深度学习常见名词概念:Sota、Benchmark、Baseline、端到端模型、迁移学习等的定义
深度学习:Sota的定义sota实际上就是State of the arts 的缩写,指的是在某一个领域做的Performance最好的model,一般就是指在一些benchmark的数据集上跑分非常高的那些模型。
手把手调参最新 YOLOv7 模型 训练部分 - 最新版本(二)
YOLO科研Trick改进推荐 | 包括Backbone、Neck、Head、注意力机制、IoU损失函数、NMS、Loss计算方式、自注意力机制、数据增强部分、激活函数
吴恩达 - 机器学习课程笔记(持续更新)
吴恩达机器学习
2022 CCF BDCI 返乡发展人群预测 [0.9117+]
返乡发展人群预测:基于中国联通的大数据能力,通过使用对联通的信令数据、通话数据、互联网行为等数据进行建模,对个人是否会返乡工作进行判断A榜的结果为0.91171720。
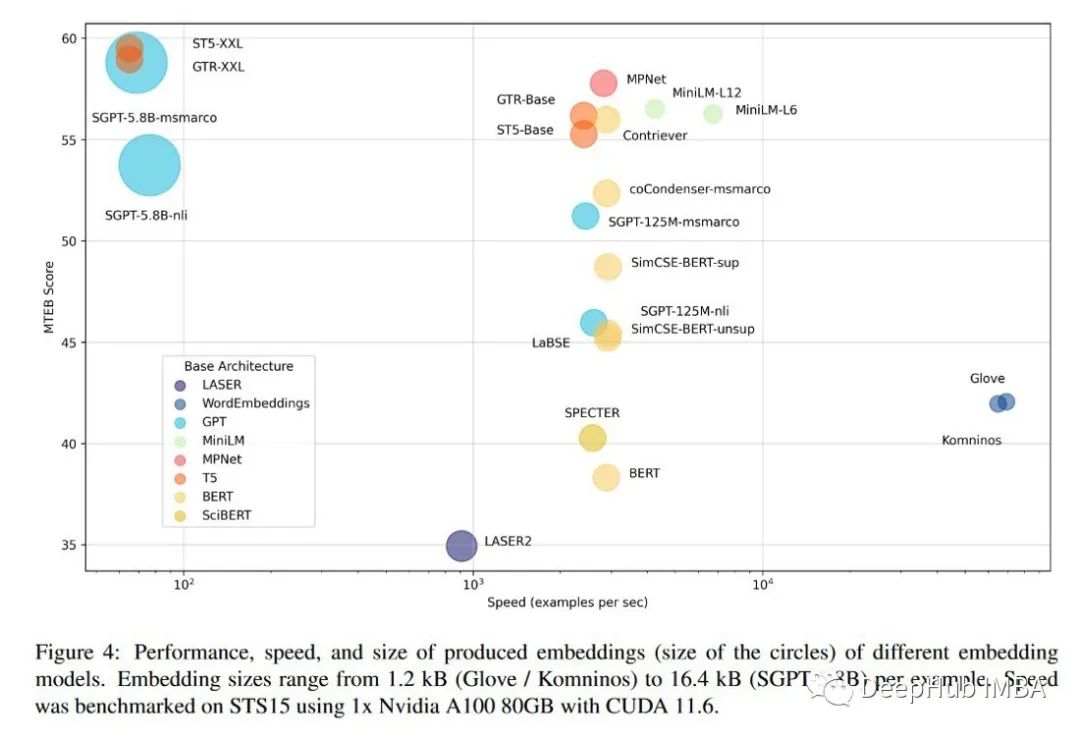
2022年11月10篇论文推荐
介绍10篇推荐的论文。这里将涵盖强化学习(RL)、扩散模型、自动驾驶、语言模型等主题。
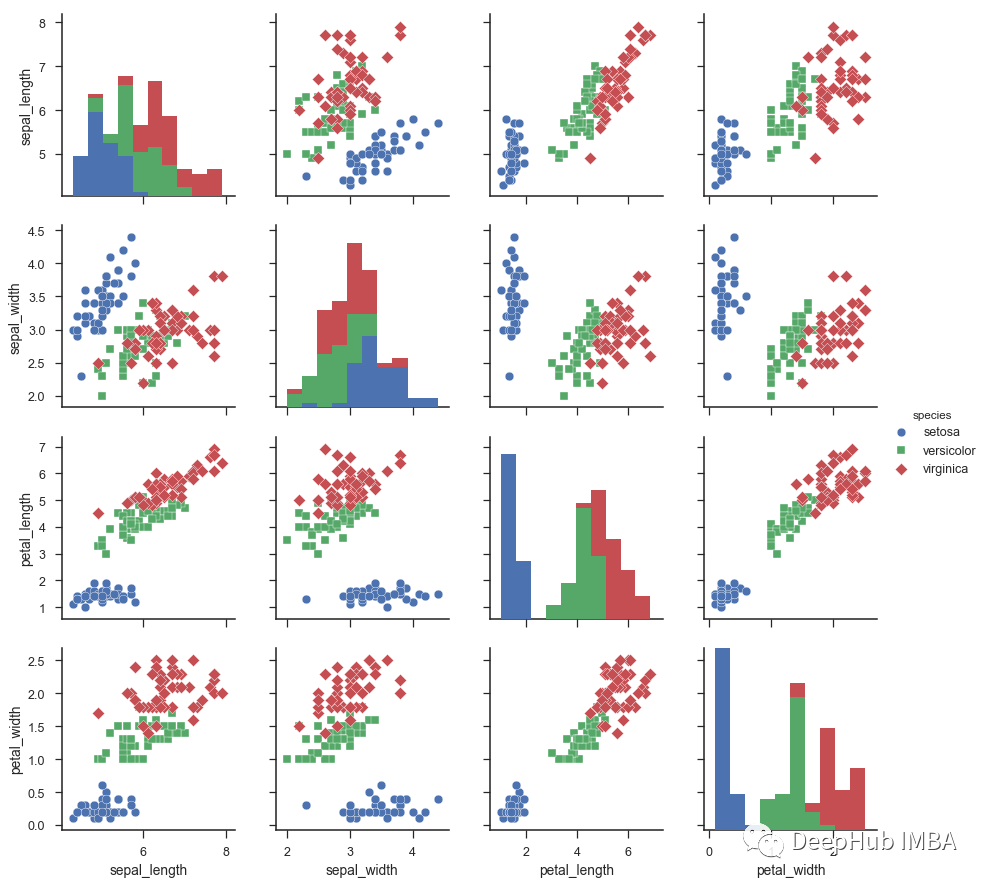
特征选择技术总结
在本文中,我们将回顾特性选择技术并回答为什么它很重要以及如何使用python实现它。

可解释的AI:用LIME解释扑克游戏
可解释的AI(XAI)一直是人们研究的一个方向,在这篇文章中,我们将看到如何使用LIME来解释一个模型是如何学习扑克规则的。
机器学习期末题库
