
本文将介绍如何使用深度高斯过程建模量化信号中的不确定性
先进的机器学习 (ML) 技术可以从数据中得出的非常复杂的问题的解答。但是由于其“黑盒”的性质,很难评估这些答案的正确性。如果想在照片中找到特定的人或者物,例如在照片中找到猫的照片,这可能是很适用的。但在处理医疗数据时,因为可解释性的原因一般都不会被人们所接受,这导致 ML 模型在实际临床应用中的实际使用的概率很低。在这篇文章中,将介绍一种分析生物数据的方法,它结合了现代 ML 的复杂性和经典统计方法的合理置信度评估。
本文的目标是提供
- 对生物数据使用高斯过程建模的合理性,特别是深度高斯过程 (DGP),而不是普通的静止过程
- 哈密顿蒙特卡罗 (HMC) 方法概述及介绍其对 DGP 建模的帮助
- 该方法在模拟数据示例中的应用说明
分析医疗数据的挑战
想象一下,医生正在监测一位接受过治疗的患者。假设治疗应该影响某种激素的水平。随着时间的推移,我们记录测试结果,并逐渐得到这样的图表。
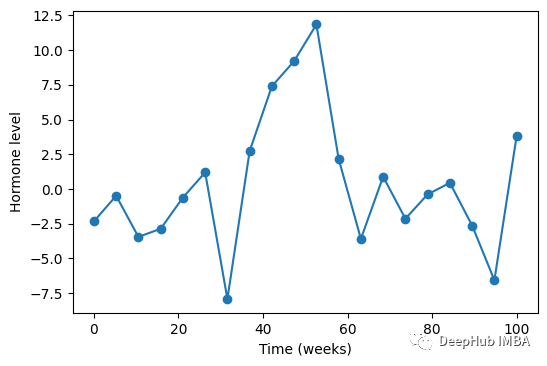
这显然是一个带有噪声的数据。我们无法立即知道发生了什么,但我们很想知道激素水平是否正在发生变化。一般情况下第一件事将数据拟合到线性回归模型,因为这是最简单的模型。但是在大多数现实世界的临床数据中,这几乎不会得到给出任何信息。所以我们要选择一种更好的方法,比如将其建模为高斯过程(GP)为什么呢是告诉过程呢?
首先,让我们回顾一下什么是高斯过程(GP)。
将临床信号视为平稳高斯过程
当执行 GP 建模时,所有数据点都被认为是从多元高斯分布中提取的
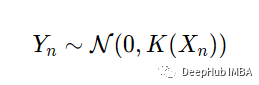
这里有两点需要注意。1)这里的K(X)是数据大小的方阵,包含非零的非对角元素;这与将数据视为n次独立随机抽取不同。2) 数据点由 X 索引,例如在我们的示例中,将顺序定义为时间 - 因此,过程就是我们需要了解的关于 GP 的全部内容。
当提到拟合 GP 时,我们的意思是找到矩阵 K(X) 的参数。为了使其更明确,让我们将 GP 模型重写为
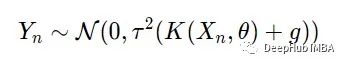
现在有了三个参数,在这里我们提出一个论点:三个参数可以被解释为捕捉尝试建模的过程的不同方面。
当我们分析随时间变化的医学信号时,我们像解决的问题是通过医学测试来评估某些生物在很多噪音的背景下进化的过程。这里可以将噪声源大致分为两类。一个是测量噪声,随着现代医学的测试变得非常复杂,会在测量时产生不同程度的偏差,这个是无法避免的。另一个来源是生物过程引起的变异,这与我们感兴趣的过程无关并且更加复杂,相对的研究也少得多。所以实际的信号(我们试图检测的过程)可能是高度非线性的,这些都会造成数据的混乱,所以一般不会对其进行精确建模,至少在可预见的未来是这样的。
但是我们可以尝试在 GP 框架中对这三个参数进行半独立的建模。比如说获得一个最有可能的结果,两个噪声源的频率和振幅不同。
- g参数是线性回归分析中随机噪声的产物。从技术上讲它是 τ²g,这是“半独立”的来源,也很容易解释。将此参数与测量噪声联系起来是最自然的,只要我们谈论的是相同类型的测量,这种类型的噪声不会因患者而异。它甚至可以通过重复测试并在进行每次训练时并保持一致。这里指定的生物噪声用 τ² 表示是因为该参数负责变化的幅度。这很可能取决于患者,但在同一患者的监测时间内或多或少保持不变。
