
由于训练时间短,越来越多人使用自适应梯度方法来训练他们的模型,例如Adam它已经成为许多深度学习框架的默认的优化算法。尽管训练结果优越,但Adam和其他自适应优化方法与随机梯度下降(SGD)相比,有时的效果并不好。这些方法在训练数据上表现良好,但在测试数据却差很多。
最近,许多研究人员已经开始针对这个问题进行研究,尤其是我们最常用的Adam。本篇文章将试着理解一下这些研究结果。
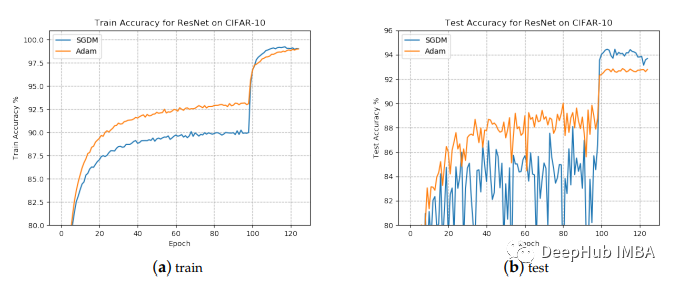
Adam收敛速度更快,但最终的结果却并不好!
为了充分理解这一说法,我们先看一看ADAM和SGD的优化算法的利弊。
传统的梯度下降是用于优化深度学习网络的最常见方法。该技术在1950年代首次提出,可以通过观察参数变化如何影响目标函数,选择一个降低错误率的方向来更新模型的每个参数,并且可以进行继续迭代,直到目标函数收敛到最小值。
SGD是梯度下降的一种变体。SGD并不对整个数据集执行计算——而是只对随机选择的数据示例的一个小子集进行计算。在学习率较低的情况下,SGD的性能与常规梯度下降相同。
Adam的优化方法根据对梯度的一阶和二阶的估计来计算不同参数的个体自适应学习率。它结合了RMSProp和AdaGrad的优点,对不同的参数计算个别的自适应的学习率。与RMSProp中基于平均第一阶矩(平均值)来调整参数学习率不同,Adam还使用了梯度的第二阶矩(非中心方差)的平均值。
上图来自cs231n,根据上面的描述Adam能迅速收敛到一个“尖锐的最小值”,而SGD计算时间长步数多,能够收敛到一个“平坦的最小值”,并且测试数据上表现良好。
为什么ADAM不是默认优化算法呢?
2019年9月发表的文章《Bounded Scheduling Method for Adaptive Gradient Methods》研究了导致Adam在训练复杂神经网络时表现不佳的因素。我们这里将Adam经验概化能力较弱的关键因素归纳如下:
- 梯度尺度的不均匀会导致自适应梯度的方法泛化性能较差。但SGD具有统一尺度,训练误差小,在测试数据推广时效果也会好
- Adam使用的指数移动平均并不能使学习率单调下降,这将导致它不能收敛到最优解,从而导致泛化性能较差。
- Adam学习到的学习率在某些情况下可能太小而不能有效收敛,这会导致它找不到正确的路径而收敛到次优点。
- Adam可能会大幅提高学习率,这不利于算法的整体性能。
最后我们做个总结
尽管自适应梯度算法的收敛速度更快,但其泛化性能却比SGD算法差。具体来说,自适应梯度算法在训练阶段的进展很快,但在测试数据上的表现很快就会停滞不前。但是SGD通常对模型性能的改善很慢,但可以获得更高的测试性能。对于这种泛化差距的一种经验解释是,自适应梯度算法倾向于收敛到尖锐的极小值,其局部地区的曲率较大,所以泛化性能较差,而SGD则倾向于寻找平坦的极小值,因此泛化较好。
但是,本文这并不是否定自适应梯度方法在神经网络框架中的学习参数的贡献。而是希望能够在使用Adam的同时实验SGD和其他非自适应梯度方法,因为盲目地将Adam设置为默认优化算法可能不是最好的方法。
作者:Harjot Kaur