
目录
团队博客: CSDN AI小组
1. 背景
CSDN 每天都会产生数以万计的博客数据,但是这些数据没有难度等级的体系结构,这种体系结构在 个性化推荐、用户画像、榜单 等业务上都有很大的作用和价值。
本文主要阐述如何从头开始构建一个难度等级分类框架,用于实现博客在 初级、中级、高级 三个类别上的分类。
在实现方法上,由于精确的标注数据难以获取,故本文根据各个时间阶段的特点,分别使用不同的方法,逐步提升分类的效果。
2. 方法
本文的框架根据框架构建的不同阶段,主要分为以下 3 个部分。
2.1 规则:快速实现
第 1 部分是规则构建,规则可以拉通整个流程,在保证精确率(Precision)的前提下,实现部分博客数据的难度等级分类。
具体而言,通过观察博客样本发现,标题中的某些关键词或模式能够明确地体现文章的难度等级,我们称之为强规则。通过对 初级、中级、高级 三个等级强规则的归纳,可得出以下规则 (为了便于说明问题,下面展示的是简化的规则)
初级类别强规则
primary_level_pat = re.compile(r'初级|初阶|入门|基础|错题集|练习|课后习题|习题答案|学习笔记|考试复盘|每日一练|每日一题|每日真题|管理系统|管理平台|常见|常用|环境搭建|安装|随手记|随记|打卡|踩坑|小技巧')
中级类别强规则
middle_level_pat = re.compile(r'((?:(?:中级|架构|构架)(?!.*?(?:师|岗)))|(?:中阶|进阶|深入))')
高级类别级强规则
high_level_pat = re.compile(r'高级(?!.*?(?:师|岗))|高阶(?!函数)|论文')
基于以上规则,通过对博客标题的正则匹配,可快速实现博客难度等级的判断
defstrong_rules_4_level(title):''' 博客难度等级分类强规则 '''
rule_level =None
kw_list =None# 初级
kw_list = primary_level_pat.findall(title)if kw_list:
rule_level ="1"
kw_list =list(set(kw_list))return rule_level, kw_list
# 中级
kw_list = middle_level_pat.findall(title)if kw_list:
rule_level ="2"
kw_list =list(set(kw_list))return rule_level, kw_list
# 高级
kw_list = high_level_pat.findall(title)if kw_list:
rule_level ="3"
kw_list =list(set(kw_list))return rule_level, kw_list
return rule_level, kw_list
此外,对于低质量的博客可直接判定为初级类别。博客质量分的计算逻辑请参考 博客质量分计算(二),质量分取值 {0, 1, 2, 3, …, 100},当质量分小于 20 分时,判定为低质量博客。
优化:实现落地快、精确率(Precision)高、可解释性强。
缺点:缺乏体系结构、覆盖率和召回率(Recall)低(泛化能力差)。
2.2 匹配:结构化知识体系
第 2 部分是结构化知识数据体系的融入。在第 1 部分中,通常只能通过观察样本数据的方法,构建极其简单的规则集合。这种规则集合通常比较简单朴素、缺乏体系性,而体系结构需要领域专家才能构建。因此,为了进一步提升难度等级分类的效果,本文引入由领域专家构建的 CSDN 技能树,并基于匹配的方法,实现博客难度等级的分类。
技能树体系结构示例如下所示 (C语言技能树简化版)
C语言
├── C语言初阶
│ ├── C语言概述
│ │ ├── C语言发展史
│ │ ├── C语言特点
│ │ └── 编程机制
│ ├── 数据类型
│ │ ├── 变量
│ │ ├── 常量
│ │ └── 基本数据类型
│ └── 语句与控制流
│ ├── 语句与程序块
│ ├── 判断语句
│ └── 循环语句
├── C语言中阶
│ ├── 函数与程序结构
│ │ ├── 函数的声明与定义
│ │ ├── 函数的调用
│ │ └── 函数的递归
│ ├── 数组
│ │ ├── 一维数组
│ │ ├── 二维数组
│ │ └── 变长数组
