
前言
从开始学习机器学习到现在已经有三年了,建模过程以及各类模型使用场景都有个大致的掌握。其中我感觉在我所有的机器学习文章中缺少一篇真正引人入门的文章。任何情况迈开学习的第一步都是比较困难的,学习的成本是很高的,相对你学会了收益也高。尤其是机器学习这种数学和逻辑能力强关联的学科,是比较难上手的事,但是当真正做出来了开始上手了便会产生一种兴奋喜悦感,我感觉这才是我为什么从事数据挖掘建模工作这一原因。写这篇文章我希望其他小伙伴想要入门机器学习的时候不用太过于担心自己的能力,先尝试着迈开自己的第一步做做看。希望大家喜欢。
希望读者看完能够提出错误或者看法,博主会长期维护博客做及时更新。
一、从目的出发
既然是第一个项目那么我们不要搞得那么复杂,一切从简就好,加上我们还有Python-sklearn这类强力的机器学习分析库。所有我们直接从目的出发,利用鸢尾花(Iris Flower)库来做一个分类,就这么简单。
1.导入数据
那么我们首先需要数据,数据从哪里来呢?
数据一直以来都是做机器学习的一个难题。我们构建机器学习模型就是要通过大量历史数据去训练模型达到有能力去拟合真值的这么一个过程。而数据质量和数量的好坏决定了模型的上限,从数据的采集到数据的加工和计算都是如此。采集往大的方面讲要涉及到传感器,复杂的有点云,多维传感器,而简单的从数据库获取用户信息就好。加工数据有专门的ETL小组或者部门来完成,采集到的不同种类数据需要加工的程度也不同,例如敏感数据则还需要脱敏处理,缺失数据则需要补全去除处理。计算的话就更多形式了,现在不单单追求模型的正确率,商业上更追求速度,例如现在流行的大数据分布式计算框架和神经网络深度学习框架。总之我们首先不考虑数据的来源,机器学习sklearn库自带鸢尾花数据。Iris 鸢尾花数据集内包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
- sepallength:萼片长度
- sepalwidth:萼片宽度
- petallength:花瓣长度
- petalwidth:花瓣宽度
以上四个特征的单位都是厘米(cm)。
这个数据集具有以下特点:
- 所有的特征数据都是数字,不需要考虑如何导入和处理数据。
- 所有的特征的数值单位都是相同的,不需要尺度转换。
那么我们就安装传统的机器模型建模过程来完成一个机器学习项目的所有步骤。我们将按照下面的步骤来实现这个项目:
二、项目开启
1.导入数据
首先我们需要引入我们将要用到的库:
from sklearn.datasets import load_iris
