

文章目录
学习目标
- 了解CRF的概念和作用
- 了解转移概率矩阵
- 了解发射概率矩阵
CRF的概念和作用
场景一: 假设有一堆日常生活的给小朋友排拍的视频片段, 可能的状态有睡觉、吃饭、喝水、洗澡、刷牙、玩耍等, 大部分情况, 我们是能够识别出视频片段的状态. 但如果你只是看到一小段拿杯子的视频, 在没有前后相连的视频作为前后文参照的情况下, 我们很难知道拿杯子是要刷牙还是喝水. 这时, 可以用到CRF模型.
场景二: 假设有分好词的句子, 我们要判断每个词的词性, 那么对于一些词来说, 如果我们不知道相邻词的词性的情况下, 是很难准确判断每个词的词性的. 这时, 我们也可以用到CRF.
CRF(全称Conditional Random Fields), 条件随机场. 是给定输入序列的条件下, 求解输出序列的条件概率分布模型.
下面举两个应用场景的例子:
基本定义: 我们将随机变量的集合称为随机过程. 由一个空间变量索引的随机过程, 我们将其称为随机场. 上面的例子中, 做词性标注时, 可以将{名词、动词、形容词、副词}这些词性定义为随机变量, 然后从中选择相应的词性, 而这组随机变量在某种程度上遵循某种概率分布, 将这些词性按照对应的概率赋值给相应的词, 就完成了句子的词性标注.
关于条件随机场与马尔科夫假设
马尔科夫假设, 也就是当前位置的取值只和与它相邻的位置的值有关, 和它不相邻的位置的值无关.
应用到我们上面的词性标注例子中, 可以理解为当前词的词性是根据前一个词和后一个词的词性来决定的, 等效于从词性前后文的概率来给出当前词的词性判断结果.
现实中可以做如下假设: 假设一个动词或者副词后面不会连接同样的动词或者副词, 这样的概率很高. 那么, 可以假定这种给定隐藏状态(也就是词性序列)的情况下, 来计算观测状态的计算过程. 本质上CRF模型考虑到了观测状态这个先验条件, 这也是条件随机场中的条件一词的含义.
转移概率矩阵:
首先假设我们需要标注的实体类型有一下几类:
{"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4}
# 其中dis表示疾病(disease), sym表示症状(symptom), B表示命名实体开头, I表示命名实体中间到结尾, O表示其他类型.
因此我们很容易知道每个字的可能标注类型有以上五种可能性, 那么在一个句子中, 由上一个字到下一个字的概率乘积就有5 × 5种可能性, 具体见下图所示:
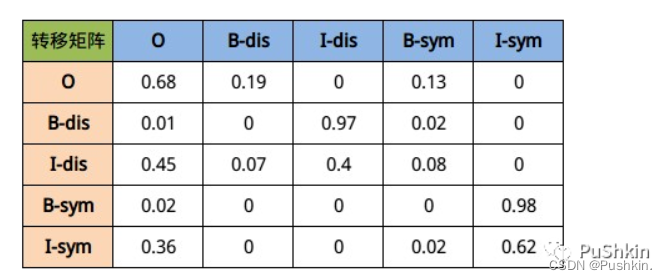
最终训练出来结果大致会如上图所示, 其中下标索引为(i, j)的方格代表如果当前字符是第i行表示的标签, 那么下一个字符表示第j列表示的标签所对应的概率值. 以第二行为例, 假设当前第i个字的标签为B-dis, 那么第i+1个字最大可能出现的概率应该是I-dis.
发射概率矩阵
发射概率, 是指已知当前标签的情况下, 对应所出现字符的概率. 通俗理解就是当前标签比较可能出现的文字有哪些, 及其对应出现的概率.
下面是几段医疗文本数据的标注结果: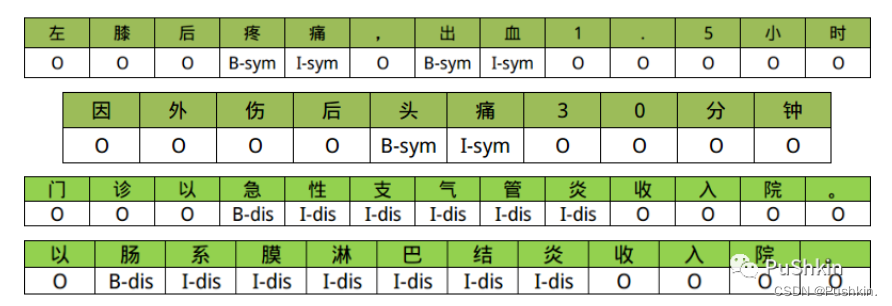
可以得到以上句子的转移矩阵概率如下: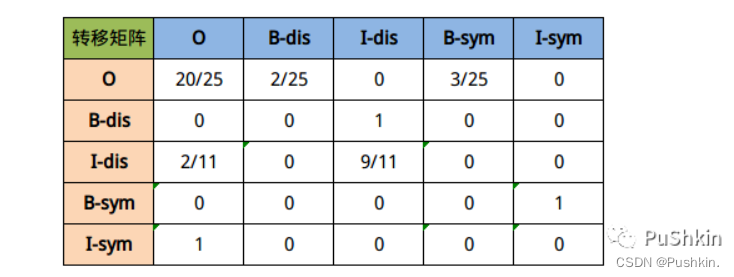
对应的发射矩阵可以理解为如下图所示结果: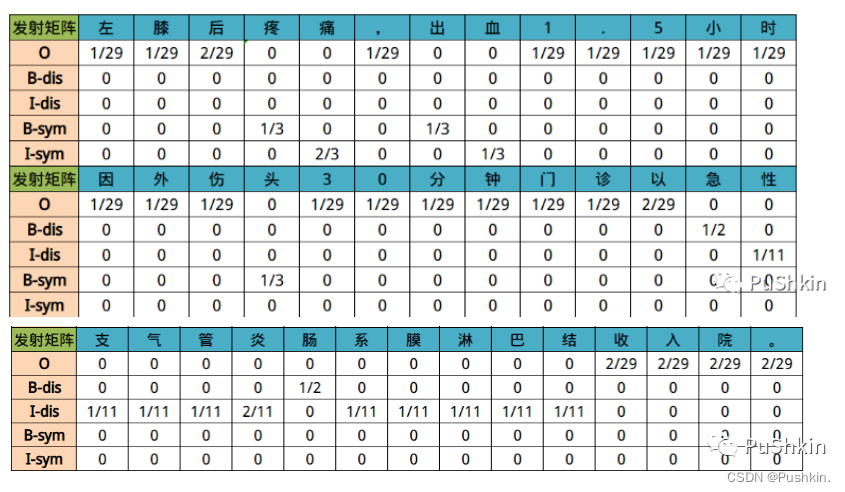
版权归原作者 Pushkin. 所有, 如有侵权,请联系我们删除。