ROC曲线绘制(Python)
我看谁还不会用Python画出ROC曲线!!!
数据挖掘-KNN算法+sklearn代码实现(六)
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
数据挖掘-数据的预处理(三)
准备数据:如何处理出完整、干净的数据?原始的数据本身也存在着各种各样的问题:如不够准确、格式多样、部分特征缺失、标准不统一、特殊数据、错误数据等。

10个Pandas的小技巧
pandas是数据科学家必备的数据处理库,我们今天总结了10个在实际应用中肯定会用到的技巧
“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享
“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享。
数据挖掘学习——SOM网络聚类算法+python代码实现
当一个神经元被激活时,最近的邻居节点往往比那些远离的邻居节点更兴奋。从图中可以看到,输出层的每个节点,通过D条权边与输入节点相连(即输出层的每个节点用一个D维权重Wij来表征),其中输出层中每个节点之间按照距离远近存在一定联系。不仅获胜的神经元能够得到权重更新,它的邻居也将更新它们的权重,尽管不如获
可视化分析(机器学习)
数据可视化就是通过对原始数据进行标准化、结构化的处理,把它们整理成数据表。将这些数值转换成视觉结构,通过视觉的方式把它表现出来。将视觉结构进行组合,把它转换成图形传递给用户,用户通过人机交互的方式进行反向转换,去更好地了解数据背后有什么问题和规律。如果从技术上来说,大数据可视化的实施步骤主要有四项,
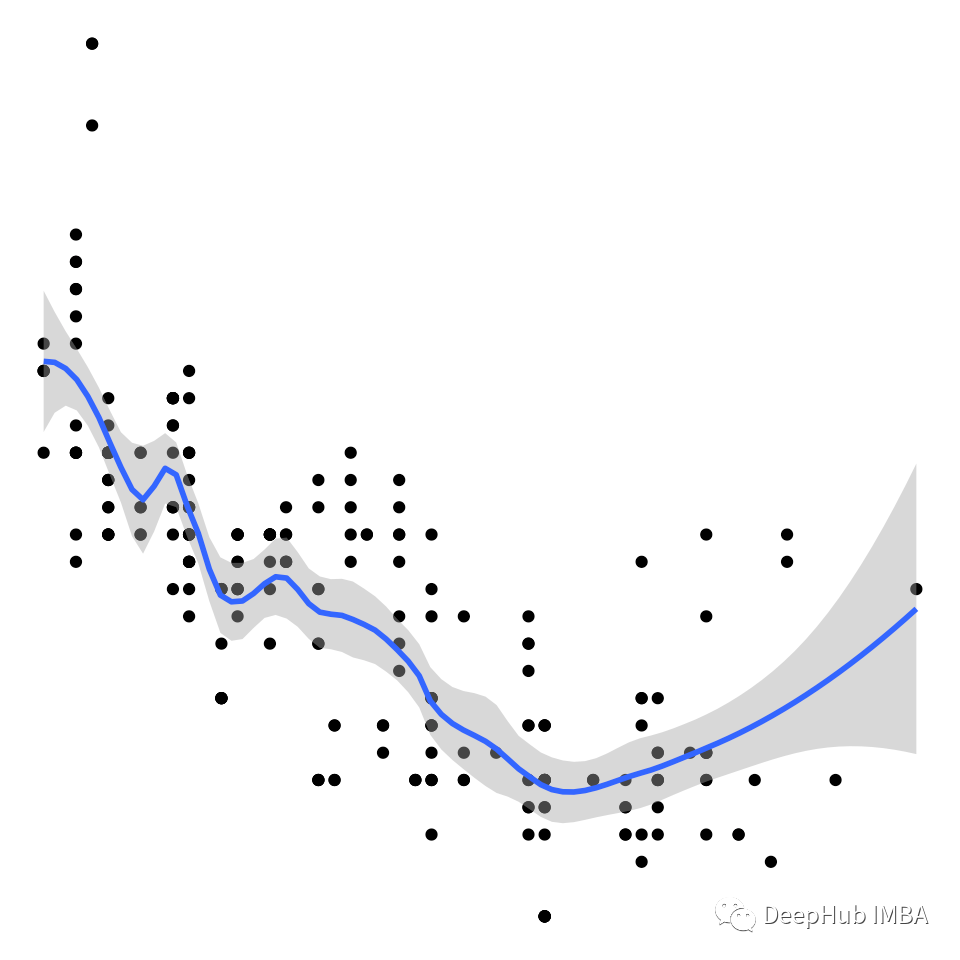
广义加性模型(GAMs)
作为回归家族的一个扩展,广义加性模型(GAMs)是最强大的模型之一,可以为任何回归问题建模!!