import pandas as pd
之后我们只需要登陆数据就可以看到数据的形式了:
iris_data = load_iris()
iris_data_feature=list(iris_data.data)
iris_data_df=pd.DataFrame(iris_data_feature,columns=['花萼长度','花萼宽度','花瓣长度','花瓣宽度'])
iris_data_df
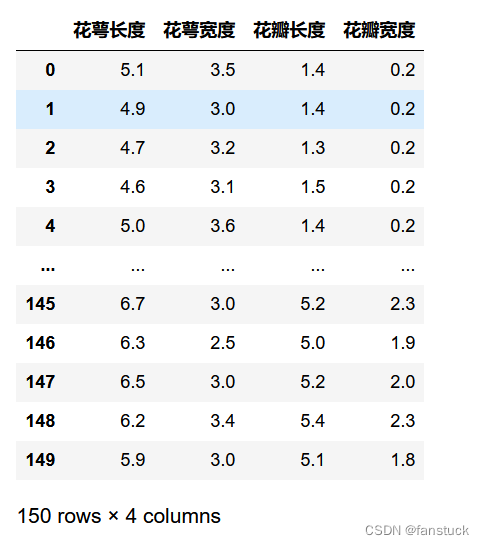
其中我们可以看到iris_data里面的数据主要分为两部分,一部分是data代表了'花萼长度','花萼宽度','花瓣长度','花瓣宽度'这四个维度的数据,而target则为花朵类型数据:
iris_data_class=list(iris_data.target)
iris_class_df=pd.DataFrame(iris_data_class,columns=['花朵类型'])
iris_class_df


可以看到数据是十分平常的,精确到小数点后一位,从肉眼观测数据量大的数据集是十分不方便的一件事,我们需要直观的预览数据。
通过合并我们可以得到一张完整的鸢尾花数据表,方便以后绘图和统计:
iris_true_df=pd.concat([iris_data_df,iris_class_df],axis=1)
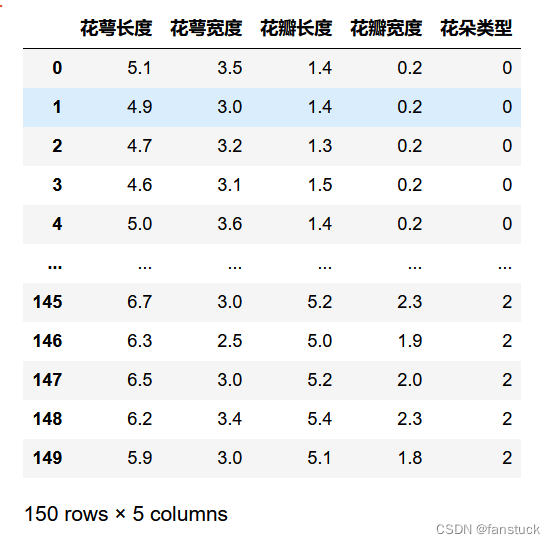
2.预览数据
预览数据的方式有很多种,可以通过数据可视化预览也可以通过数据的统计描述来预览。这里就可以提现出我们pandas的强大数据分析功能了,pandas带有许多统计分析函数,能够快速获得常用统计参数:
iris_true_df.describe()
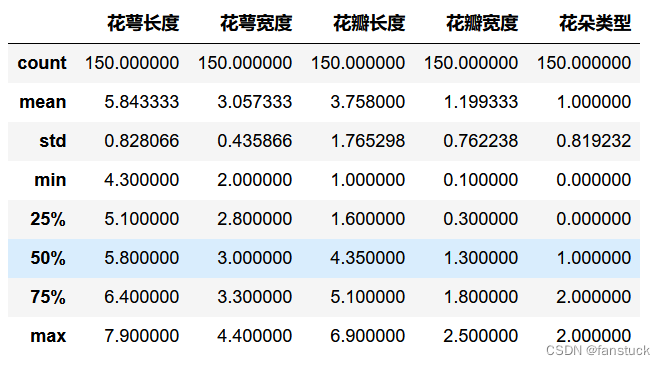
其中 统计值变量说明:
- count:数量统计,此列共有多少有效值
- unipue:不同的值有多少个
- std:标准差
- min:最小值
- 25%:四分之一分位数
- 50%:二分之一分位数
- 75%:四分之三分位数
- max:最大值
- mean:均值
我们可以通过标签分组,将不同花朵类型的数据进行分组聚合,查看各个分类的数据分布是否均衡:
iris_true_df.groupby('花朵类型').size()

我们可以看到鸢尾花的三个种类的数据都为50条,分布均衡。通过分组可以还可以聚合获取不同类别的花朵各个维度的聚合数据:
