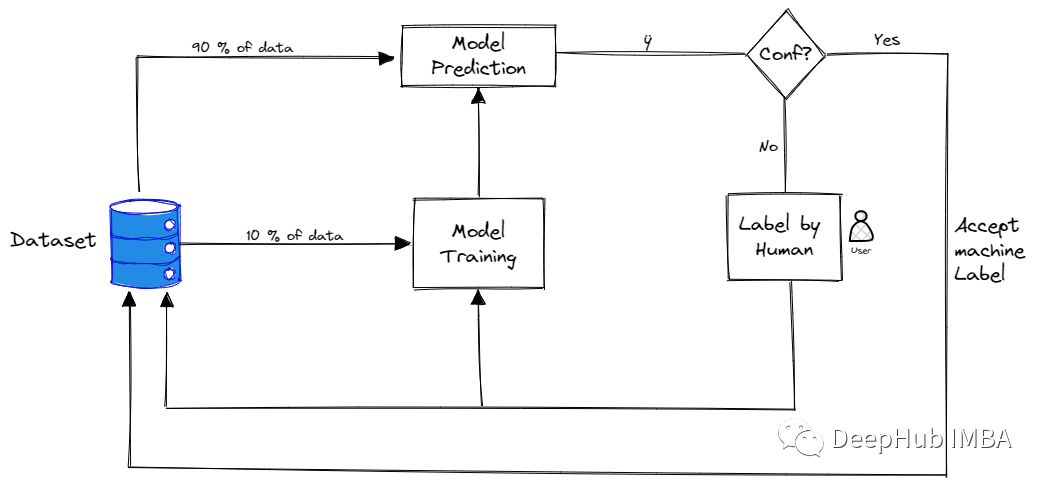
主动学习(Active Learning) 概述、策略和不确定性度量
主动学习是指对需要标记的数据进行优先排序的过程,这样可以确定哪些数据对训练监督模型产生最大的影响。
DeOldify实现老照片上色(附直接使用的工具代码) | 机器学习
老照片上色其实很早之前就想写了,也有不少人问了我这个项目。最近把DeOldify项目好好弄了弄。
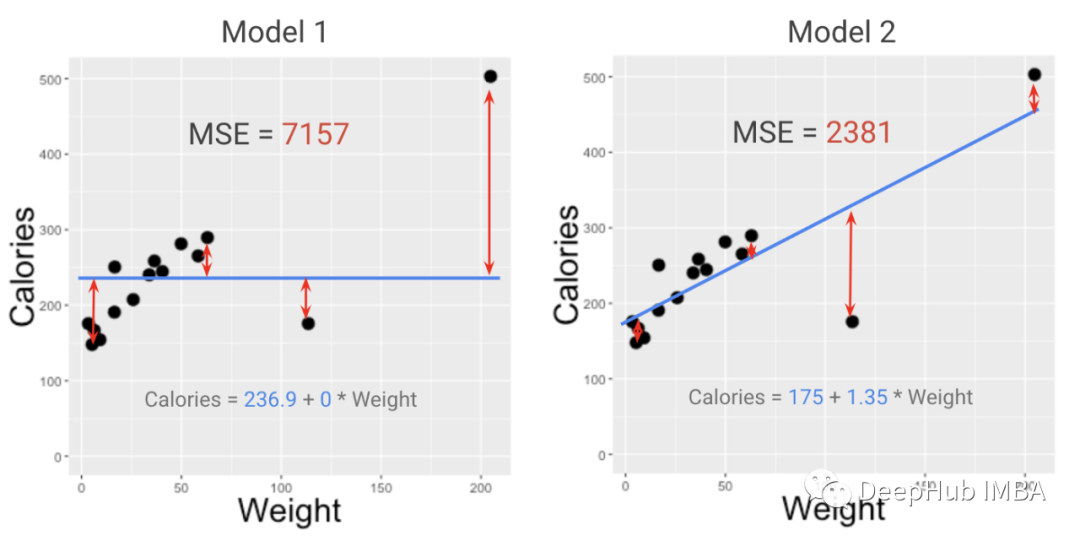
模型的度量指标和损失函数有什么区别?为什么在项目中两者都很重要?
在本文中,我将解释为什么需要两个独立的模型评分函数来进行评估和优化……甚至还可能需要第三个模型评分函数来进行统计测试。
ML之ME:分类预测问题中评价指标(AP/mAP)的简介、使用方法、代码实现、案例应用之详细攻略
ML之ME:分类预测问题中评价指标(AP/mAP)的简介、使用方法、代码实现、案例应用之详细攻略目录评价指标(AP/mAP)的简介1、AP的简介2、AP的理解3、AP与mAP区别及意义评价指标(AP/mAP)的案例应用1、具体比赛场景下的特殊定义(1)、AP (Average Precision)i
即将步入大四,开始我最真情的告白
大一下学期加入机器人实验室,开始接触ROS,从装Ubuntu双系统开始,就开始令我难忘的学习生活,开始学习ROS,学习古月老师的ROS入门21讲,后来有问题,就常常在CSDN上找答案,跟着师哥师姐做实验室的项目,在这个学习的过程中有想过放弃,有过滑水摸鱼,觉得自己是老师和师哥师姐的打工人,是给他们干
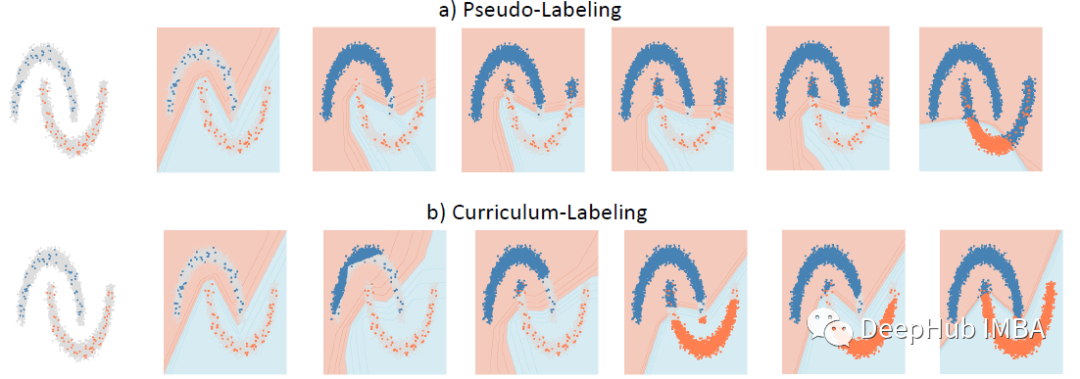
Curriculum Labeling:重新审视半监督学习的伪标签
Curriculum Labeling (CL),在每个自训练周期之前重新启动模型参数,优于伪标签 (PL)
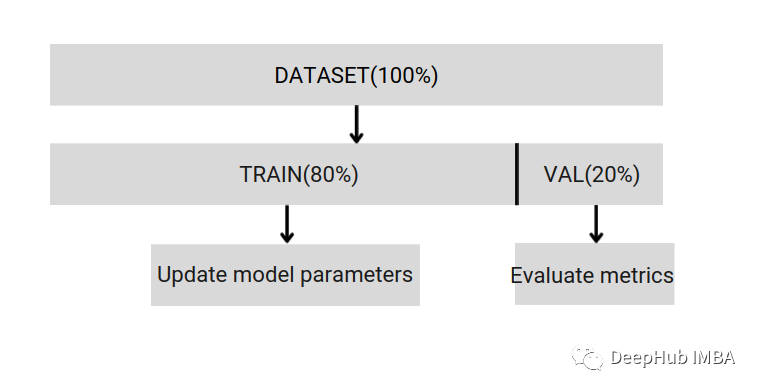
如何正确拆分数据集?常见的三种方法总结
拥有适当的验证策略是成功创建良好预测,使用AI模型的业务价值的第一步,本文中就整理出一些常见的数据拆分策略。

