
最近自我监督学习被重视起来。昨天我通过LinkedIn发现了这项工作,我觉得它很有趣。kaiming大神的MAE为ViT和自监督的预训练创造了一个新的方向,本篇文章将介绍Masked Siamese Networks (MSN),这是另一种用于学习图像表示的自监督学习框架。MSN 将包含随机掩码的图像视图的表示与原始未遮蔽的图像的表示进行匹配。
考虑一个大的未标记图像集D = (x_i)和一个小的带注释图像集S = (x_si, y_i),其中len(D) >> len(S)。这里,S中的图像可能与数据集D中的图像重叠。我们的训练目标是通过对D进行预训练来学习视觉表示,然后使用S将表示转移/微调到监督任务中。
Masked Siamese Networks

如果你对 ViT比较熟悉,下面要讨论的内容应该很熟悉。我们通过将每个视图转换为一系列不重叠的 NxN 块“Patchs”。然后论文作者介绍了通过一些随机的掩码来遮蔽图像并获得一个该图像的增强。在上图中可以看到两种策略,无论使用那种策略我们得到了分块(Patch)后的目标序列 x{+}_i 及其对应的掩码序列 x_i,m,其中后者会明显短于目标。
编码器 ViT 的目标是学习掩码的表示。 最后通过[CLS] token 得到一个序列的表示。
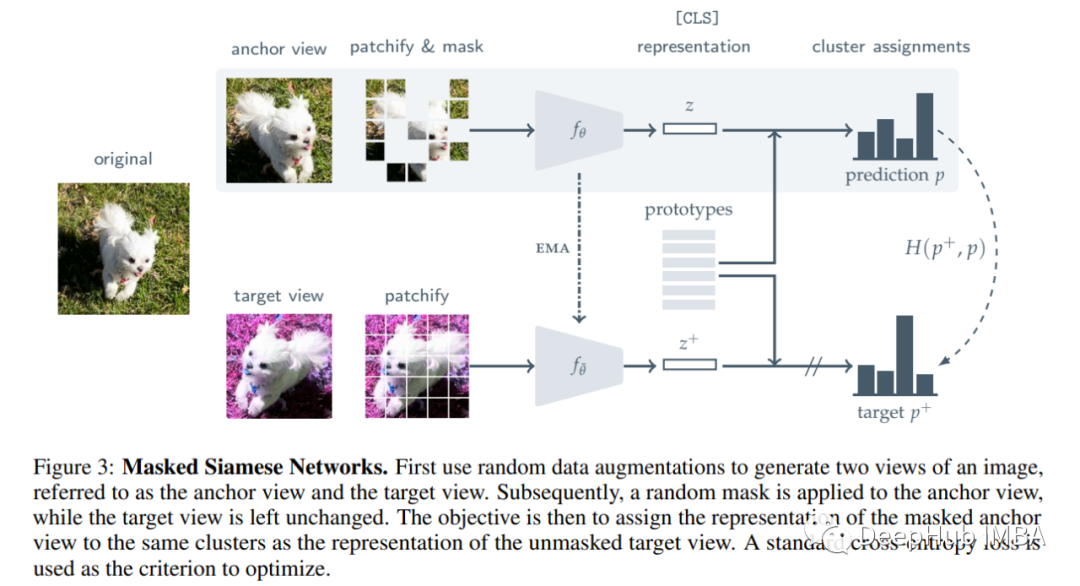
作者引入了一个矩阵q,它由K (K>1)个可学习原型(prototypes)组成,每个原型的维数为d。首先,我们分别得到掩码序列(patchfied & mask)和目标序列(patchfied only)的表示,z_i,m和z_i。然后使用L2归一化该表示,相应的预测(p)通过测量原型矩阵q的余弦相似度来计算。Tau表示一个温度参数,在(0,1)之间。注意,作者在计算目标预测时使用了一个更大的温度值,这隐式地引导网络产生自信的低熵锚预测。
