
系列文章目录
- 手把手带你玩转Spark机器学习-专栏介绍
- 手把手带你玩转Spark机器学习-问题汇总[持续更新]
- 手把手带你玩转Spark机器学习-Spark的安装及使用
- 手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换
- 手把手带你玩转Spark机器学习-使用Spark构建分类模型
- 手把手带你玩转Spark机器学习-使用Spark构建回归模型
文章目录
前言
分类模型处理表示类别的离散变量,而回归模型则处理任意实数的目标变量。二者基本的原则类似,都是通过确定一个模型,将输入特征映射到预测的输出。回归模型和分类模型都是监督学习的一种形式。Spark的MLib库提供了两大回归模型:线性模型和决策树模型。线性回归模型本质上和对应的线性分类模型一样,唯一的区别是线性回归模型使用的损失函数、相关连接函数和决策函数不同。线性回归使用最小二乘回归模型,决策树通过改变不纯度的度量方法用于回归分析。
我们选择Bike Sharing数据来做实验,预测共享单车的需求。我们将深入挖掘数据并应用GBDT决策树来进行预测。最后我们使用CrossValidator, ParamGridBuilder对每个回归器进行参数调整来找到最佳超参数。同时,在文章末尾,我们还对模型性能调优提出了几点建议。
文章中涉及到的code可到本人github处下载:SparkML
一、获取数据集
我们在文章:Spark机器学习实战-使用Spark进行数据处理和数据转换中介绍了如何去获取一些公开数据集来支撑咱们的训练和学习。在这篇文章中我们将使用Bike Sharing数据,来预测未来每小时自行车的出租次数。
数据集中字段定义如下:
变量名定义dteday年月日时间戳season季节 (1:spring, 2:summer, 3:fall, 4:winter)yryear (0:2011, 1:2012)mnthmonth (1 to 12)hrhour (0 to 23)holiday是否为节假日(1 if holiday, 0 otherwise)weekday一周中第几天 (0 to 6)workingday是否为工作日( 0 if weekend or holiday, 1 otherwise)weathersit天气(1:clear, 2:mist or clouds, 3:light rain or snow, 4:heavy rain or snow)temp摄氏温度atemp体表摄氏温度hum湿度windspeed风速casual非注册用户租赁数量registered注册用户租赁数量count总租赁数量
二、数据预处理
1.获取数据及类型总体概要
print("The dataset has %d rows."% df.count())
df.printSchema()

给定的Bike_Sharing数据集有 17379 行和 17 列。季节、假日、工作日列是类别类变量;除了“日期时间”,其余的是数字列。
1. 删除不必要的列
该数据集为机器学习算法做好了充分准备。数字输入列(temp、atemp、hum 和 windspeed)被标准化,分类值(season、yr、mnth、hr、holiday、weekday、workday、weathersit)被转换为索引,并且除日期(dteday) 之外的所有列是数字。 目标是预测自行车租赁的数量(cnt 列)。查看数据集,可以看到某些列包含重复信息。例如,cnt 列等于临时列和注册列的总和。应该从数据集中删除临时列和注册列。索引列也不能用作预测。同时还可以删除 dteday 列,因为此信息已包含在其他与日期相关的列 “”yr、mnth 和 weekday 中。
df = df.drop("instant").drop("dteday").drop("casual").drop("registered")
df.limit(3).toPandas()

2.数据集划分
这里将数据随机拆分为训练集和测试集。通过这样做,你可以仅使用训练子集训练和调整模型,然后评估模型在测试集上的性能,以了解模型在新数据上的表现。
train, test = df.randomSplit([0.7,0.3], seed =0)print("There are %d training examples and %d test examples."%(train.count(), test.count()))
这样我们就将数据集分成了12081个训练样本和5298个测试样本
3.数据可视化
为了对数据有进一步直观了解,我们画出了一天中,销量随时间变化的曲线图。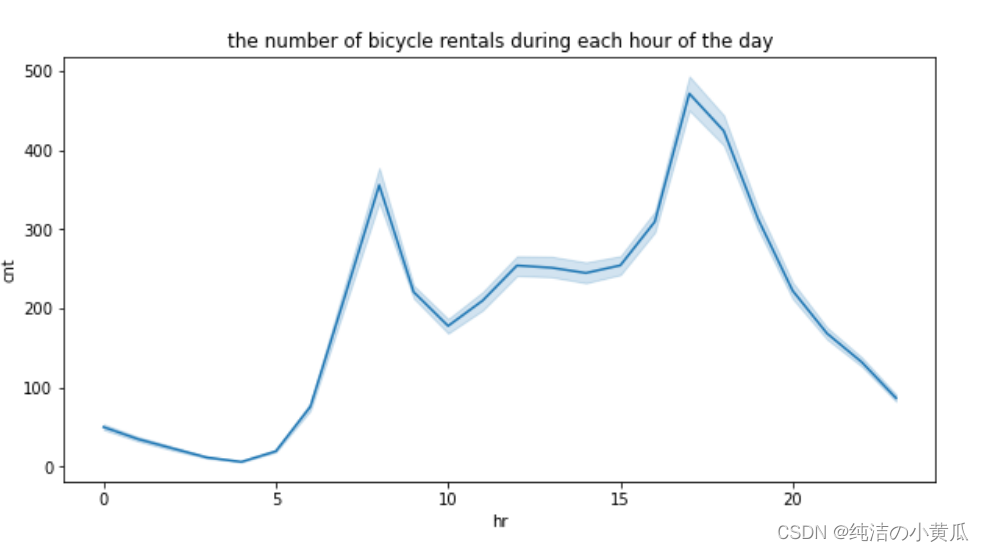
从上图中我们发现自行车租赁是双峰结构,主要在早高峰和晚高峰租车的人多,这两个时段主要是人们上下班的高峰期,也是用车需求的高峰期。
三、模型建模
