
在处理单变量时间序列数据时,我们预测的一个最主要的方面是所有之前的数据都对未来的值有一定的影响。这使得常规的机器学习方法(如训练/分割数据和交叉验证)变得棘手。
在本文中我们使用《Apex英雄》中数据分析的玩家活动时间模式,并预测其增长或下降。我们的数据来自https://steamdb.info,这是一个CSV文件。
为了评估模型的性能,我们将使用均方根误差(RMSE)和平均绝对误差(MAE)作为指标来评估我们的回归模型。RMSE将给我们一个数据差值的标准偏差,也就是数据点离最佳拟合线的距离。而MAE度量是指观测值与真实值之间的差值,这将有助于确定模型的准确性。
EDA
拿到数据后,肯定第一个操作就是进行EDA。在处理时间序列数据时,数据探索性分析的主要目的是发现以下这些特征:
- 季节性 Seasonality
- 趋势 Trend
- 平稳性 Stationary
除此之外,我们还可以计算出各种平均值:
- 简单的移动平均线
- 指数移动平均值
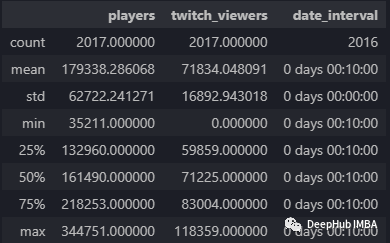
自2019年2月《Apex英雄》首次发布以来的统计汇总,玩家的数量表明,Apex英雄平均约为179,000个玩家
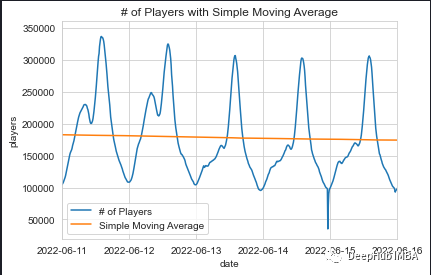
这图为简单移动平均趋势线
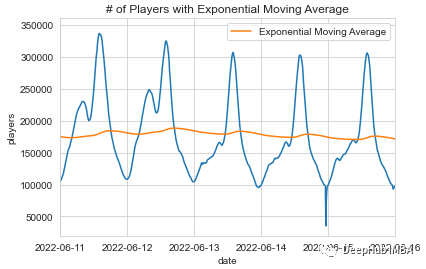
这图为指数移动平均线。
简单的移动平均线表明6月份玩家活动有轻微的下降趋势。趋势线的斜率为11,考虑到玩家在100k到300k之间波动,在统计上并不显著。因此可以说玩家在6月份的活动相当稳定。
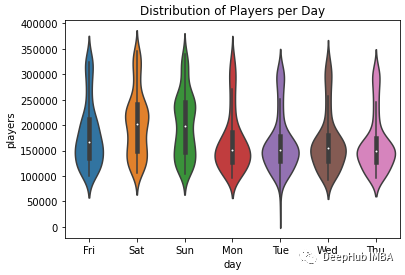
这是根据星期来计算的每天玩家活动的小提琴图
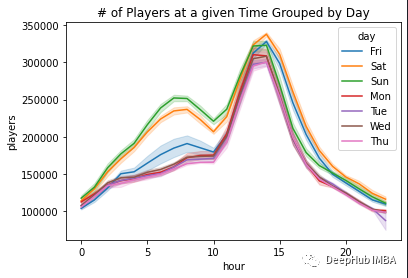
这是每天中按小时分布的玩家活动图
小提琴图不仅可以显示一些汇总的统计数据,如最大值、最小值和中值,还可以直观地显示分布。我们可以观察到,周末相对于工作日,尤其是周六和周日,分布更均匀。
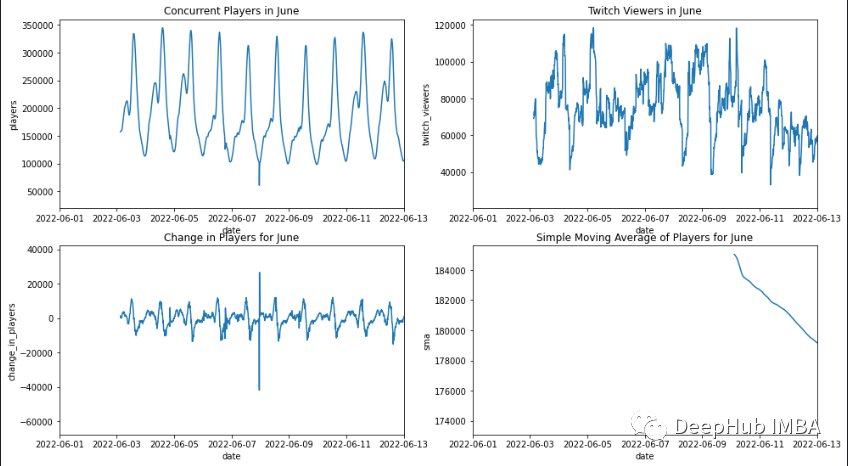
玩家和twitch观看者在6月份的活动模式。
