网易云信获计算机视觉国际权威赛事冠军,超分辨率技术性能问鼎全球
本月,计算机视觉和模式识别领域顶级会议 CVPR 将在美国新奥尔良市举办,同期计算机图像恢复领域最具影响力的全球性赛事 NTIRE 将在会上颁奖。在 NTIRE 高效率超分辨率挑战赛中,网易云信音视频实验室从众多参赛团队中脱颖而出,在总体性能赛道以明显优势获得冠军,展现了云信在视频超分技术领域的顶尖

使用贝叶斯优化进行深度神经网络超参数优化
在本文中,我们将深入研究超参数优化。
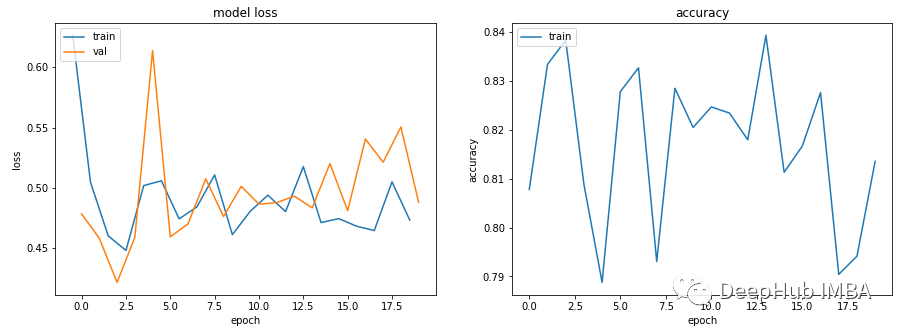
机器学习中训练和验证指标曲线图能告诉我们什么?
我们在训练和验证模型时都会将训练指标保存成起来制作成图表,这样可以在结束后进行查看和分析,但是你真的了解这些指标的图表的含义吗?

在不平衡数据上使用AUPRC替代ROC-AUC
ROC曲线和曲线下面积AUC被广泛用于评估二元分类器的性能。但是有时,基于精确召回曲线下面积 (AUPRC) 的测量来评估不平衡数据的分类却更为合适。
《模型轻量化-剪枝蒸馏量化系列》YOLOv5无损剪枝(附源码)
无损剪枝模型到几百kb~
机器学习之数据归一化(Feature Scaling)
机器学习中的数据归一化
神经网络常见评价指标超详细介绍(ROC曲线、AUC指标、AUROC)
ROC曲线:接受者操作特征曲线(receiver operating characteristic curve)。ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一
宋朝名画“虎戴VR”,在外网火了
金磊 Alex 发自 凹非寺量子位 | 公众号 QbitAI谁能曾想,宋朝的老虎们,有一天能在国外被玩儿火了。事情是这样的。前不久谷歌不是出了个AI创作神器Imagen嘛。只要你给一句话,它就能生成符合语意的图片。然后脑洞大开的国外网友们,不按套路地给Imagen出了道题:给宋代的东方老虎佩戴VR。

JAX介绍和快速入门示例
JAX 是一个由 Google 开发的用于优化科学计算Python 库,它可以被视为 GPU 和 TPU 上运行的NumPy,本文将介绍它的一些基本概念。
机器学习基础备忘录
本文侧重代码实现,不讨论原理
机器学习——从0开始构建自己的GAN网络
机器学习——从0开始构建自己的GAN网络
【纯万字干货】机器学习之数据均衡算法种类大全+Python代码一文详解
对于整个数据建模来看,数据均衡算法属于数据预处理一环。当整个数据集从调出数据库到拿到手的时候,对于分类数据集来说类别一般都是不均衡的,整个数据集合也是较为离散的。因此不可能一拿到数据集就可进行建模,类别的不均衡会极大影响建模判断准确率。其中我们希望整个数据集合的类别数目都是相似的,这样其特征数据权重

14个面试中常见的概率问题
在任何数据科学面试中,基本上都会问道一些有关概率的问题。 这在本文中我总结了一些相关的问题供大家参考。
MAML论文阅读笔记--回归实验
MAML论文阅读笔记--回归实验Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
基于Python构建机器学习Web应用
🏆🏆在本文中,我们基于之前的亚洲美食数据集构建了SVC模型,并介绍了模型可视化工具Netron与Onnx模型格式的使用。与之前基于Python的pkl格式模型相比,Onnx格式的模型适用性更好,可以在多个平台使用。且OnnxRuntime拥有各种语言的API,💻我们可以在各个环境中部署机器学习
独孤九剑第九式-AdaBoost模型和GBDT模型
上次我们介绍了K-means算法和DBSCAN聚类算法(密度聚类算法),目的就是为了通过计算和相关知识,将数据点分成一个一个簇,从而进行相关研究,这一部分无论在本科论文或者式研究生论文中做学科交叉都用的比较多,希望各位引起重视,内容属于简单易学,非常适合我们新手进行学习,接下来,我们讲继续讲解关于监
机器学习生命周期
机器学习的生命周期
机器学习中的数据预处理方法与步骤
机器学习预处理详细方法
python深度学习机器学习必备的学习网站集合!
python深度学习机器学习必备的学习网站集合!
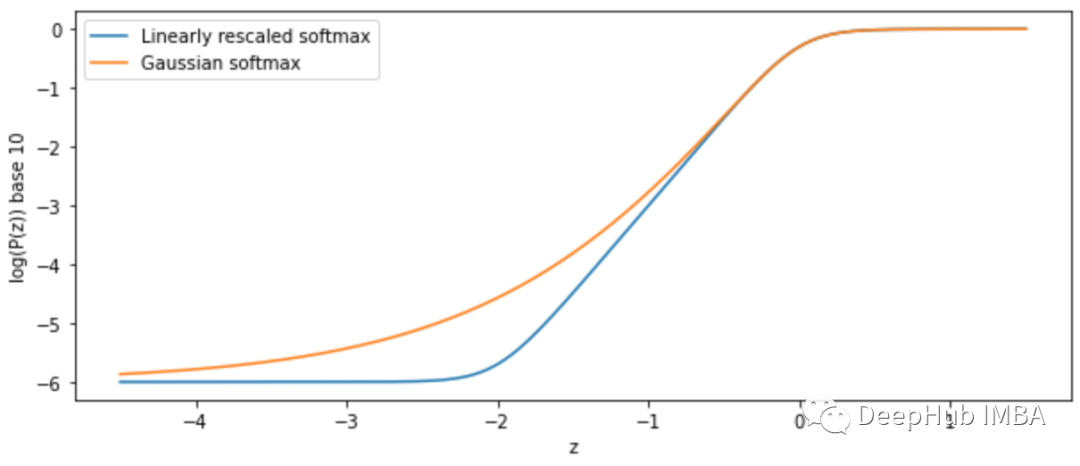
一个新的基于样本数量计算的的高斯 softmax 函数
本文提出了一种基于最小误差界和高斯统计量的softmax函数的安全快速扩展,可以在某些情况下作为softmax的替代



