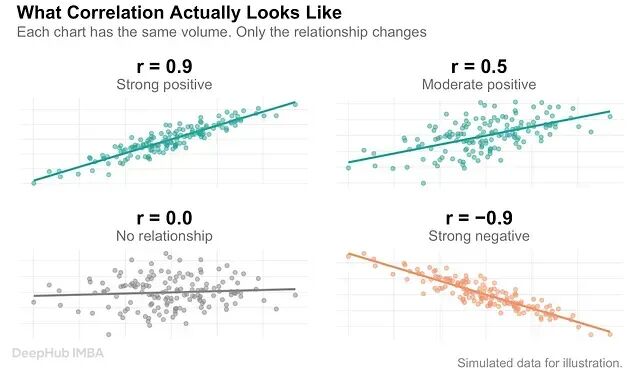
相关性与因果性:识别伪相关以提升模型在真实环境的可用性
相关性表示两个指标存在同步变动趋势,因果性则代表一件事直接促成了另一件事。两者之间有着一道需要用严谨论证来填补的鸿沟。测算相关性毫无门槛但是证明因果关系却极度困难。

告别低效代码:用对这10个Pandas方法让数据分析效率翻倍
本文将介绍 10 个在数据处理中至关重要的 Pandas 技术模式。这些模式能够显著减少调试时间,提升代码的可维护性,并构建更加清晰的数据处理流水线。
大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
本文通过实际案例演示特征工程在回归任务中的应用效果,重点分析包含数值型、分类型和时间序列特征的大规模表格数据集的处理方法。
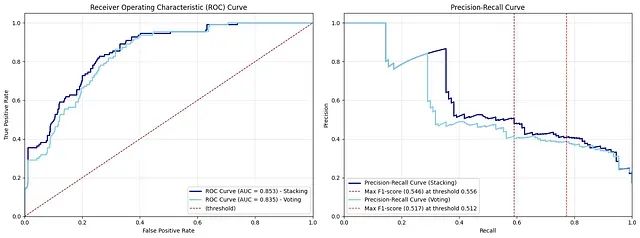
朴素贝叶斯处理混合数据类型,基于投票与堆叠集成的系统化方法理论基础与实践应用
本文深入探讨朴素贝叶斯算法的数学理论基础,并重点分析其在处理混合数据类型中的应用。
spark 3.4.4 利用Spark ML中的交叉验证、管道流实现鸢尾花分类预测案例选取最优模型
本案例详细介绍了在Spark中使用交叉验证、逻辑回归以及管道流(Pipeline)实现鸢尾花数据集最优模型选择的过程,并提供了Scala语言的示例代码。通过管道流机制,将数据预处理、特征选择和模型训练等阶段整合在一起,提高了机器学习流程的清晰度和可复用性。同时,结合交叉验证方法,提高了模型性能评估的
【大数据分析】从零开始揭秘大数据的奥秘 | 第一步全面入门
在信息爆炸的时代,数据无处不在。大数据分析作为一项改变世界的技术,正在推动商业、科技乃至社会的深刻变革。本篇文章将带你从零开始了解大数据分析,揭开其核心概念、生态系统、关键角色以及实际应用的神秘面纱。如果你对大数据感兴趣,这将是你的最佳入门指南!大数据(Big Data)并不仅仅是指数据规模庞大,而
【大选】2024年美国总统选举数据分析可视化
本项目通过2024年美国大选数据,结合Plotly和pandas快速绘制美国地图,以及相关图表直接展示相关数据
大数据与分析:数据挖掘概念及流程
数据挖掘是一个从大量数据中提取有价值信息和模式的复杂过程,它依赖于多种算法和工具。
10大核心应用场景,解锁AI检测系统的智能安全之道
思通数科AI检测系统以深度学习、计算机视觉和多模态数据融合技术为基础,通过智能化监控和实时反馈,为企业提供全面的作业安全和流程管理解决方案。思通数科AI检测系统以其强大的技术能力和灵活的适应性,为企业提供了安全、高效、智能的作业监控解决方案。无论是工业、能源还是制造领域,该系统都能助力企业实现智能化
笔记分享: 西安交通大学COMP551705数据仓库与数据挖掘——02. 关联规则挖掘
西安交通大学COMP551705数据仓库与数据挖掘
使用 DBSCAN(基于密度的聚类算法) 对二维数据进行聚类分析
使用 make_moons 方法生成一个非线性分布的二维数据集,模拟月亮形状的两个半环形分布,同时添加一定的噪声。
探索数据,洞见未来——第二届大数据与数据挖掘国际会议(BDDM 2024)诚邀参会投稿!