在这一阶段,我们已经准备好了训练模型来预测未来的共享单车租赁次数。在Spark中的算法需要包含特征向量的单个输入列和单个目标列,但是我们的DataFrame是每个feature是一列。这里MLib库提供了相关的函数可以将我们的输入特征拼接成一列。同时MLlib库还有一个管道函数可以将多个步骤组合到一个工作流中,使我们在开发模型中更容易迭代。在这边博文中,我们将分享几个函数的使用:
现在您已经查看了数据并将其准备为带有数值的 DataFrame,您已准备好训练模型来预测未来的共享单车租赁。大多数 MLlib 算法需要包含特征向量的单个输入列和单个目标列。 DataFrame 当前每个功能都有一列。 MLlib 提供了帮助您以所需格式准备数据集的函数。 MLlib 管道将多个步骤组合到一个工作流中,使您在开发模型时更容易进行迭代。在此示例中,您使用以下函数创建机器学习管道:
- VectorAssembler:将特征列组装成特征向量。
- VectorIndexer:标识应被视为分类的列。 这是启发式地完成的,将具有少量不同值的任何列标识为分类。 在此示例中,以下列被视为分类:yr(2 个值)、season(4 个值)、holiday(2 个值)、workday(2 个值)和 weathersit(4 个值)。
- GBTRegressor:使用梯度提升树 (GBT) 算法来学习如何根据特征向量预测租赁数量。
- CrossValidator:GBT 算法有几个超参数。本博客讲解如何在 Spark 中使用超参数调优。 该函数可以自动网格超参数搜索并选择最佳结果模型。
1.创建VectorAssembler 和 VectorIndexer
from pyspark.ml.feature import VectorAssembler, VectorIndexer
# Remove the target column from the input feature set.
featuresCols = df.columns
featuresCols.remove('cnt')# vectorAssembler combines all feature columns into a single feature vector column, "rawFeatures".
vectorAssembler = VectorAssembler(inputCols=featuresCols, outputCol="rawFeatures")# vectorIndexer identifies categorical features and indexes them, and creates a new column "features".
vectorIndexer = VectorIndexer(inputCol="rawFeatures", outputCol="features", maxCategories=4)
2.定义模型
from pyspark.ml.regression import GBTRegressor
# The next step is to define the model training stage of the pipeline. # The following command defines a GBTRegressor model that takes an input column "features" by default and learns to predict the labels in the "cnt" column.
gbt = GBTRegressor(labelCol="cnt")
3. 交叉验证
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import RegressionEvaluator
# Define a grid of hyperparameters to test:# - maxDepth: maximum depth of each decision tree # - maxIter: iterations, or the total number of trees
paramGrid = ParamGridBuilder()\
.addGrid(gbt.maxDepth,[2,5])\
.addGrid(gbt.maxIter,[10,100])\
.build()# Define an evaluation metric. The CrossValidator compares the true labels with predicted values for each combination of parameters, and calculates this value to determine the best model.