数据挖掘经典十大算法_K-Means算法
K-means算法的理解与代码实现
2022年全国大学生数学建模 c题思路分享 分析高钾玻璃、铅钡玻璃的分类规律 比较不同类别之间的化学成分关联关系的差异性
本人去年拿了湖南省省一,今年因为各种原因就没有参加这个比赛了。但是看到了2022年数学建模题目,我也想分享一下我的见解,希望给大家提供一些思路上的帮助,但是我也还没具体去分析,各位看官看完,有所收获就是对我最大的鼓励,不敢苟同的也就当图一乐看看吧。废话不多说直接开始分析题目。
2022年全国大学生数学建模竞赛E题目-小批量物料生产安排详解+思路+Python代码时序预测模型(三)
千呼万唤始出来啊家人们,真的是累死我了兄弟们,我昨天上了一天的班,晚上还整这个国赛敲代码敲到晚上2点才睡觉,搞得我也像是在比赛一样,麻了。不过一直写到现在也答应了很多小伙伴今天上午一定要写完E题第一问的思路和解析的,现在终于是把全部第一问的问题都梳理清楚,思路也理明白了。周预测模型其实小伙伴们不用限
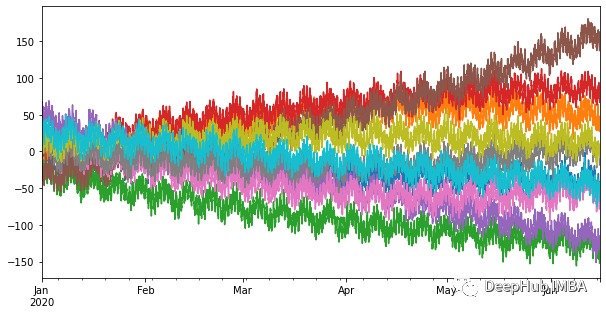
时间序列中的特征选择:在保持性能的同时加快预测速度
在这篇文章中,我们展示了特征选择在减少预测推理时间方面的有效性,同时避免了性能的显着下降。tspiral 是一个 Python 包,它提供了各种预测技术。并且它与 scikit-learn 可以完美的集成使用。
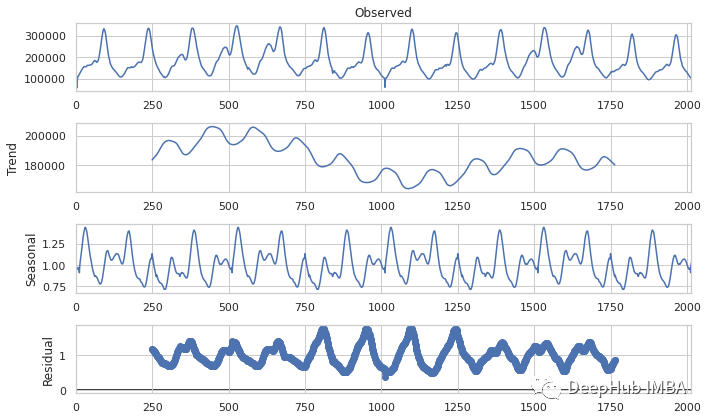
使用时间序列数据预测《Apex英雄》的玩家活跃数据
在本文中我们使用《Apex英雄》中数据分析的玩家活动时间模式,并预测其增长或下降。
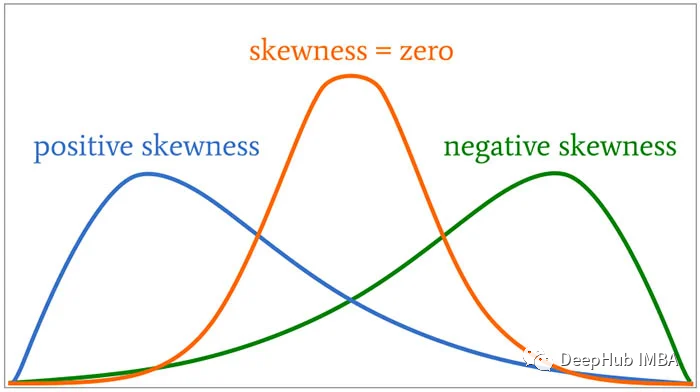
学习偏态分布的相关知识和原理的4篇论文推荐
偏态分布(skewness distribution)指频数分布的高峰位于一侧,尾部向另一侧延伸的分布。
数学建模(四):分类
数学建模(四):分类
【简单模拟添加并合并通讯录~python+】
无论是之前的按键机还是如今的智能机,通讯录都是大家最为熟知、最为经常使用的一个功能,现在我们就简单来模拟模拟用python来添加并合并通讯录叭!运行效果如下:欢迎关注微信公众号【程序人生6】,一起探讨学习哦!!!...
【机器学习算法】关联规则-3 关联规则的指标问题和关联规则的使用方法
关联规则的指标需要用那几类,关联规则如何使用。
【Python 实战基础】Pandas如何使用日期和随机数生成表格数据类型
Python 中 Pandas如何使用日期和随机数生成表格数据类型文件读写基础语法PandasPandas的Series对象numpy
【4天快速入门Python数据挖掘之第2天】Numpy——高效的运算工具
Numpy是一个开源的Python科学计算库,用于快速处理任意维度的数组Numpy支持常见的数组和矩阵操作,对于同样的数值计算任务,使用Numpy比直接使用Pyhon要简洁得多Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器Numpy提供了一个N维数组类型 ndar
【数据科学项目1】:构建你的第一个数据科学项目
从0到1构建你的第一个数据科学项目