- θ 负责描述数据点彼此之间的相关程度。如果我们正在观察正在接受治疗的患者,并且治疗实际上正在发挥作用,那么它将在连续测量中反映为强相关。因此,θ 参数是为我们试图检测的信号保留的。
GP 模型可以巧妙地满足我们将一些数学理论放在医学数据上的需求。这是比线性回归的一个很好的进步。但是有一个问题,假设模型的所有参数保持不变。这对于 g 和 τ² 参数可能很好,因为正如上面所讨论的,这两个参数归因于测量噪声和不受治疗影响的身体生物变化。但θ的就不一样了,治疗可以停止也可以改变。这会影响信号的相关性,如果我们想知道这一点就必须考虑θ的变化。
该解决方案带有一个深度高斯过程模型。就像深度神经网络一样,添加更多层。
两层GP
有许多方法可以为GP添加层。这里我们使用简单的方法:在时间指标和测量信号之间插入另一个GP
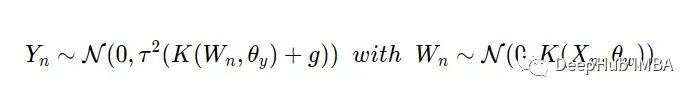
遵循引用[2]的方法,为什么这就足够了?正如我们上面提到的,我们只需要适应θ的变化。通过为时间变量引入额外的GP,我们以一种灵活的方式“扭曲”了测量时间点之间的间隔,从而产生了预期的效果。
但它也使拟合复杂化了!我们必须从这个后验分布中找到参数的最优值
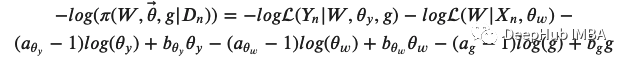
这两种可能性被定义为
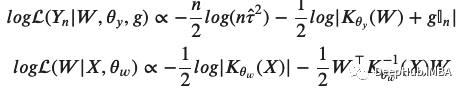
有关此表达式的推导,请参阅参考资料[2]。既然我们写出了这个“奇怪”的公式,我们就需要思考如何利用它做些有用的东西。最直接的方法是对这个分布进行数值抽样。最好的数值抽样方法是哈密顿蒙特卡洛法(HMC)!
哈密顿蒙特卡洛方法
我们需要一种明智的方法来对的分布进行抽样,这有两个原因(实际上是同一件事情的两种观点)。我们在多维空间中定义了概率分布。空间很大但概率是有限的。这意味着非零概率区域将被限制在空间的小体积中。但这个区域却是我们想要得到的。所以我们不能盲目地“扔飞镖”:1)浪费时间——我们会在概率为零的地区花费大量时间,这将是无用的;2)不准确的估计——在某些时候我们将不得不停止采样,并且我们有可能会错过非零区域。
本文的解决方案来自于将过程类比为物理学中众所周知粒子运动。想象一个带电粒子在相反电荷附近飞过空间,而你正在将一个球滑到一边。在所有这些情况下,运动的物体都被吸引并朝着锥体的底部或带相反电荷的粒子所在的地方移动。但如果它一开始有足够的速度,例如你把球推到一边,它就会在这个吸引中心周围反弹。这张图显示了——两条可能的轨迹,它们具有不同的初始速度或动量,在物理学中,绿色的动量比红色的大,所以它在离中心更远的地方花更多的时间。但他们俩都在朝着这个方向前进。
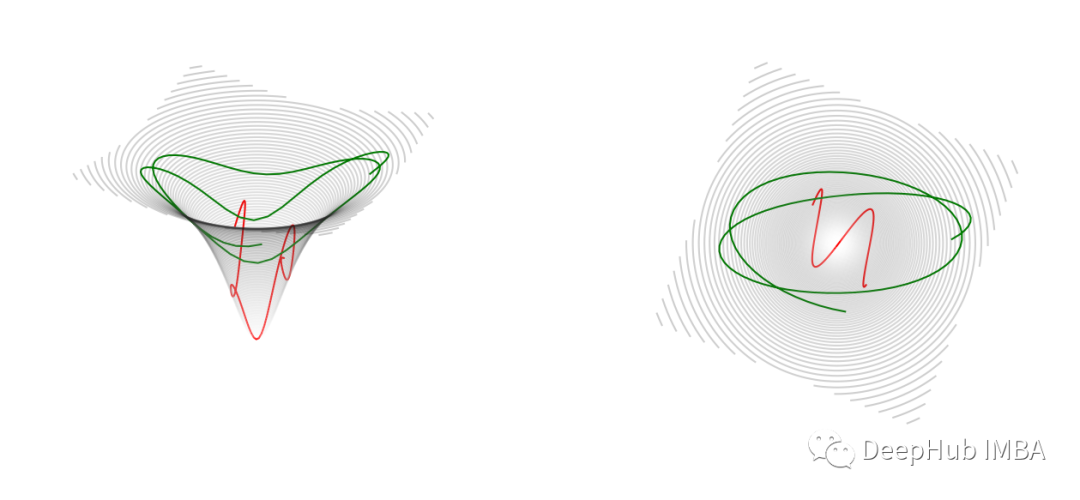
这种情况在理论力学中由哈密顿方程描述
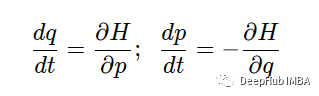
这里
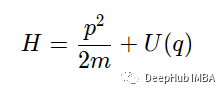
是动能和势能的总和。这个方程不仅简单而且看起来还非常的优雅。
使用HMC
现在要做的就是概率分布是 U,也就是势能。为了把它颠倒过来,需要在它前面加上一个减号,因为它已经写在我们的方程中,并通过求解具有不同动量值的哈密尔顿方程,探索最大值附近的区域。HMC的很多细节可以在参考文献[3]中找到。这是我为生成这样的轨迹而编写的示例代码。
