
在1994年首次提出的一种关联规则挖掘算法,它可以在特定类型的数据中找到关系,并将其表示为规则。关联规则挖掘最常用于营销,特别是在购物车的上下文中。这个应用领域被正式称为“购物车分析”。
我们这里假设学校建立了一个在线学习的网站,通过学生将课程添加到课程列表(虚拟购物车)来评估不同的课程。我们最后生成了一个文件,每一行都包含一个学生考虑同时参加的课程的列表。例如,如果一个学生考虑在 2020 年秋季参加经济学 101 和生物学 100,我们的 csv 文件中会有一行如下所示:
ECON_101, BIOL_100
从最广泛的角度来说,apriori算法通过产品的组合,计算关于产品之间关系强度的一些度量(支持度、置信度、提升度),并将这些关系表示为规则。
Apriori algorithm
与其他一些机器学习算法相比,apriori的结果似乎非常简单,但它的优点是可以很容易地理解输出结果。如果这种通用方法对Amazon来说足够好,那么对我来说也足够好。
在开始之前我们先看看一些需要掌握的关键词:
Itemsets:这个单词翻译为项集,其实我觉得产品组合更好,因为它是再购物车中同时购买的产品的集合。在本文中中,它是学生在同一学期考虑参加的课程列表,因为我们上面说了课程的选择可以理解为“购物车”。项集的另一个示例是一般商铺中购物车同时购买的产品,例如“面包、鸡蛋、尿布”。
- Antecedent:itemset中的第一个产品,可以成为前件
- Consequent:itemset中的第二个产品,可以成为后件
- Rule:antecedent → consequent 的关系
也就是说我们的要在这个Itemsets中找到Antecedent和Consequent的关系规则rule。
用上面的例子,我们知道经济学101和生物学100是联系在一起的,因为一个学生想同时修这两门课。但是他们的关系是随机的还是经常出现呢?我们将用三种方法来回答这个问题。
1、支持度 Support
支持度告诉我们一个给定项目被选择的频率。在我们的例子中,它告诉我们一个类的绝对受欢迎程度。
给定类A和提供~A(不是A)的其他类,支持度的计算为:
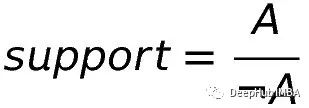
在我们的例子中,假设30个不同的学生考虑经济学101,而所有学生考虑1000个其他课程,包括那些想要学习经济学101的学生。那么我们的支持度就是:
Support= 30/1000 = 0.03
支持度越高,项目就越有可能出现在给定的项目集中。
2、置信度 Confidence
置信度是两个产品在同一个项集中的可能性。在我们的例子中,如果我们考虑经济学101,那么我们可能也会考虑生物学100。所以,给定类A和类B:
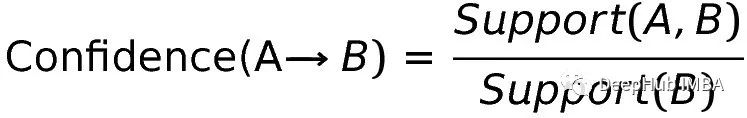
换句话说,它是生物学100和经济学101在同一购物车中的可能性除以经济学101在任意购物车中的次数。
如果置信度= 1,只要经济101出现了那么生物100必出现。如果置信度= 0.75,那么经济学101出现了有75%可能生物100出现。
3、提升度 Lift
提升度为我们提供了两个产品之间关系的最佳例证。对于A类和B类,
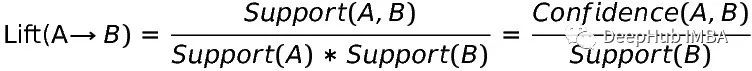
提升度有三种情况:
1,那么一个学生很可能在上经济学101的同时上生物100。(该学生将选B课,因为他们正在选a课)举个例子,如果lift = 3.33,那么一个学生在同一学期选修经济学101和生物100的概率是选修经济学101而不选修生物100的概率的3.33倍。
< 1,那么这个学生不太可能同时修生物100和经济学101。(该学生不会选B课,因为他们选的是a课)
= 1,则两项之间没有关系。
了解了上面的3个度量,我将用文字来解释算法的基本细节,然后在最后给出一些伪代码来总结它。在apriori的所有实现中,都需要为算法提供一个最小支持度值,min_sup。
首先,apriori算法找出所有支持度在最小支持度或最小支持度以上的条目。如果min_sup = 0.01,那么算法只会为至少出现在1/100个项集生成规则。
