
回归分析预测世界大学综合得分
大学排名是一个非常重要同时也极富挑战性与争议性的问题,一所大学的综合实力涉及科研、师资、学生等方方面面。目前全球有上百家评估机构会评估大学的综合得分进行排序,而这些机构的打分也往往并不一致。在这些评分机构中,世界大学排名中心(Center for World University Rankings,缩写CWUR)以评估教育质量、校友就业、研究成果和引用,而非依赖于调查和大学所提交的数据著称,是非常有影响力的一个。
本任务中我们将根据 CWUR 所提供的世界各地知名大学各方面的排名(师资、科研等),一方面通过数据可视化的方式观察不同大学的特点,另一方面希望构建机器学习模型(线性回归)预测一所大学的综合得分。
世界大学综合得分预测
数据来源:World University Rankings | Kaggle
数据观察与处理:
import pandas as pd
import numpy as np
data_df = pd.read_csv('./cwurData.csv')
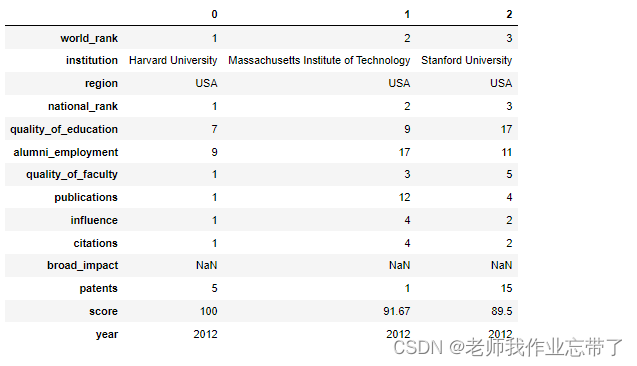
data_df.head(3).T # 观察前几列并转置方便观察
去除其中包含 NaN 的数据
data_df = data_df.dropna()
len(data_df) # 2000
设置矩阵
feature_cols = ['quality_of_faculty', 'publications', 'citations', 'alumni_employment',
'influence', 'quality_of_education', 'broad_impact', 'patents'] # 提取特征值
X = data_df[feature_cols]
Y = data_df['score']
# X Y分别为自变量 因变量矩阵
数据可视化
观察世界排名前十学校的平均得分情况,为此需要将同一学校不同年份的得分做一个平均。我们可以利用
groupby()
函数,将同一学校的记录整合起来并通过
mean()
函数取平均。之后我们按平均分降序排序,取前十个学校作为要观察的数据。
import matplotlib.pyplot as plt
import seaborn as sns
mean_df = data_df.groupby('institution').mean() # 按学校聚合并对聚合的列取平均
top_df = mean_df.sort_values(by='score', ascending=False).head(10) # 取前十学校
sns.set()
x = top_df['score'].values # 综合得分列表
y = top_df.index.values # 学校名称列表
sns.barplot(x, y, orient='h', palette="Blues_d") # 画条形图
plt.xlim(75, 101) # 限制 x 轴范围
plt.show()

用
pairplot
的方法观察变量之间的关联关系,可以从图中看到,少部分变量之间有线性关系;各个变量和结果之间,近似对数关系。
sns.pairplot(data_df[feature_cols + ['score']], height=3, diag_kind="kde")
plt.show()

还可以用热力图的形式呈现相关度矩阵:

构建模型
取出对应自变量以及因变量的列,之后就可以基于此切分训练集和测试集,并进行模型构建与分析。
all_y = data_df['score'].values
all_x = data_df[feature_cols].values
# 取 values 是为了从 pandas 的 Series 转成 numpy 的 array
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(all_x, all_y, test_size=0.2, random_state=2020)
all_y.shape, all_x.shape, x_train.shape, x_test.shape, y_train.shape, y_test.shape # 输出数据行列信息
# ((2000,), (2000, 8), (1600, 8), (400, 8), (1600,), (400,))
from sklearn.linear_model import LinearRegression
LR = LinearRegression() # 线性回归模型
LR.fit(x_train, y_train) # 在训练集上训练
p_test = LR.predict(x_test) # 在测试集上预测,获得预测值
test_error = p_test - y_test # 预测误差
test_rmse = (test_error**2).mean()**0.5 # 计算 RMSE
'rmse: {:.4}'.format(test_rmse)
# rmse: 3.999
得到测试集的 RMSE 为 3.999,在百分制的预测目标下算一个尚可的结果。从评价指标上看貌似我们能根据各方面排名较好的预估综合得分,接下来我们观察一下学习到的参数,即各指标排名对综合得分的影响权重。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
sns.barplot(x=LR.coef_, y=feature_cols)
plt.show()
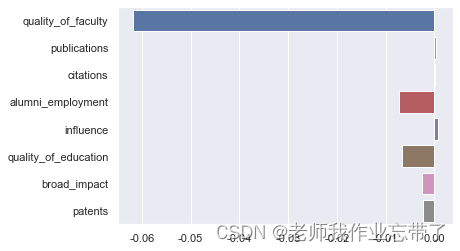
这里会发现综合得分的预测基本被「师资质量」这一自变量主导了,「就业」和「教育质量」这两个因素也有一定影响,其他指标起的作用就很小了。
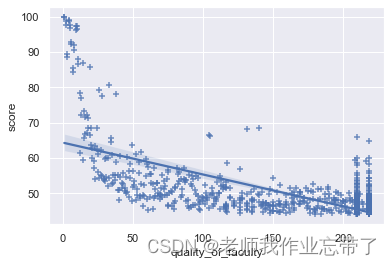
为了观察「师资质量」这一主导因素与综合得分的关系,我们可以通过 seaborn 中的
regplot()
函数以散点图的方式画出其分布。
sns.regplot(data_df['quality_of_faculty'], data_df['score'], marker="+")
plt.show()
版权归原作者 老师我作业忘带了 所有, 如有侵权,请联系我们删除。