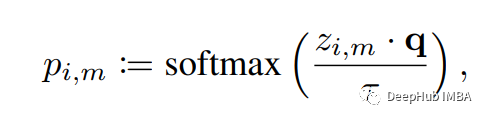
最后,目标函数为
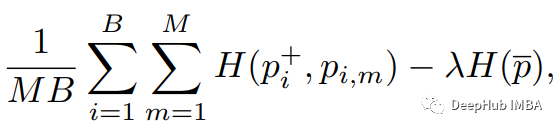
其中第一项表示标准交叉熵损失(H),第二项是MIN-MAX正则化器,它寻求最大化所有掩码序列(p_i,m), p_hat的平均预测的熵。
这里需要注意的有3点问题:
1、仅针对锚预测 p_i,m 计算梯度。2、在标准对比学习中,明确鼓励两个视图接近的表示。MSN 通过鼓励 2 个视图与可学习原型的距离来做到这一点,这可以被视为某种集群质心。两个视图的表示应该落入嵌入空间中的同一点。此外超参数中可学习原型的数量,作者使用了 1024 (与批大小匹配),维度 d 设置为 256。3、MAE 也提出了掩蔽图像。然而,MAE 尝试从其蒙面视图重建图像,而 MSN 直接尝试最大化两个视图表示的相似性。
结果
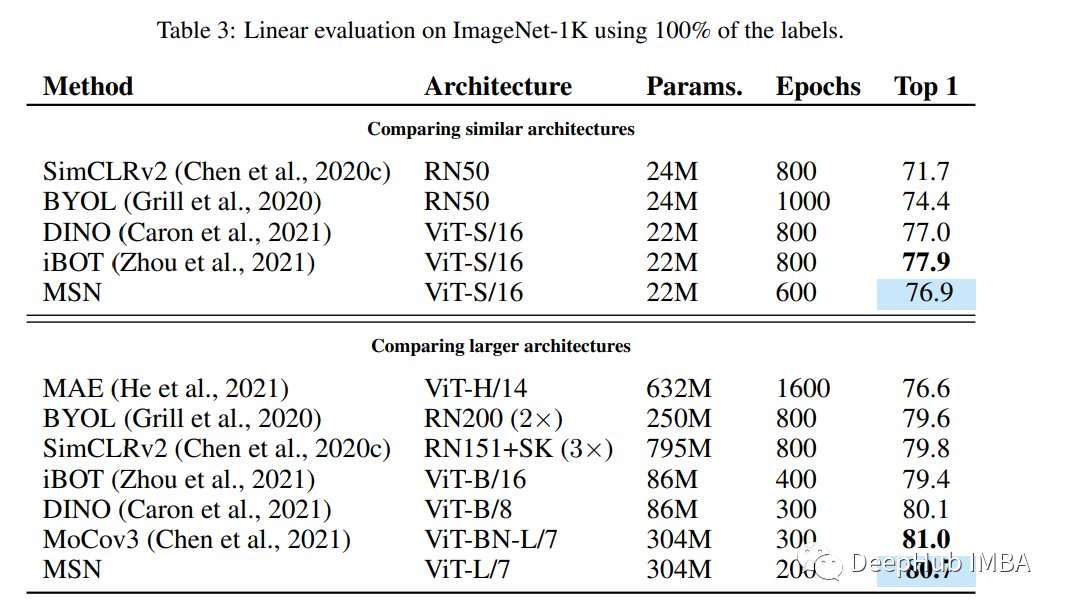
MSN 在 ImageNet-1K 上的线性评估方面优于 MAE 和其他模型。并且比较 MSN 和 MAE 很有趣,因为它们都引入了掩码。这可能是该领域未来工作的一个有见地的发现。作者还发现 Focal Mask 策略会降低性能,而 Random Mask 通常会提高性能。但是同时应用这两者会有显着的改进。还记得吗,MAE 仅使用随机掩蔽。

最后,当增加模型大小时,作者发现增加掩蔽率(丢弃更多块)有助于提高少样本性能。

我希望你觉得这篇文章对你的学习有帮助和/或有趣。论文地址在这里:
Masked Siamese Networks for Label-Efficient Learning
https://arxiv.org/abs/2204.07141
作者:ching