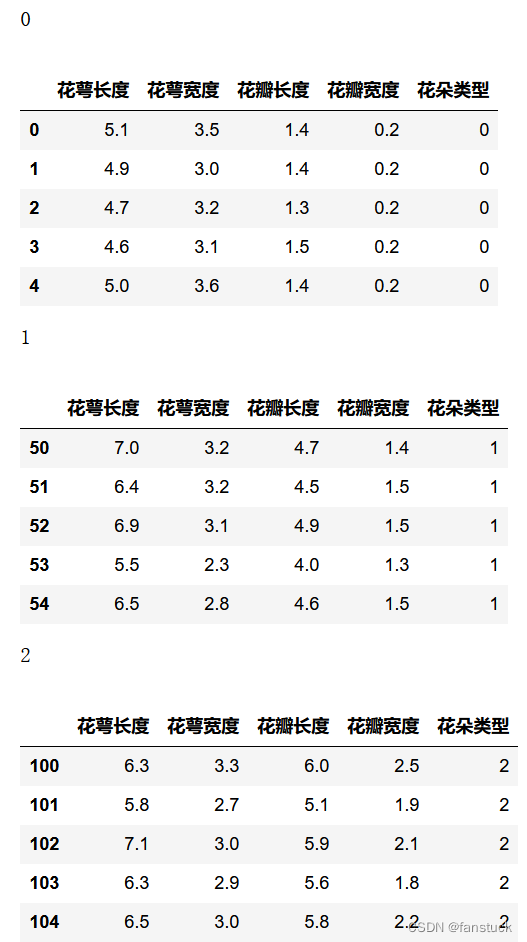
iris_true_gy=iris_true_df.groupby('花朵类型')
for name,group in iris_true_gy:
print(name)
display(group.head())
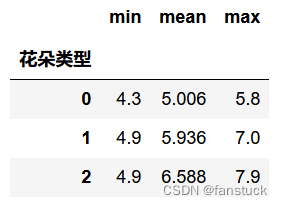
通过pandas的agg聚合函数就可以实现更加细化的统计:
iris_true_gy['花萼长度'].agg(['min','mean','max'])
3.数据预处理
如果数据的分布不平衡时,可能影响到模型的准确度。因此,当数据分布不平衡时,需要对数据进行处理,调整数据到相对平衡的状态。
数据预处理作为机器学习大的一个课题研究已经经过了好几十年的经验技术沉淀。想要深入了解的可以阅读:一文速学-特征数据类别分析与预处理方法详解+Python代码_fanstuck的博客-CSDN博客
这篇文章,其中处理方法在:
机器学习之数据均衡算法种类大全+Python代码一文详解_fanstuck的博客-CSDN博客_数据均衡
1.过采样
过采样也被称为上采样,这个方法更适用于小数据分布不均衡。如果是大数据分布不均衡,则将原来的小份类别不同的数据集扩充到与类别不同的数据集对等大小的情况。如第一个例子的数据,若进行过采样,则将会有超过26万的数据生成。与欠采样相比计算权重比例以及运算时间都会大大增加。甚至可能造成过拟合现象。而小数据分布不均衡运用该方法还能避免数据量太少引起的欠拟合。
2.欠采样
欠采样也被称为下采样,一般将将较大的类别数据进行缩减,直至和类型不同的小量数据集相对等。如我们将例子一的数据进行欠采样,13w的用户行为数据将缩减至6730条数据,进行建模的速度将会大大的加快。
由于该数据集中已经进行了数据预处理故本篇博客不详细展开数据预测理案例讲解,感兴趣的同学可以去看博主以往机器学习模型文章。
4.数据可视化
这里我们肯定想到如果把这个数据画成一张图就好了,就类似我们将Excel的列表数据转换为图表一样,python也可以实现类似效果,这里只需要我们导入matplotlib库就好了:
我们可以选择matplotlib的字体和主题,以及颜色和输出方式。
import matplotlib.pyplot as plt
from matplotlib import font_manager # 导入字体管理模块
plt.style.use('ggplot')
单变量图表