│ └── 指针
│ ├── 指针与地址
│ ├── 指针与函数参数
│ └── 指针与数组
└── C语言高阶
├── 结构体
│ ├── 结构体数组
│ ├── 结构体指针
│ └── 链式结构
├── 预处理器
│ ├── 宏定义
│ ├── 条件编译
│ └── 内联函数
└── 存储管理
├── 存储类别
└── 内存动态管理
本文根据博客的标签或标题中某些关键词,通过标签或关键词 和 技能树之间的映射关系,判断与当前博客最相关的技能树,映射关系表如下所示 (以C语言技能树为例)
{"tree_name":"c","keywords":["C语言","C/C++","结构体",...]}
确定技能树之后,使用技能树匹配算法,计算博客和技能树中知识点的相似度,具体方法请看 CSDN问答标签技能树(二) —— 效果优化 中的 2.2 匹配算法效果优化。在匹配到最相似的知识点后,通过该知识点的难度等级,进而得出文章的难度等级。
优点:权威、可解释性强。
缺点:知识构建需要耗费大量人力物力。(当前已上线的技能树还未覆盖所有的领域)。
2.3 分类:弱监督学习
第 3 部分是基于弱监督学习的分类模型的使用。分类方法 可以缓解第 1 部分中泛化能力差的问题,以及第 2 部分中知识体系不完善的问题。
训练分类模型需要大量的标注数据,为了降低数据标注带来的人力物力的消耗,本文使用弱监督学习的方法实现难度等级的分类。
具体而言,在博客数据中,有一部分数据用户自己标注了难度等级,但由于每个人对难度等级体系的认知存在差异,导致数据集中存在较多的噪声,为了缓解该问题,本文使用数据编辑(data-editing)的方法优化数据集 (参考论文 A brief introduction to weakly supervised learning),提升数据集的质量。详细步骤如下所示:
- (1) 向量化:使用 TF-IDF 算法对数据集中所有的博文样本(博客标题)进行向量化;
- (2) 图构建:以博客样本为节点,样本之间的相似度为边权重,构建样本关系图;
- (3) 数据编辑: - a) 对于一个节点,如果 top_n 的相邻节点都是同一类别,且与当前节点的类别一致,直接加入到新的数据集中;- b) 对于一个节点,如果 top_n 的相邻节点都是同一类别,且与当前节点的类别不一致,将标签修改为相邻节点的类别后,加入到新的数据集中;- c) 其他情况的节点,直接舍弃。
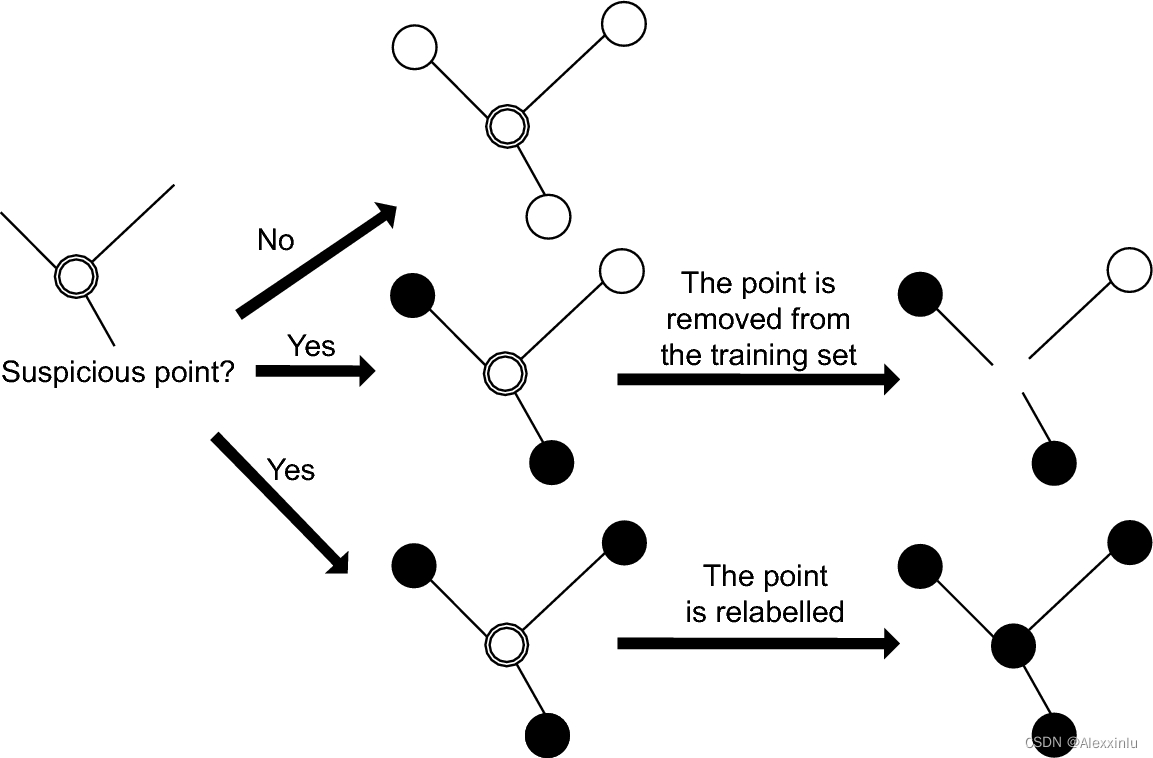
图1. 数据编辑
得到优化后的数据集之后,直接使用
sklearn.ensemble.RandomForestClassifier
分类器实现博客样本的分类。
优点:成本低、泛化能力较强。
缺点:弱监督效果的可信度较低。
2.4 融合:各尽其能
以上三种方法分别有不同的优缺点,通过特定的融合策略可以实现不同方法的互补,发挥各种方法优点的同时,弱化缺点。具体策略如下:
- (1) 对于强规则方法识别的样本,直接使用强规则的结果;
- (2) 对于有匹配结果(相似度得分)的样本,与分类概率值进行加权融合;
- (3) 对于没有匹配结果的样本,直接通过分类概率进行判定。
使用上述策略,a) 可充分发挥强规则的作用,提升整体框架的准确率(Precision);b) 由于弱监督方法结果的置信度不够高,故可通过技能树匹配的结果,对分类结果进行调整;c) 由于匹配方法中,技能树知识体系并没有覆盖所有领域,故可通过直接分类的方法对未覆盖领域的样本进行分类。
3. 总结与展望
3.1 总结
难度等级分类看似一个简单的分类问题,但由于缺乏精确的标注数据难,依据快速落地并不断快速迭代的思路,本文先后同归强规则、基于知识体系的匹配算法、基于弱监督的分类算法,逐步完善整个分类框架,具有较强的可执行性和较快的迭代速度。
3.2 展望
- (1) 当前的匹配算法是基于关键词的匹配,下一步会考虑基于向量的匹配方法,以提升匹配算法的泛化能力;
- (2) 当前的弱监督策略还比较简单,后续会使用少量标注数据,基于半监督的方法,进一步优化数据集。
4. 相关链接
CSDN 技能树
博客质量分计算(二)
CSDN问答标签技能树(二) —— 效果优化
A brief introduction to weakly supervised learning
版权归原作者 Alexxinlu 所有, 如有侵权,请联系我们删除。