def hamiltonian_monte_carlo(U, grad_U, current_position, steps=1, delta_t=0.5, change_step = False, masses = None):
q = np.copy(current_position)
p = np.random.normal(0.0,1.0,len(q))
current_momentum = np.copy(p)
if masses is None:
masses = np.ones(len(p))
q, p, path = leapfrog(q,p,grad_U,steps,delta_t,change_step, masses)
current_U = U(current_position)
current_K = sum(current_momentum*current_momentum/masses) / 2
proposed_U = U(q)
proposed_K = sum(p*p/masses) / 2
if (np.log(np.random.rand()) < (current_U-proposed_U+current_K-proposed_K)):
return (q,proposed_U,1,path) # accept
else:
return (current_position, current_U,0,None) # reject
正如我们看到这里有一个小问题——需要提供概率函数 grad_U 的导数。
不可能针对任何参数得出对数似然导数的解析表达式。但是可以尝试一种估计梯度的数值方所以我们使用tensorflow 库进行测试 ,下面是使用 tensorflow 函数实现对数似然的代码片段(代码看起来非常简单)。对于导数,它使用 GradientTape,这个函数为我们创造了奇迹,因为它是可用的,这减少了我们很多的工作。
def log_likelihood(self,params): # -log(p)
params = tf.convert_to_tensor(params, dtype=tf.float64)
noise_matrix = tf.math.multiply(tf.eye(num_rows =
self.n,dtype=tf.float64),params[0])
...
def log_likelihood_grad(self,params):
params = tf.convert_to_tensor(params, dtype=tf.float64)
with tf.GradientTape() as tape:
tape.watch(params)
y = self.log_likelihood(params)
return tape.gradient(y,params)
它是如何工作的?
首先要看下我们的数据,因为我们演示的数据是生成的,模拟方法如下:
num_points = 20
target_mean = np.zeros(num_points)
target_mean[8] = 4.
target_mean[9] = 4.
target_mean[10] = 4.
target_cov = np.eye(num_points)
for i in range(num_points-1):
target_cov[i+1,i] = target_cov[i,i+1] = 0.1
