
无监督学习(Unsupervised Learning)是和监督学习相对的另一种主流机器学习的方法,无监督学习是没有任何的数据标注只有数据本身。
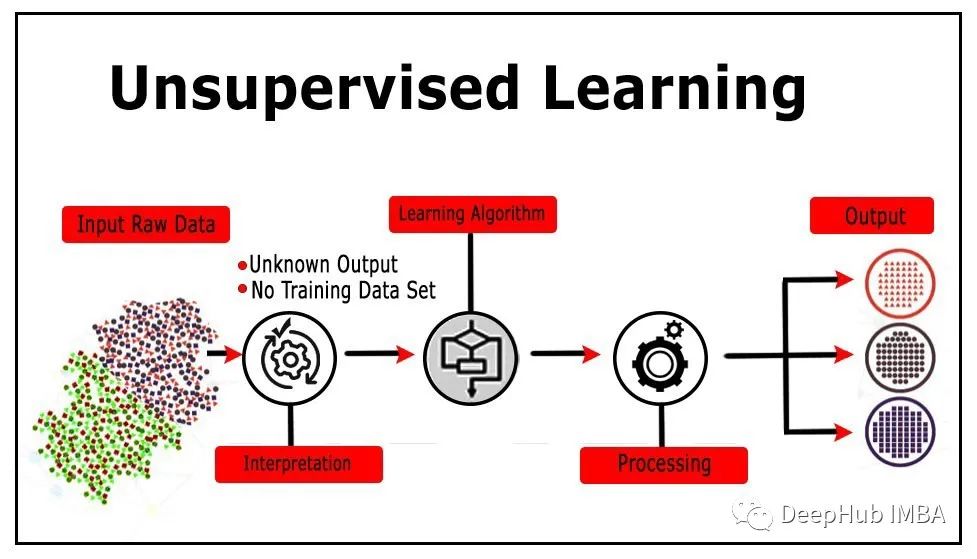
无监督学习算法有几种类型,以下是其中最重要的12种:
1、聚类算法根据相似性将数据点分组成簇
k-means聚类是一种流行的聚类算法,它将数据划分为k组。
2、降维算法降低了数据的维数,使其更容易可视化和处理
主成分分析(PCA)是一种降维算法,将数据投影到低维空间,PCA可以用来将数据降维到其最重要的特征。
3.异常检测算法识别异常值或异常数据点
支持向量机是可以用于异常检测(示例)[26]。异常检测算法用于检测数据集中的异常点,异常检测的方法有很多,但大多数可以分为有监督和无监督两种。监督方法需要标记数据集,而无监督方法不需要。
无监督异常检测算法通常基于密度估计[20],试图找到数据空间中密集的区域外的点。
一个简单的方法是计算每个点到k个最近邻居的平均距离。距离相邻点非常远的点很可能是异常点。
还有很多基于密度的异常检测算法,包括局部离群因子(Local Outlier Factor,LOF)和支持向量数据描述(Support Vector Domain Description,SVDD)。这些算法比简单的k近邻方法更复杂,通常可以检测到更细微的异常[21]。大多数异常检测算法都需要进行调整,例如指定一个参数来控制算法对异常的敏感程度。如果参数过低,算法可能会漏掉一些异常。如果设置过高,算法可能会产生误报(将正常点识别为异常点)。
4、分割算法将数据分成段或组[12]
分割算法可以将图像分割为前景和背景。
这些算法可以在不需要人工监督的情况下自动将数据集分割成有意义的组。这个领域中比较知名的一个算法是k-means算法。该算法通过最小化组内距离平方和将数据点分成k组。
另一种流行的分割算法是mean shift算法。该算法通过迭代地将每个数据点移向其局部邻域的中心来实现。mean shift对异常值具有较强的鲁棒性,可以处理密度不均匀的数据集。但是在大型数据集上运行它的计算成本可能很高。
高斯混合模型(GMM)是一种可用于分割的概率模型。以前gmm需要大量的计算来训练,但最近的研究进展使其更快。gmm非常灵活,可以用于任何类型的数据。但是它们有时并不能总是产生最好的结果。对于简单的数据集,k-means是一个很好的选择,而gmm则更适合于复杂的数据集。mean shift可以用于任何一种情况,但在大型数据集上计算的成本会很高。
5、去噪算法减少或去除数据中的噪声
小波变换可以用于图像去噪。但是各种来源可能会产生噪声,包括数据损坏、缺失值和异常值。去噪算法通过减少数据[10]中的噪声量来提高无监督学习模型的准确性。
现有的去噪算法有多种,包括主成分分析(PCA)、独立成分分析(ICA)和非负矩阵分解(NMF)[11]。
6、链接预测算法预测数据点之间的未来连接(例如,网络中两个节点之间的未来交互)
链接预测可用于预测哪些人将成为社交网络中的朋友。更常用的链接预测算法之一是优先连接算法[15],它预测如果两个节点有许多现有连接,则它们更有可能被连接。
另一种流行的链路预测算法是局部路径算法,它预测如果两个节点共享一个共同的邻居[27],那么它们更有可能被关联。该算法可以捕获“结构等价”[16]的概念,因此在生物网络中经常使用。
最后,random walk with restart算法也是一种链路预测算法,它模拟网络上的一个随机走动的人,在随机节点[17]处重新启动步行者。然后,步行者到达特定节点的概率被用来衡量两个节点之间存在连接的可能性。
7、强化学习算法通过反复试验来进行学习
Q-learning是基于值的学习算法[1]的一个例子;它实现简单并且通用。但是Q-learning有时会收敛到次优解[18]。另一个例子是TD learning,它在计算上Q-learning学习要求更高,但通常可以找到更好的解决方案[19]。
8、生成模型:算法使用训练数据生成新的数据
自编码器是生成模型,可用于从图像数据集创建独特的图像。在机器学习中,生成模型是一种捕捉一组数据的统计属性的模型。这些模型可以用来生成新的数据,就像它们所用的训练的数据一样。