1.属于监督学习的机器学习算法是:贝叶斯分类器2.属于⽆监督学习的机器学习算法是:层次聚类3.⼆项式分布的共轭分布是:Beta分布4.多项式分布的共轭分布是:Dirichlet分布5.朴素贝叶斯分类器的特点是:假设样本各维属性独⽴6.下列⽅法没有考虑先验分布的是:最⼤似然估计7.对于正态密度的贝叶斯
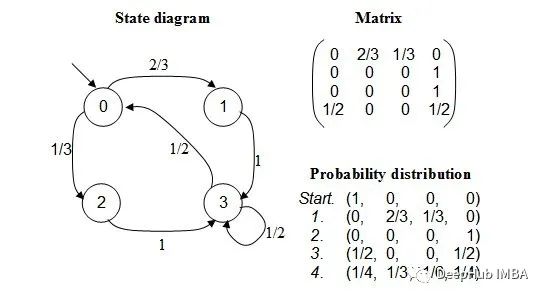
使用马尔可夫链构建文本生成器
本文中将介绍一个流行的机器学习项目——文本生成器,你将了解如何构建文本生成器,并了解如何实现马尔可夫链以实现更快的预测模型。
机器学习中的数学——距离定义(一):欧几里得距离(Euclidean Distance)
欧几里得距离或欧几里得度量是欧几里得空间中两点间的即直线距离。使用这个距离,欧氏空间成为度量空间,相关联的范数称为欧几里得范数。nnn维空间中的欧几里得距离:d(x,y)=∑i=1n(xi−yi)2=(x1−y1)2+(x2−y2)2+⋯+(xn−yn)2d(x, y)=\sqrt{\sum_{i=
粒子群算法求解0-1背包问题
粒子群优化算法(PSO:Particle swarm optimization) 是一种进化计算技术(evolutionary computation)。源于对鸟群捕食的行为研究。粒子群优化算法的基本思想:是通过群体中个体之间的协作和信息共享来寻找最优解.PSO的优势:在于简单容易实现并且没有许多参
Origin曲线拟合教程
利用origin进行线性拟合的一些分析教程
什么是推荐系统?推荐系统类型、用例和应用
当前基于 DL 的推荐系统模型:DLRM、Wide and Deep (W&D)、神经协作过滤 (NCF)、b变分自动编码器 (VAE) 和 BERT(适用于 NLP)构成了 NVIDIA GPU 加速 DL 模型产品组合的一部分,并涵盖推荐系统以外的许多不同领域的各种网络架构和应用程序,包括图像、
群体智能优化算法