第二届大数据与数据挖掘国际会议(BDDM 2024)将于2024年12月13日-12月15日在中国武汉召开。
量化交易系统开发-实时行情自动化交易-3.4.3.4.期货衍生数据
衍生数据(Derived Data)是通过对原始市场数据进行计算和处理得出的数据,例如技术指标、资金流向、波动率等。这些数据有助于深入了解市场的动态、预测价格走向,并构建和优化交易策略。以下是通过 Python 编写的代码示例,利用期货公开 API(如和讯网、上海期货交易所等)获取并计算期货市场的衍
大数据-220 离线数仓 - 数仓基本概念 数仓特征 与数据库进行对比
面向主题的数据组织方式,就是在较高层次上对分析对象的数据的一个完整、一致的描述,能完整、统一地刻画各个分析对象所涉及的企业的各项数据,以及数据之间的联系。数据仓库中的数据是分析服务的,而分析需要多种广泛的不同数据源以便进行比较、鉴别,数据仓库中的数据会从多个数据源中获取,这些数据源包括多种类型数据库
图数据库| 2 、大数据的演进和数据库的进阶——从数据到大数据、快数据,再到深数据
时至今日,大数据已无处不在,所有行业都在经受大数据的洗礼。但同时我们也发现,不同于传统关系型数据库的表模型,现实世界是非常丰富、高维且相互关联的。此外,我们一旦理解了大数据的演进历程以及对数据库进阶的强需求,就会真正理解为什么“图”无处不在,以及为什么它会具有可持续的竞争优势,并最终成为新一代主流数
大数据-222 离线数仓 - 数仓 数仓模型 事实表 维度表 雪花模型 事实星座 元数据
但是它们之间也有着不同,周期快照事实记录的确定的周期的数据,而积累快照事实记录的不确定的周期的数据。事实数据通常包含大量的行,事实数据表的主要特点是包含数字数据(事实),并且这些数字信息可以汇总,以提供有关单位作为历史的数据,事实表的粒度决定了数据仓库中数据的详细程度。在大数据平台中,元数据贯穿大数
通过MongoDB Atlas 实现语义搜索与 RAG——迈向AI的搜索机制
MongoDB Atlas 的向量搜索功能为语义搜索和 RAG 提供了一个高效的数据库管理平台。在这个全新的应用场景下,Atlas 的向量检索能力支持开发者实现高效的知识检索和增强型生成应用,使其在智能客服、知识问答、个性化推荐等场景中大放异彩。结合生成式模型的 RAG 应用,MongoDB Atl
大数据-213 数据挖掘 机器学习理论 - KMeans Python 实现 距离计算函数 质心函数 聚类函数
我们需要定义一个两个长度相等的数组之间欧式距离计算函数,在不直接应用计算结果,只比较距离远近的情况下,我们可以用距离平方和代替距离进行比较,化简开平方运算,从而减少函数计算量。此外需要说明的是,涉及到距离计算的,一定要注意量纲的统一。在定义随机质心生成函数时,首先需要计算每列数值的范围,然后从该范围
数据分析工具julius ai如何使用
虽然openai也支持生成图表,但是julius ai这类专门用于数据分析的工具,可以支持更加复制一些的数据处理功能,准确率也更高。但是这些软件也是基于llm+agent的模型,一款工具也不是万能的。大多数大模型只支持python语言,支持r语言的ai数据分析工具还不多。julius ai就支持py
大数据-209 数据挖掘 机器学习理论 - 梯度下降 梯度下降算法调优
上节我们完成了如下的内容:分类技术是机器学习和数据挖掘应用中的重要组成部分,在数据学科中,约70%的问题属于分类问题。解决分类的算法也有很多,如:KNN,使距离计算来实现分类;决策树,通过构建直观易懂的树来实现分类。这里我们要展开的是Logistic回归,它是一种很常见的用来解决二元分类问题的回归方