data_sample_y = 2.*np.random.multivariate_normal(target_mean,target_cov,size=60).T
noise = np.random.normal(0.,1.,num_points)
data_sample_x = np.linspace(0,100,num_points)
data_to_model = data_sample_y[:,30] + noise
它来自一个20维的多元高斯函数,除中间3个位置的均值为4外,其他位置的均值都为0,第一个非对角元素的协方差矩阵都为0.1。再把整个数据乘以2(没有其他的特殊原因只是为了好玩)。这里生成了60个样本。随机挑出一个,然后加上方差为1的随机正态噪声。如下图所示,蓝色的线是挑选的样本,蓝色的点是添加了噪声的样本,灰色的虚线是来自相同分布的剩余样本,黑线是它们的平均值。
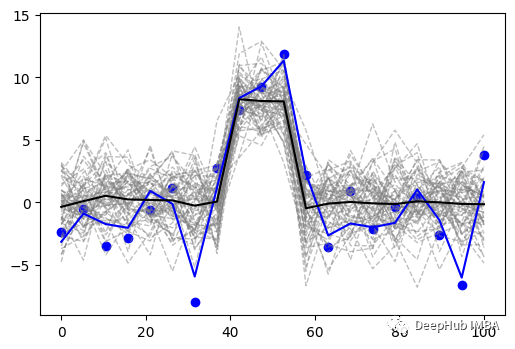
本文中用于概念验证的模拟数据中的所有样本。蓝点是用于拟合的数据,灰色虚线是相同分布的相似样本,黑线是代表这些样本的平均值信号。
灰色线条是为了给我们一个来自这个分布的数据的不确定性的视觉感官。它还可以作为我们方法的一个额外功能,将试图根据给定的一个样本来估计其不确定性。当然主要的目标是估计黑线——信号。
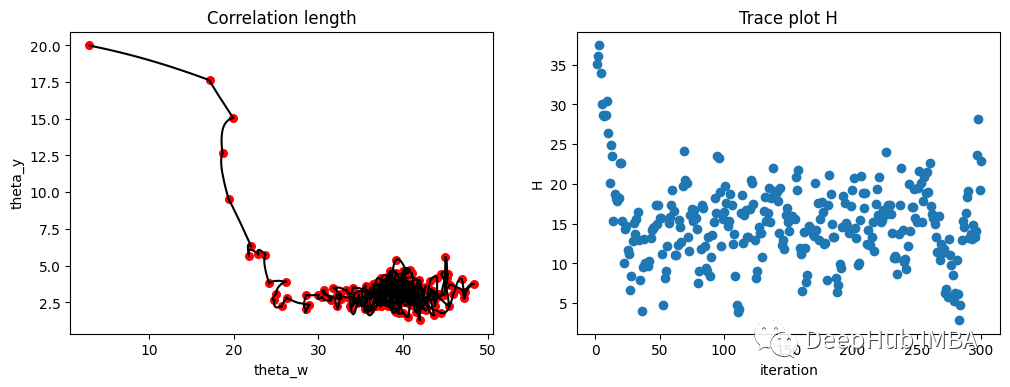
我们为一个带有噪声的样本(上图中的蓝点)添加了HMC的两层GP实现,并得出了以下结果。这里有24个参数(τ²,g,θy,θy,和20 Ws),所以不可能显示整个空间。下图只显示了其中两个参数。左边的两个θs是故意从远离正确值的地方开始的,轨迹向一个静止点移动的速度很快,当到达了可能的概率最大值,就开始围绕它盘旋。右边的图显示了总能量vs迭代次数。
使用参数的抽样后验值推断了200个样本,结果如下图所示,其中蓝线和黑线分别代表原始样本和真实数据的平均值。红线是推断样本的均值。灰色虚线是所有要与上图模拟数据进行比较的单个推断样本。
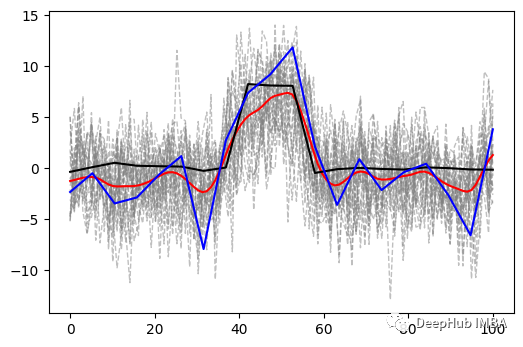
最后,这就是我们的最终结果。黑色——我们试图恢复的信号,红色——我们对它的最佳猜测,灰色虚线——我们猜测的 95% 置信区间。
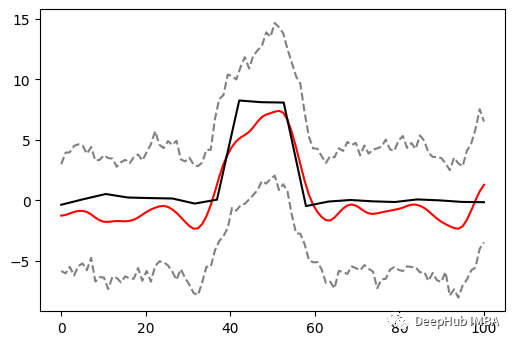
这些置信区间可能比真实的要宽一点,是因为明确检测到了中间信号的变化,我们不会被两边的摆动所迷惑。考虑到我们的样本很少(一个样本有多种变异来源,没有重复),这是一个非常强大的结果,对吧?
引用
[1] C. E. Rasmussen and C. K. I. Williams, Gaussian Processes for Machine Learning, (2006), The MIT Press ISBN 0–262–18253-X.
[2] A. Sauer, R. B. Gramacy, and D. Higdon, (2021) Active Learning for Deep Gaussian Process Surrogates, arXiv:2012.08015v2
[3] M. Betancourt, A Conceptual Introduction to Hamiltonian Monte Carlo, (2018), arXiv:1701.02434
作者:Svetlana Rakhmanova Shchegrova