然后,apriori查找所有频繁出现的包含2个项集(支持度大于或等于min_sup)。然后是3个,然后是4个,以此类推,直到算法遍历完所有的第一步找到项集项。在这里每一步中,它会清除虽然出现了但不太频繁的项目,这样可以消除虚假关系。
最后,apriori从支持度大于最小阈值的项集中选取所有规则,计算并报告支持度、置信度和提升度。

算法的计算成本很高,因为它会多次检查相同的数据。大O是2^|D|,其中|D|是所有项集中出现的产品的总数,并且它很容易受到虚假关联的影响。但是关联规则不受因变量个数的限制,能够在大型数据库中发现数据之间的关联关系,所以其应用非常广泛,但是他是否可以应用于所有系统呢?Apriori并不是适用于所有类型的数据集。
Apriori algorithm为什么不适用于某些产品
下面我们使用一个电子商务平台的事件数据【查看,添加到购物车,购买】,包括所有的电子品牌。其目的是确定影响购买几种产品的不常见规则。由于三星和苹果总共占了57%的数据,我们只关注这两个品牌的购买情况。
数据集为:
- Market Basket Analysis Data | Kaggle
- eCommerce behavior data from multi-category store | Kaggle
“transaction 交易”指的是购买一个或多个物品。每个“交易”都有一个惟一的用户会话ID。
“purchase 购买”指的是只购买该物品的一个数量。多个“购买”可以有一个普通的用户会话ID。
在删除“查看”和“添加到购物车”记录后,我们假设数据集中的每一行都与购买该商品的一个数量有关。这些个人购买按用户会话 ID 分组,从而产生不同的交易。
我们在 python 上使用 Apriori 算法分别为苹果和三星进行购物车分析。由于许多单独的项目交易,我们不得不将指标阈值降低到小数点后几位。
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
def hot_encode(x):
if(x<= 0):
return 0
if(x> 0):
return 1
def RuleMiner(dataframe, min_support_popular_set=0.001,min_support_rules=0.001, metric='lift'):
"""Function to get rules based on the support threshold and metric.
dataframe: Dataframe which contains the transactions in the specified schema.
min_support_set: The threshold for filtering the frequent item sets having more support value than threshold.
min_support_rules: The threshold for filtering the rules having metric value more than threshold
metric: lift, support, confidence"""
df=dataframe
msPS = min_support_popular_set
msAR = min_support_rules
metric=metric
prod_counts = df.groupby(by='user_session')[['productType']].count()
df_prod_count_combined = pd.merge(df,prod_counts, on='user_session')
df_prod_count_combined.rename(columns = {'productType_x':'productType'}, inplace = True)
df_prod_count_combined.rename(columns = {'productType_y':'quantity'}, inplace = True)
basket = df_prod_count_combined.groupby(