单变量图表可以显示每一个单独的特征属性,因为每个特征属性都是数字,因此我们可以通过向线图来展示属性与中位值的离散速度:
这里要注意一下中文字体会出现报错,需要设置指定默认字体。
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
iris_data_df.plot(kind='box',subplots=True,layout=(2,2))
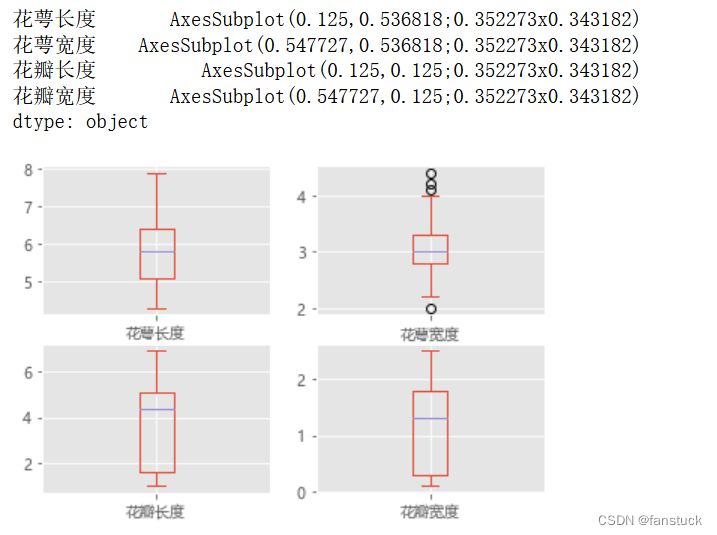
也可以通过直方图来显示每个特征属性的分布状况:
iris_data_df.hist()
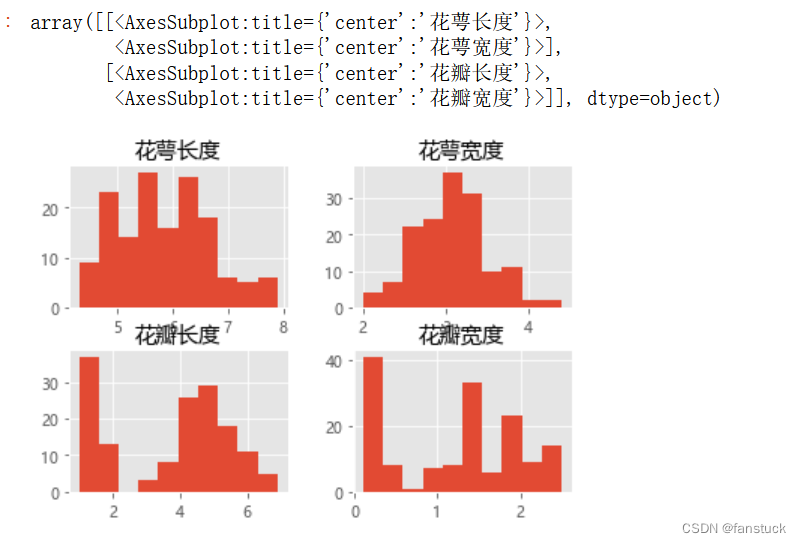
我们会发现花萼长度和花萼宽度、花瓣长度都是符合高斯分布的。
多变量图表
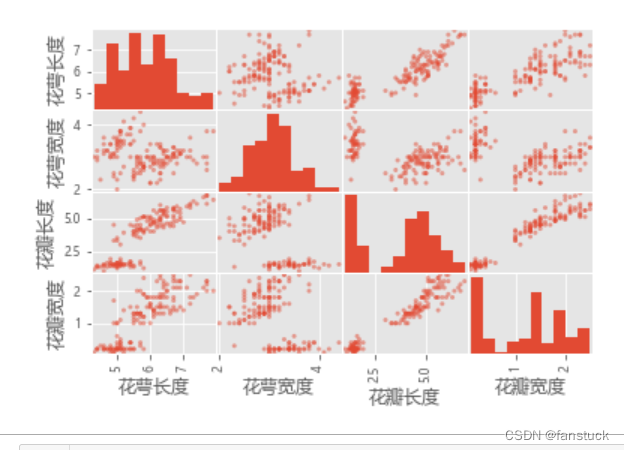
通过多变量图表可以查看不同特征属性之间的关系。我们通过散点矩阵图来查看每个属性之间的影响关系。
#散点矩阵图
scatter_matrix(iris_data_df)
## 第一步,先定义1张空白的大画板
fig=plt.figure(num=1, figsize=(16, 16))
## 增加1个子图,2x2,共4个子图,排第1个
ax1 = fig.add_subplot(221)
ax1.scatter(x=iris_true_df.iloc[:,0:1], y=iris_true_df.iloc[:,4:5],color='k',alpha=0.5)
## 增加1个子图,2x2,共4个子图,排第2个
ax2 = fig.add_subplot(222)
ax2.scatter(x=iris_true_df.iloc[:,1:2], y=iris_true_df.iloc[:,4:5],alpha=0.5)
## 增加1个子图,2x2,共4个子图,排第3个
ax3 = fig.add_subplot(223)
ax3.scatter(x=iris_true_df.iloc[:,2:3], y=iris_true_df.iloc[:,4:5],color='tan',alpha=0.5)
## 增加1个子图,2x2,共4个子图,排第4个
ax4 = fig.add_subplot(224)
ax4.scatter(x=iris_true_df.iloc[:,3:4], y=iris_true_df.iloc[:,4:5],color='c',alpha=0.5)