通过上图可以看到单变量时间序列有一个确定的模式。一天中可预测的上升和下降。这在以后讨论模型预测时将非常重要。
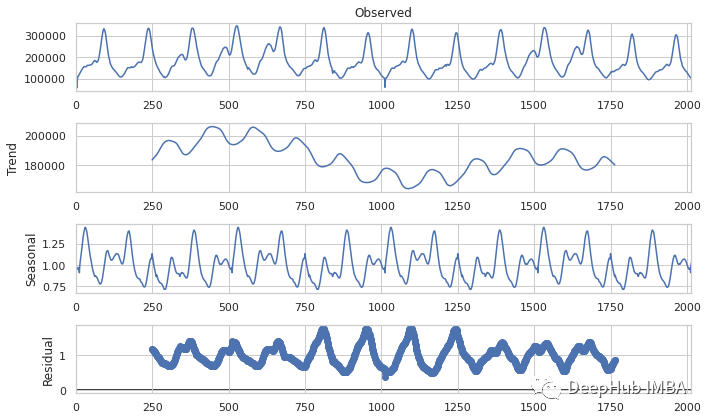
观察值=趋势+季节性+残差
我们需要确认的一个假设是时间序列是平稳,也就是说均值和方差基本不会变化,这对于自回归模型十分重要。
但是从视觉上看很难判断平均值和差异是否在变化,我们需要一种检查此问题的方法。尽管从移动平均线来看,我们可以看到大多数情况下的变化并不大,但是我们需要确保使用统计测试在统计上是有统计学意义的。
Dicky-Fuller检验是一个假设检验,可以通过它来知道时间序列是否平稳。该测试的零假设是时间序列是非平稳的。所以我们需要p值小于0.05,这样就可以拒绝零假设。可以看到下面的p值小于0.05,所以我们确实可以拒绝零假设,它是非平稳的,并说我们的数据确实有平稳的均值和方差。(代码见最后的地址)
Test Statistic: -7.4339413132678205
p-value: 6.254742639140234e-11
建模
本文中测试了3种不同的模型:Naive, FB Prophet和自回归。并比较了这三个模型的性能
使用单变量数据创建训练集和验证集不同于典型的表格数据。所以sklearn的TimeSeriesSplit函数可以帮助我们完成这个工作,对单变量数据进行4次拆分,并执行交叉验证。在拆分之后,应用模型并为每次拆分计算评估指标(RMSE和MAPE)。均方根误差(RMSE)和均方根误差(MAPE)取平均值。
def eval_model_perf(df: pd.DataFrame , model: Callable[[pd.DataFrame, pd.DataFrame], List[any]]) -> None:
""" Evaluates the performance of a model using RMSE and MAPE.
Args:
df (DataFrame): The input DataFrame.
model (DataFrame, List): The predicted values by the model that is being evaluated.