联合概率和条件概率的区别和联系
本文解释联合概率和条件概率之间区别和联系
快速上手数据挖掘
数据挖掘是一项应用十分广泛的技术,它能够从历史数据中发掘出有用的规律,然后运用规律去做预测。比如在金融机构中通过挖掘历史用户信息和违约之间的规律进行风险预测,防止坏帐;在营销场景中可以通过挖掘客户消费行为规律寻找潜在客户,进行精准营销;在企业生产中,可以根据历史生产数据来预测良品情况,从而改进工艺降

使用神经网络模型创建一个龙与地下城怪物生成器
龙与地下城(DND)于1974年发行第一版,现在所有RPG游戏都有它的影子,在本文中我们将使用神经网络构建一个能够生成平衡数据的怪物生成器

数据科学的面试的一些基本问题总结
在这篇文章中,将介绍如何为成功的面试做准备的,以及可以帮助我们面试的一些资源。
Machine Learning with Matminer(附代码)
Machine Learning with Matminer(附代码),Matminer是一个开源的、基于python的软件平台,以促进数据驱动的方法来分析和预测材料的属性。
【机器学习】浅谈正规方程法&梯度下降
【机器学习】浅谈正规方程法&梯度下降数据模型为线性回归模型,方程代价函数。代价函数就是实际数据与数学模型(这里是一元一次方程)所预测的差值,如:蓝线的长度就是代价函数,可以看到代价函数越大拟合效果越差,代价函数越小,拟合效果越好。其中关于 θ1\theta_1θ1 的的代价函数f(θ1)f(\th
【机器学习】梯度下降之数据标准化
吴恩达机器学习笔记在线性回归中,尤其是多变量回归模型,由于各个的数据之间量化纲位不同,如果数据范围分别是是【0~1000,0 ~5】或者【-0.00004 ~ 0.00002,10 ~ 30】, 那么在使用梯度下降算法时,他们的等高线是一个又窄又高的等高线,如下图:因为一个他们量化纲位不同会出现
KMean算法精讲
KMeas算法是一种聚类算法,同时也是一种无监督的算法,即在训练模型时并不需要标签,其主要目的是通过循环迭代,将样本数据分成K类。
浅谈sklearn中的数据预处理
sklearn中的数据预处理
机器学习之数据处理与可视化【鸢尾花数据分类|特征属性比较】
大部分的机器学习模型所处理的都是特征,特征通常是输入变量所对应的可用于模型的数值表示。大部分情况下,收集得到的数据需要经过处理后才能够为算法所使用。通常情况下,一个数据集当中存在很多种不同的特征,其中一些可能是多余的或者与我们要预测的值无关的,可通过数据处理和可视化进行筛选。特征选择技术的必要性也体
点标注、像素级视觉任务、Ground Truth
机器学习名词
5.1补充 源码安装move_base和navigation
前文给出了2进制安装2个包的方法,使用简单但不支持源码的查看和修改。此文给出源码安装方案。
ROS从入门到精通(零) 教程导读
ROS概念太多太复杂?ROS从入门到精通系列教程导读