生成模型用于各种任务,如无监督学习,数据压缩和去噪[22]。生成模型有很多种,比如隐马尔可夫模型和玻尔兹曼机[22]。每种模型都有其优缺点,并且适用于不同的任务。
隐马尔可夫模型擅长对顺序数据建模,而玻尔兹曼机器更擅长对高维数据[22]建模。通过在无标记数据上训练它们,生成模型可以用于无监督学习。一旦模型经过训练,就可以用来生成新的数据。然后这些生成的数据可以由人类或其他机器学习算法进行标记。这个过程可以重复,直到生成模型学会生成数据,就像想要的输出。
9、随机森林是一种机器学习算法,可用于监督和无监督学习[9]
对于无监督学习,随机森林可以找到一组相似的条目,识别异常值,并压缩数据[9]。
对于监督和无监督任务随机森林已被证明优于其他流行的机器学习算法(如支持向量机)[9]。随机森林是无监督学习的一个强大工具,因为它们可以处理具有许多特征的高维数据。它们也抵制过拟合,这意味着它们可以很好地推广到新数据。
10、DBSCAN是一种基于密度的聚类算法,可用于无监督学习
它基于密度,即每个区域的点的数量。如果 DBSCAN 的组内的点很靠近,则将它们指向一个组,如果点相距较远的点则会忽略。与其他聚类算法相比,DBSCAN具有一些优势。它可以找到不同大小和形状的簇,并且不需要用户预先指定簇的数量[23] [28]。此外,DBSCAN对异常值不敏感,这意味着它可以用来找到其他数据集没有很好地表示的数据。但是DBSCAN也有一些缺点。例如,它可能很难在噪声很大的数据集中找到良好的簇。另外就是DBSCAN需要一个密度阈值,这可能不适用于所有数据集[23]。
11、Apriori算法用于查找关联、频繁项集和顺序模式 [24]
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它·的工作原理是首先找到数据中的所有频繁项集,然后使用这些项集生成规则。
Apriori算法的实现方式有很多种,可以针对不同的需求进行定制。例如,可以控制支持度和置信度阈值以找到不同类型的规则 [24]。
12、Eclat算法从事务数据库中挖掘频繁项目集,可用于购物车分析、入侵检测和文本挖掘[25]
Eclat算法是一种深度优先算法,采用垂直数据表示形式,在概念格理论的基础上利用基于前缀的等价关系将搜索空间(概念格)划分为较小的子空间(子概念格)。
以上就是无监督学习中常用的算法, 如果你对他们感兴趣,请详细查看下面的引用(很长,建议之查看感兴趣的)
*An introduction to Q-Learning: reinforcement learning:*https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/
*2. Q-learning video walkthrough:*https://www.youtube.com/watch?v=4dcgjcuR-1o
*3. Unsupervised learning: clustering with DBSCAN:*https://web.cs.dal.ca/~kallada/stat2450/lectures/Lecture15.pdf
*4. DBSCAN clustering algorithm in machine learning:*https://www.kdnuggets.com/2020/04/dbscan-clustering-algorithm-machine-learning.html
5. Unsupervised Learning of Global Factors in Deep Generative Models. arXiv:2012.08234
6. Harshvardhan GM, Mahendra Kumar Gourisaria, Manjusha Pandey, Siddharth Swarup Rautaray, A comprehensive survey and analysis of generative models in machine learning, Computer Science Review, Volume 38, 2020, 100285, ISSN 1574–0137,https://doi.org/10.1016/j.cosrev.2020.100285.