群体智能优化算法群体智能(SI)源于对以蚂蚁、蜜蜂等为代表的社会性昆虫的群体行为的研究,群居性生物通过协作表现出的宏观智能行为特征。群体智能算法有粒子群优化算法(PSO)、蚁群优化算法(ACO)、人工蜂群优化算法(ABC)、差分进化算法(DE)、引力搜索算法(GSA)、萤火虫算法(FA)、蝙蝠算法(
机器学习深度神经网络——实验报告
机器学习实验报告6:深度神经网络
拉格朗日乘子法
是一种寻找多元函数在一组约束下的极值的方法。通过引入拉格朗日乘子,可将有 ddd 个变量与 kkk 个约束条件的最优化问题转化为具有 d+kd + kd+k 个变量的无约束优化问题求解。假如有方程 x2y=3x^2y=3x2y=3,它的图像如下(左一)所示。现在我们想求其上点与原点的最短距离(中图)
局部规划算法:DWA算法原理
DWA算法(dynamicwindowapproach)是移动机器人在运动模型下推算(v,w)对应的轨迹,确定速度采样空间或者说是动态窗口(三种限制);在速度空间(v,w)中采样多组速度,并模拟这些速度在一定时间内的运动轨迹,通过一个评价函数对这些轨迹打分,选取最优的轨迹来驱动机器人运动。...
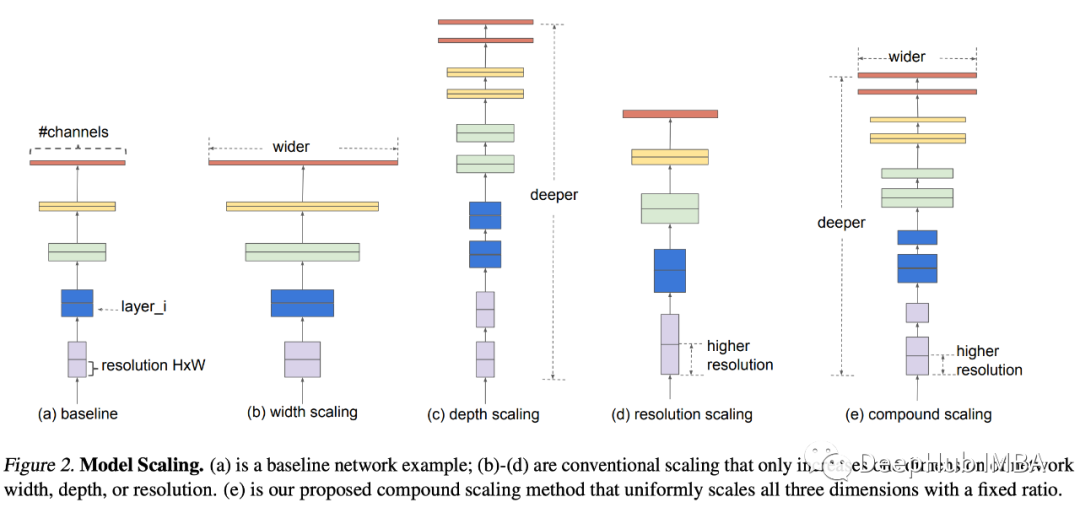
经典CNN设计演变的关键总结:从VGGNet到EfficientNet
卷积神经网络设计史上的主要里程碑:模块化、多路径、因式分解、压缩、可扩展
Python 实现朴素贝叶斯代码演示
朴素贝叶斯可以细分为三种方法:分别是伯努利朴素贝叶斯、高斯朴素贝叶斯和多项式朴素贝叶斯。下文就这三种方法进行详细讲解和演示。目录一、伯努利朴素贝叶斯方法1.1 例子解答1.1.1 代码:1.1.2 结果:二、高斯朴素贝叶斯方法2.1 解题2.1.1 代码:2.1.2 结果:2.2 检查高斯朴素贝叶斯