可能初学接触matplotlib觉得有些复杂,但是经常使用很快就记得函数使用方法:
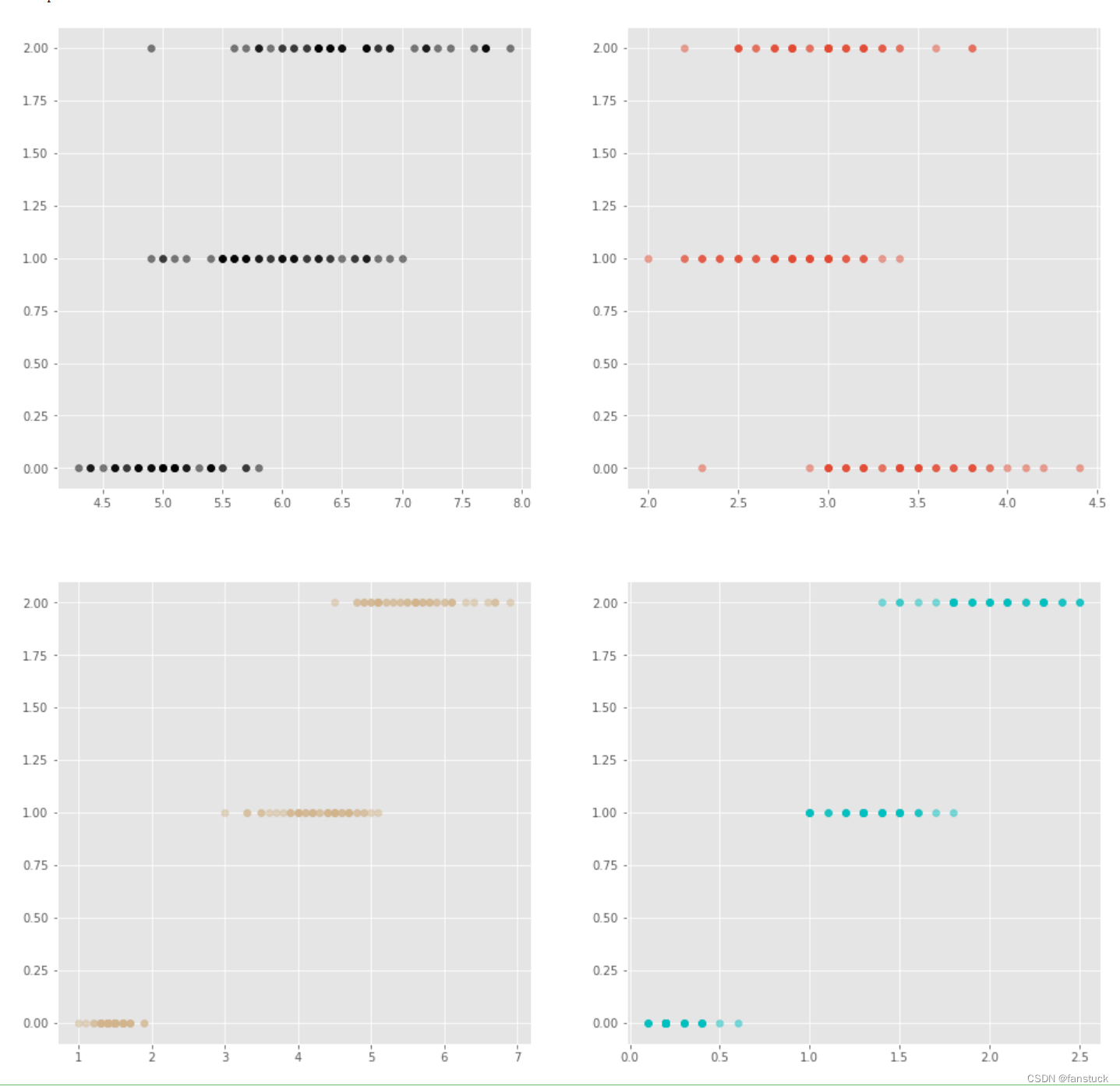
我们可以很直观的发现每个品种的花的各个维度特征都是明显可以区分的,都存在很大的差异性。这样以来我们可以开始进行模型的建立和训练了。
5.训练模型
我们需要一部分的数据用来训练模型,一部分的数据用来验证模型的准确度,以便我们找到最合适的算法。
5.1划分数据集
一般划分数据集我们采取2/8切分,其中80%的数据用作训练,20%的数据用作验证。
from sklearn.model_selection import train_test_split
iris_array=iris_true_df.values
X=iris_array[:,0:4]
Y=iris_array[:,4]
test_model=0.2
seed=5
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=test_model,random_state=seed)
5.2评估算法
我们这里就使用十折交叉验证法来评估算法的准确度。十折交叉验证就是随机将数据分成10份:9份用来训练模型,1份用来评估算法。
from sklearn.model_selection import KFold
KFold和K-折验证是一样的。也就是将一份数据集划分成为K份,拿其中的一份用作验证,剩下的k-1份数据用作训练。因此,该KFold这个类也不难理解,也是起数据划分之用。
5.3模型建立
我们使用sklearn十分方便的一点就是模型只需要import引入就好了,不需要我们做底层的计算逻辑。项目前期大家可以调用各种算法来进行测试,但是如果想要真正入门机器学习还得现需要将每个算法都掌握一遍才能调优调参更加准确。
这里我们引入六种算法来进行评测:
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
然后构建六种不同的模型:
models={}
models['LR']=LogisticRegression()
models['LDA']=LinearDiscriminantAnalysis()
models['KNN']=KNeighborsClassifier()
models['CART']=DecisionTreeClassifier()
models['NB']=GaussianNB()
models['SVM']=SVC()