"""
rmse_metrics = []
mape_metrics = []
tscv = TimeSeriesSplit(n_splits=4)
for train_index, test_index in tscv.split(df):
cv_train = df.iloc[train_index]
cv_test = df.iloc[test_index]
preds = model(cv_train, cv_test)
rmse_eval = rmse(cv_test, preds)
naive_eval = mean_absolute_percentage_error(cv_test, preds)
rmse_metrics.append(rmse_eval)
mape_metrics.append(naive_eval)
print("Cross Validation Results: ")
print(f"RMSE: {np.mean(rmse_metrics)}")
print(f"MAPE: {np.mean(mape_metrics)}")
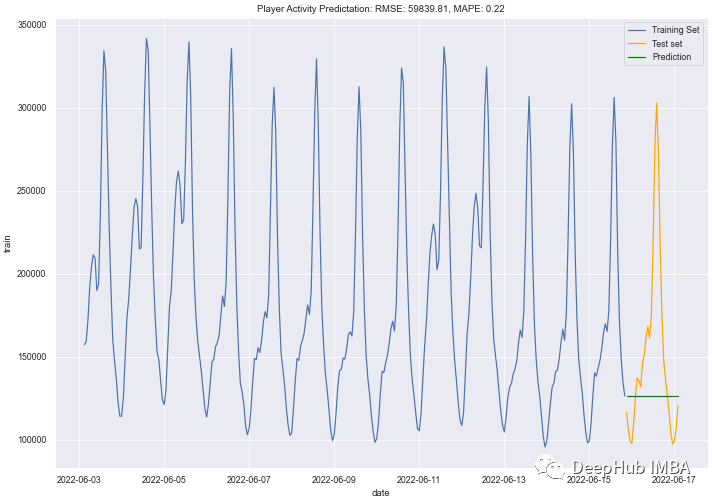
1、Naive
Naive将前一个值作为下一个值进行预测,这个在实际中并没有任何意义,我们这里只是用他来作为对照,如果其他模型的结果还不如它,那么其他模型就更没有任何存在的价值。
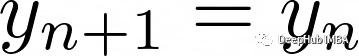
结果如下
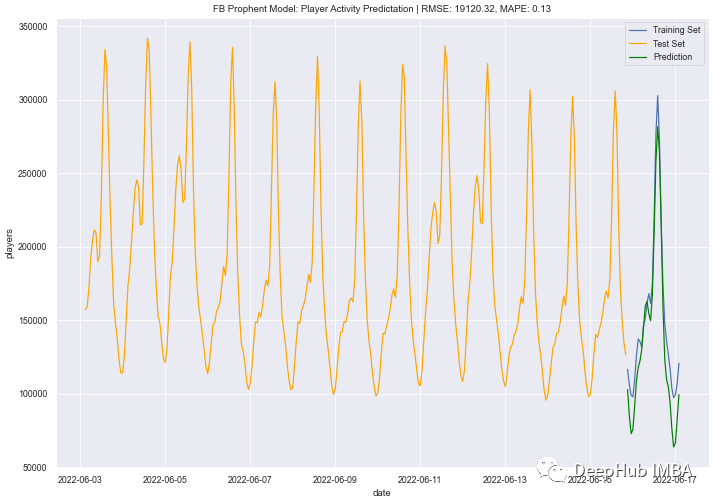
2、FB Prophet
Prophet模型使用AM进行预测。
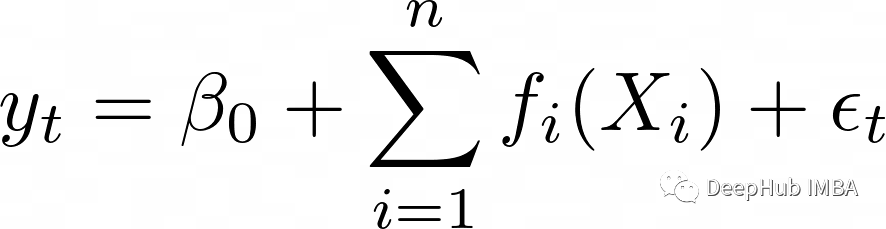
结果如下:
他的好处有:
没有很多参数需要调整。
有自动化的缩放量可以很好地缩放数据。
在将数据集发送到模型之前,不需要对数据集进行过多的了解。
但是他缺点也很明显:
模型假设季节性变化是恒定的,不随时间的变化而变化
比AR模型更难解释。