evaluator = RegressionEvaluator(metricName="rmse", labelCol=gbt.getLabelCol(), predictionCol=gbt.getPredictionCol())# Declare the CrossValidator, which performs the model tuning.
cv = CrossValidator(estimator=gbt, evaluator=evaluator, estimatorParamMaps=paramGrid)
在这一步我们将刚才定义好的模型包装在CrossValidator阶段。CrossValidator 使用不同的超参数设置来调用GBT算法。通过最小化指定的指标函数来训练多个模型并选择其中最佳的模型。在这个示例中,我们的度量标准是均方根误差(RMSE)。
4.创建Pipeline
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[vectorAssembler, vectorIndexer, cv])
5.Pipeline Fit
到目前为止,我们已经设置好了工作流程,我们可以通过一次调用来训练pipeline。 当调用 fit() 时,pipeline会运行特征处理、模型参数搜索和训练,并返回找到的最佳模型的拟合pipeline。此步骤会花一些时间。
pipelineModel = pipeline.fit(train)
四、模型预测及评估
1.模型预测
最后一步是使用拟合好的模型对测试数据集进行预测并评估模型的性能。模型在测试数据集上的表现提供了它在新数据上可能表现的近似值。例如,如果当我们有下周的天气预报,我们可以预测下周的自行车租赁数量。 需要注意的是计算评估指标对于理解预测质量以及比较模型和调整参数非常重要。
Pipeline模型的 transform() 方法将整个Pipeline应用于输入数据集。Pipeline将特征处理步骤应用于数据集,然后使用拟合的 GBT 模型进行预测。Pipeline返回一个带有预测新列的DataFrame。
predictions = pipelineModel.transform(test)
predictions.select("cnt","prediction",*featuresCols).limit(3).toPandas()

2.模型评估
评估回归模型性能的常用方法是计算均方根误差 (RMSE)。该值本身的信息量不是很大,但可以使用它来比较不同的模型。 CrossValidator 通过选择最小化 RMSE 的模型来确定最佳模型。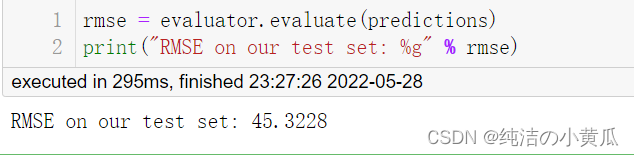
3.预测结果可视化
我们将预测值随小时变化的曲线画出来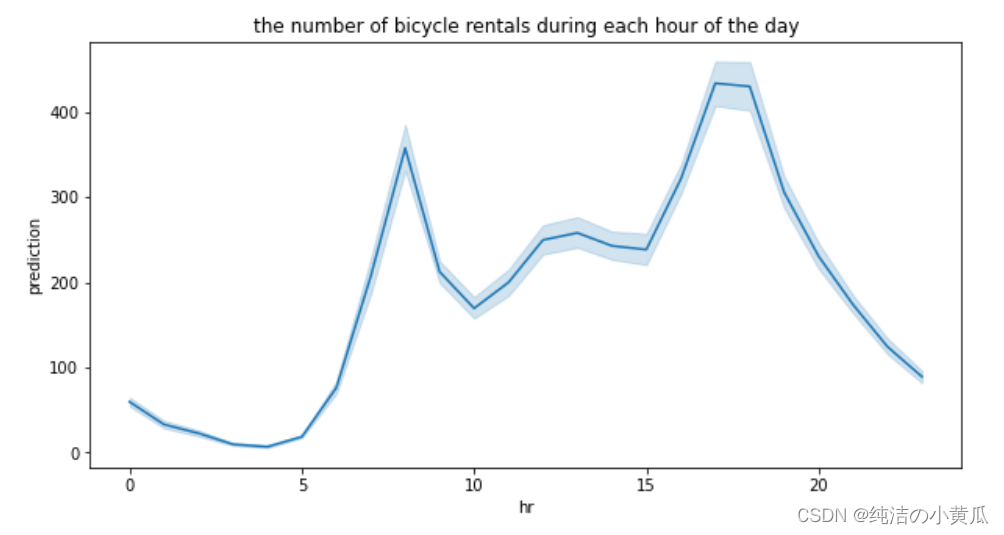
由上图我们发现每小时的租赁数和训练数据显示出类似的形状(双峰结构)。