*7. Boosting:*https://aws.amazon.com/what-is/boosting/
*8. Bagging:*https://www.ibm.com/cloud/learn/bagging
9. Breiman, L. (2001). Random forests. Machine learning, 45(1), 5–32.
10. Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer Science & Business Media.
11. Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
*12. Machine Learning Techniques for the Segmentation of Tomographic Image Data of Functional Materials.*https://www.frontiersin.org/articles/10.3389/fmats.2019.00145/full
*13. Link Prediction in Complex Networks: A Survey.*https://arxiv.org/pdf/1010.0725.pdf
*14. Link Prediction.*https://neo4j.com/developer/graph-data-science/link-prediction/
*15. Preferential Attachment in Online Networks: Measurement and Explanations.*https://arxiv.org/pdf/1303.6271.pdf
*16. A novel similarity measure for mining missing links in long-path networks.*https://arxiv.org/pdf/2110.05008.pdf
*17. Fast Random Walk with Restart and Its Applications.*https://www.cs.cmu.edu/~christos/PUBLICATIONS/icdm06-rwr.pdf
*18. Q-Learning: A Tutorial and Extensions.*https://link.springer.com/chapter/10.1007/978-1-4615-6099-9_3
*19. Temporal-Difference Learning:*https://web.stanford.edu/group/pdplab/pdphandbook/handbookch10.html
*20. Machine Learning Techniques for Anomaly Detection: An Overview.*https://www.researchgate.net/profile/Salima-Benqdara/publication/325049804_Machine_Learning_Techniques_for_Anomaly_Detection_An_Overview/links/5af3569b4585157136c919d8/Machine-Learning-Techniques-for-Anomaly-Detection-An-Overview.pdf
*21. Machine Learning Approaches to Network Anomaly Detection.*https://www.usenix.org/legacy/event/sysml07/tech/full_papers/ahmed/ahmed.pdf?ref=driverlayer.com/web
22. Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective (1st ed.). MIT Press.
23. A density-based algorithm for discovering clusters in large spatial ….https://www.osti.gov/biblio/421283.
24. Rakesh, Agrawal, and Ramakrishnan Srikant. “Fast Algorithms for Mining Association Rules.”**https://www.researchgate.net/publication/2460430_Fast_Algorithms_for_Mining_Association_Rules
*25. Parker, Iqbal. Machine Learning: Algorithms, Real-World Applications, and Research Directions.*https://link.springer.com/article/10.1007/s42979-021-00592-x
*26. Anomaly Detection Using Multi Agent Systems.*https://users.encs.concordia.ca/~abdelw/papers/Khosravifar_MSc_S2018.pdf
*27. A Systematic Survey on Deep Generative Models for Graph Generation | DeepAI.*https://deepai.org/publication/a-systematic-survey-on-deep-generative-models-for-graph-generation
*28. Hierarchical K-Means Clustering: Optimize Clusters — Datanovia.*https://www.datanovia.com/en/lessons/hierarchical-k-means-clustering-optimize-clusters/
作者:Anil Tilbe