3、自回归模型
自回归模型通过前面的预测来预测后面的值,也就是说后面的预测值会使用前面的预测结果
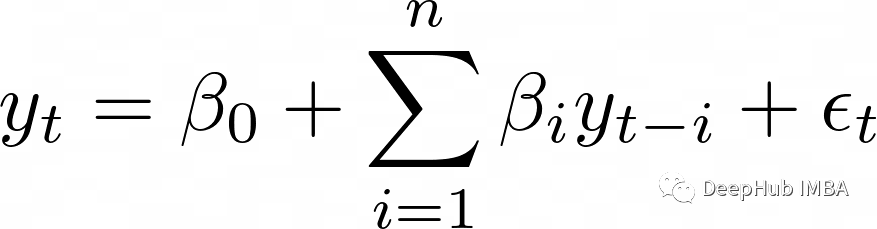
结果如下:
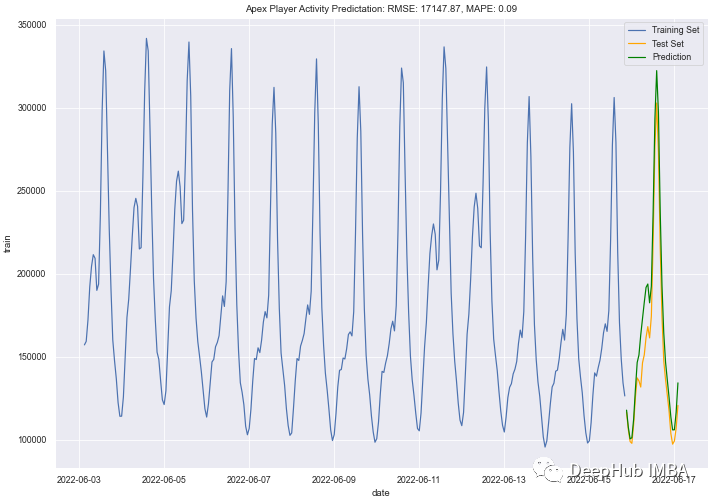
优势:
- 可以灵活处理广泛的时间序列模式
- 更容易解释该模型在做什么
缺点:
- 需要很多的参数
- 时间序列数据需要先验信息才能够更加准确
总结
我们测试了三种模型来预测玩家的活动(其实是2个有效模型)。原始模型作为评估其他模型的基线。Facebook Prophet模型是由Facebook开发我们可以直接拿来使用,还有一个是我们根据已知特征(例如趋势和季节性等)的单变量的自回归模型。
在创建这些模型的过程中,最复杂的是自回归模型,因为它需要大量的探索性数据分析。
FB Prophet不涉及超参数调优,并且不需要关于单变量数据特征的先验信息,模型的精度为87%,RMSE ~19120。facebook Prophet模型中一个明显的趋势是对下降趋势的夸大。但是这已经相当好了
虽然FB Prophet模型很好,但它没有击败自回归模型。自回归模型是一个更直观、更容易理解的模型。与线性回归相似,单变量数据被分解成线性组合,因此,模型的一个优点是更容易解释。缺点是,虽然这个模型的性能比其他任何模型都要好,但它确实需要一些数据知识。
自回归模型另外一个缺点是,需要对底层数据有坚实的理解。而FB Prophet模型不需要我们理解任何数据。这也可能是FB Prophet模型的一个缺点是它使用可加模型,更难以解释,不像AR模型那样灵活。
自回归模型和FB Prophet模型似乎都表明,虽然有轻微的下降趋势,但不具有统计学意义,如假设检验所示。我们还发现我们的时间序列数据是平稳的,这是AR模型的要求。
本文的完整代码在这里:
https://github.com/defunSM/Data-Science-Portfolio/tree/main/Steam%20Charts
作者:Salman Hossain