4.计算残差
检查残差或预期结果与预测值之间的差异也是一个好主意。残差应该是随机分布的;如果残差中有任何模式,则模型可能没有捕捉到重要的东西。在本例中,平均残差约为 1。
import pyspark.sql.functions as F
predictions_with_residuals = predictions.withColumn("residual",(F.col("cnt")- F.col("prediction")))
predictions_with_residuals.agg({'residual':'mean'}).limit(3).toPandas()

为了进一步确认残差分布是随机分布,我们画出残差随小时数变化的曲线。
绘制一天中各小时的残差以寻找任何模式。在这个例子中,没有明显的相关性。
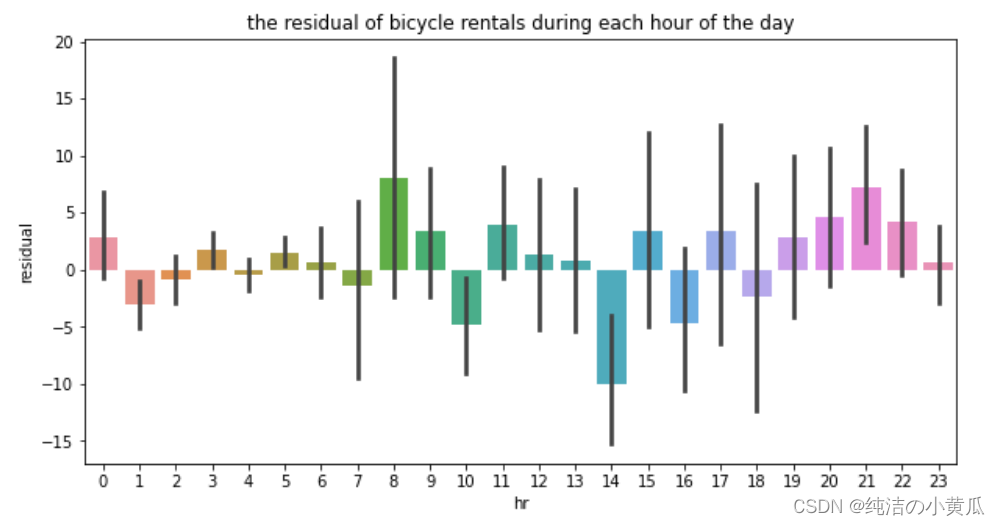
从上图中,我们发现残差分布显然是随机分布的,并没有太明显的规律。
五、模型优化建议
到目前为止,使用Spark构建回归模型我们基本讲完了。但是模型性能调优还有很长的路可以走。关于本文中的模型性能调优有几个方向。
- 比如说租赁数Cnt是注册租赁和临时租赁的总和,但是注册和临时租赁往往代表着不同的行为模式。经常骑自行车的人和不经常骑自行车的人可能处于不同的原因租用自行车。因为我们可以分场景建模,尝试训练一个注册租赁数模型和临时租赁数模型,然后将两者之间的预测值加在一起获得完整的预测。
- 在本文中我们为了演示效果,只用了几个超参数。在实际应用场景中,大家可以尝试使用更多的参数来改进模型,比如说树的深度,更长的训练时间等。
- 在前面我们分享的使用Spark构建分类模型博客中,我们知道特征变换和选择对模型性能有着巨大的影响。比如与工作日相比,天气对周末和节假日出租数量的影响可能更大。大家可以通过尝试组合这两列来创建新的特征。 以下是改进此模型的一些建议: 租金计数是注册和临时租金的总和。这两个计数可能有不同的行为,因为经常骑自行车的人和不经常骑自行车的人可能出于不同的原因租用自行车。尝试训练一个用于注册的 GBT 模型和一个用于休闲的 GBT 模型,然后将它们的预测加在一起以获得完整的预测。 为了提高效率,这个笔记本只使用了几个超参数设置。您可以通过测试更多设置来改进模型。一个好的开始是通过设置 maxIter=200 来增加树的数量;这需要更长的时间来训练,但可能更准确。 此笔记本按原样使用数据集功能,但您可以通过一些功能工程来提高性能。例如,与工作日相比,天气对周末和节假日出租数量的影响可能更大。您可以尝试通过组合这两列来创建新功能。
总结
以上就是本篇文章分享的内容,我们使用Bike Sharing数据,给大家演示了如何利用Spark来构建回归模型,详细分析了从数据获取、数据预处理、可视化、数据集划分、模型训练、超参搜索、模型预测及验证的流程。同时对模型性能调优方向给出几点建议。
版权归原作者 纯洁の小黄瓜 所有, 如有侵权,请联系我们删除。