['user_session','productType'])['quantity'].sum().unstack().reset_index().fillna(0).set_index('user_session')
basket_model = basket.applymap(hot_encode)
popular_sets = apriori(basket_model, min_support=msPS, use_colnames=True, verbose = 1)
popular_sets['length'] = popular_sets['itemsets'].apply(lambda x: len(x))
rules = association_rules(popular_sets, metric=metric, min_threshold = msAR)
rules = rules.sort_values(['lift'], ascending =[False])
#rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
return rules
RuleMiner(sam_df,min_support_popular_set=0.0005,min_support_rules=0.0005)
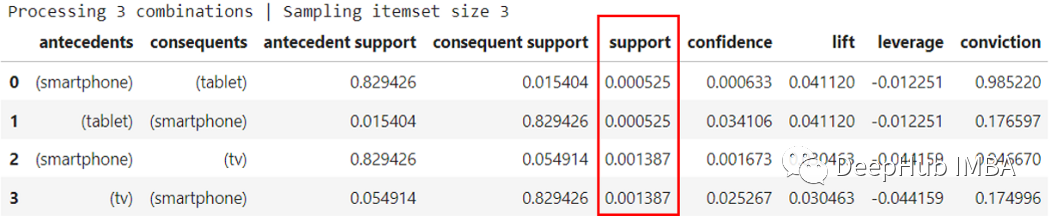
RuleMiner(sam_df,min_support_popular_set=0.00005,min_support_rules=0.0005, metric='confidence')
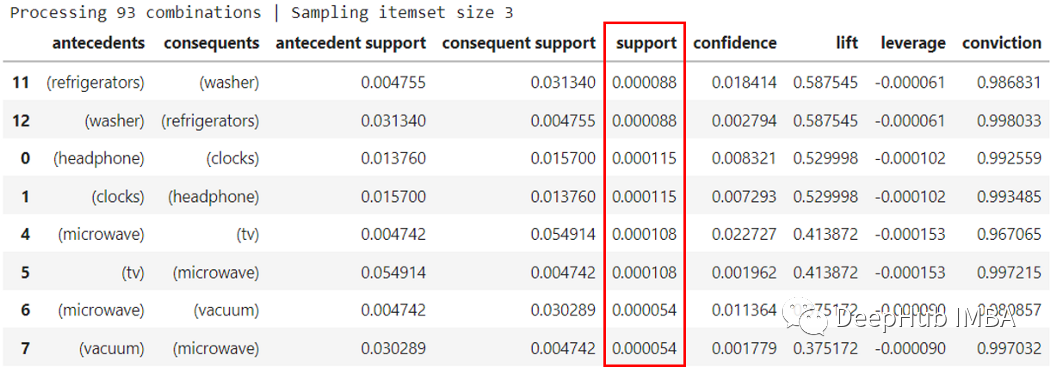
可以看到的支持度都非常低,我们找不到任何两个给定项目之间的任何重要关联规则。为了验证我们的方法是否正确,我们在第二个数据集上运行了相同的代码。
我们发现如果先购买“莳萝”,购买“鸡蛋”的置信度为 0.39。同时,如果先购买“鸡蛋”,则购买“莳萝”的可能性约为 0.41。
warnings.filterwarnings('ignore')
popular_sets = apriori(df2, min_support=0.1, use_colnames=True, verbose = 1)
popular_sets['length'] = popular_sets['itemsets'].apply(lambda x: len(x))
rules = association_rules(popular_sets, metric='confidence', min_threshold = 0.001)
rules = rules.sort_values(['lift'], ascending =[False])
rules
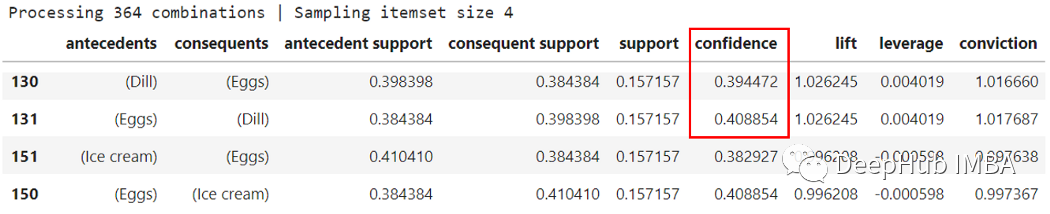
置信度并不总是一种确定购买物品 B 的机会是否取决于购买物品 A 的衡量标准。如果任何两个给定物品的提升度相同,则物品的顺序购买不应该不同。
我们返回到第一个数据集,并删除所有单品的交易,并且这次加入了所有品牌的交易,而不仅仅是苹果或三星。
返回了大量提升值和显着置信度值的规则。对于具有各种项集的许多不同规则,支持度为 0.000205(仅供参考,所有规则中的最高支持值)。可以看到这些项集只是相同购买的不同组合但是代表相同的交易。在总共 58435 个交易中,支持度 都为0.000205 ,因此这些项目之间无法建立显着的关联规则。

这是为什么呢?
Apriori算法不适用于所有类型的数据集,它适用于产品很多,并且有很大可能同时购买多种产品的地方,例如,在杂货店或运动器材商店或百货商店等。而电子产品的品类不多,并且非常昂贵,所以很少有交易频繁地同时购买多种产品。在这种情况下,Apriori对于寻找有意义的关联规则是没有用的。
另外就是即使在适用Apriori的地方,考虑的最重要指标也应该是支持度,因为高的支持度表明给定产品组合的交易数量较多。并且如果提升值大于1,可以得出关联规则是显著的,才可以进一步探索,以获得更大的收益。