之后我们需要建立模型评估算法:
results=[]
for key in models:
kfold=KFold(n_splits=10,shuffle=True,random_state=seed)
cv_results=cross_val_score(models[key],X_train,Y_train,cv=kfold,scoring='accuracy')
results.append(cv_results)
print('%s:%f(%f)'%(key,cv_results.mean(),cv_results.std()))

此时此刻我们如果能够进一步使用数据可视化结果就好了:
#箱线图
fig=pyplot.figure()
fig.suptitle('Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
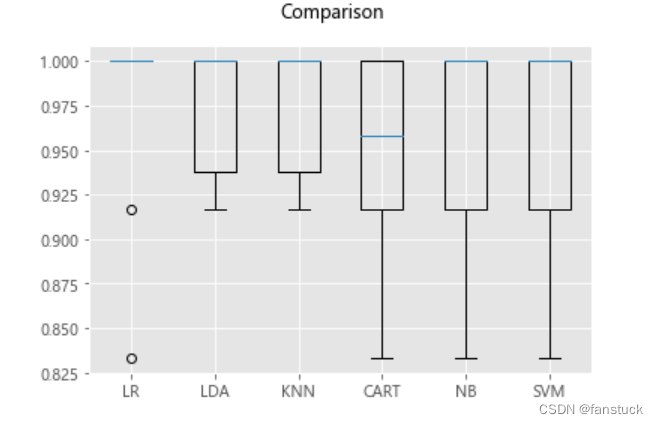
5.4模型预测
我们根据评估显示,LR逻辑回归算法是准确度最高的算法。那么我们就用预留的评估数据集给出一个算法模型报告。
LR=LogisticRegression()
LR.fit(X=X_train,y=Y_train)
predictions=LR.predict(X_test)
print(accuracy_score(Y_test,predictions))
print(confusion_matrix(Y_test,predictions))
print(classification_report(Y_test,predictions))
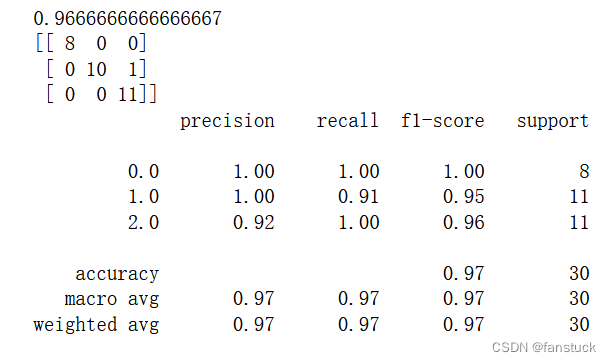
算法的准确度为96.7%,实际项目的预测准确率都是很低的,这是数据足够简单。
confusion_matrix为混淆矩阵。classification_report提供了每个类别的预测情况,精准率,召回率,F1。
那么到此我们就已经完成了第一个机器学习项目,是一个很标准的建模流程。从导入数据到数据可视化、数据预处理到模型建立和评估,一个方面拆分包含的学问都有很多。相应的每个课题都值得我们去深入了解挖掘。而sklearn能够快速建立模型,更加方便我们调整参数,可以算是机器学习速成库了。但是想要该更加准确的选择算法以及构建出融合以及更高级的模型,需要对整个机器学习算法模型有更加清楚的认知。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。