
目录
个人昵称:lxw-pro
个人主页:欢迎关注 我的主页
个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。
添加并合并通讯录
无论是之前的按键机还是如今的智能机,通讯录都是大家最为熟知、最为经常使用的一个功能,现在我们就简单来模拟模拟用python来添加并合并通讯录叭!
相关程序代码如下:
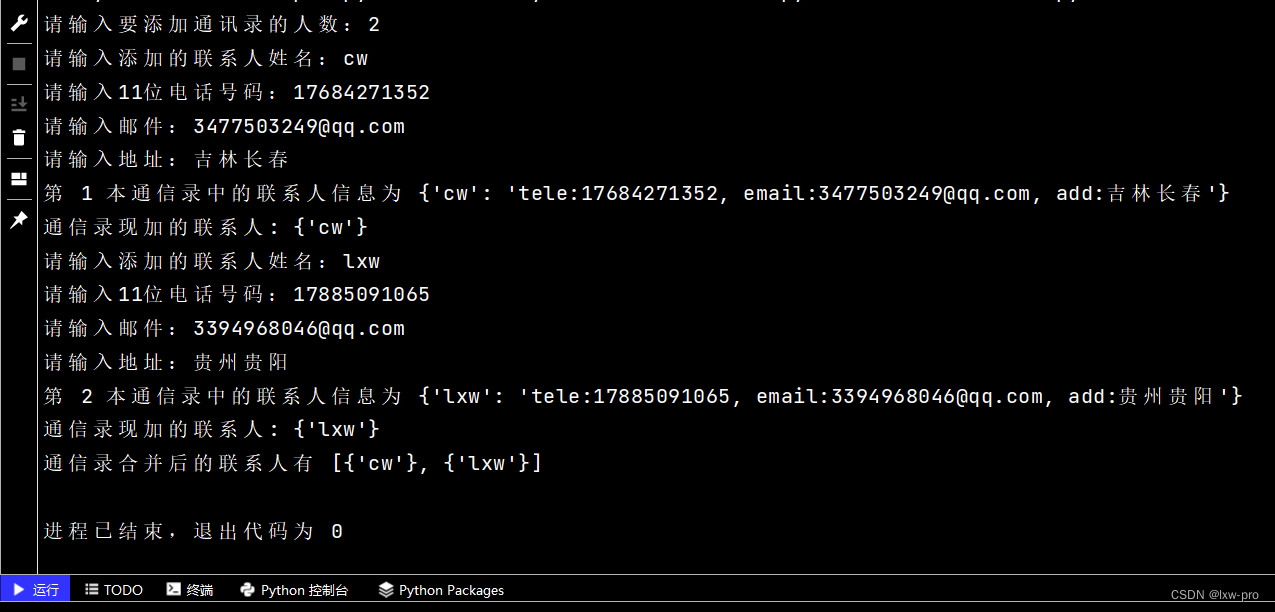
n = int(input("请输入要添加通讯录的人数:"))
a = []
for i in range(n):
con_dict = {}
name = input('请输入添加的联系人姓名:')
telephone = input('请输入11位电话号码:')
email = input('请输入邮件:')
address = input('请输入地址:')
info = f"tele:{telephone}, email:{email}, add:{address}"
con_dict[name] = info
print('第', i+1, '本通信录中的联系人信息为', con_dict)
set1 = set(con_dict)
a.append(set1)
print('通信录现加的联系人:', set1)
print('通信录合并后的联系人有', a)
运行效果如下:
————————————————————————————————————————————
Pandas 每日一练:
# -*- coding = utf-8 -*-# @Time : 2022/8/24 14:03# @Author : lxw_pro# @File : pandas-13 练习.py# @Software : PyCharmimport pandas as pd
import numpy as np
81、导入并查看pandas与numpy版本
print("此时电脑所拥有pandas的版本号为:", pd.__version__)print("此时电脑所拥有numpy的版本号为:", np.__version__)
运行结果如下:
此时电脑所拥有pandas的版本号为: 1.3.5
此时电脑所拥有numpy的版本号为: 1.21.4
82、从Numpy数组创建DataFrame
tmp1 = np.random.randint(1,100,10)
df1 = pd.DataFrame(tmp1)print(df1)
运行结果如下:
0082135240335484583627739889913
83、从Numpy数组创建DataFrame
tmp2 = np.arange(0,100,5)
df2 = pd.DataFrame(tmp2)print(df2)
运行结果如下:
000152103154205256307358409451050115512601365147015751680178518901995
84、从Numpy数组创建DataFrame
tmp3 = np.random.normal(0,1,20)
df3 = pd.DataFrame(tmp3)print(df3)
运行结果如下:
001.1915701-1.3936872-1.8546333-1.35740840.1068855-0.80773362.42314470.61846780.3319699-1.11327010-0.431672110.333612120.39020713-0.30511914-1.105575151.005282161.28534717-1.111543181.62886719-0.833661
85、将df1、df2、df3按照行合并为新DataFrame
df = pd.concat([df1, df2, df3], axis=0, ignore_index=True)print(df)
运行结果如下:
0082.000000135.000000240.000000335.000000484.000000583.000000627.000000739.000000889.000000913.000000100.000000115.0000001210.0000001315.0000001420.0000001525.0000001630.0000001735.0000001840.0000001945.0000002050.0000002155.0000002260.0000002365.0000002470.0000002575.0000002680.0000002785.0000002890.0000002995.000000301.19157031-1.39368732-1.85463333-1.357408340.10688535-0.807733362.423144370.618467380.33196939-1.11327040-0.431672410.333612420.39020743-0.30511944-1.105575451.005282461.28534747-1.111543481.62886749-0.833661
86、将df1、df2、df3按照列合并为新DataFrame
df = pd.concat([df1, df2, df3], axis=1, ignore_index=True)print(df)
运行结果如下:
012082.001.191570135.05-1.393687240.010-1.854633335.015-1.357408484.0200.106885583.025-0.807733627.0302.423144739.0350.618467889.0400.331969913.045-1.11327010 NaN 50-0.43167211 NaN 550.33361212 NaN 600.39020713 NaN 65-0.30511914 NaN 70-1.10557515 NaN 751.00528216 NaN 801.28534717 NaN 85-1.11154318 NaN 901.62886719 NaN 95-0.833661
87、查找df所有数据的最小值、25%分位数、中位数、75%分位数、最大值
ms = df.describe()print(ms)
运行结果如下:
012
count 10.00000020.00000020.000000
mean 52.70000047.500000-0.049948
std 28.45288529.5803991.166953min13.0000000.000000-1.85463325%35.00000023.750000-1.10706750%39.50000047.500000-0.09911775%82.75000071.2500000.715171max89.00000095.0000002.423144
88、修改列名为col1、col2、col3
df.columns =['col1','col2','col3']print(df)
运行结果如下:
col1 col2 col3
082.001.191570135.05-1.393687240.010-1.854633335.015-1.357408484.0200.106885583.025-0.807733627.0302.423144739.0350.618467889.0400.331969913.045-1.11327010 NaN 50-0.43167211 NaN 550.33361212 NaN 600.39020713 NaN 65-0.30511914 NaN 70-1.10557515 NaN 751.00528216 NaN 801.28534717 NaN 85-1.11154318 NaN 901.62886719 NaN 95-0.833661
89、提取第一列中不在第二列出现的数字
print(df['col1'][df['col1'].isin(df['col2'])])
运行结果如下:
135.0240.0335.0
Name: col1, dtype: float64
90、提取第一列和第二列出现频率最高的三个数字
tmp = df['col1'].append(df['col2'])print(tmp.value_counts().index[:3])
运行结果如下:
Float64Index([35.0,40.0,82.0], dtype='float64')
每日一言:
你必须按所想去生活,否则你只能按生活去想!!!
持续更新中…
点赞,你的认可是我创作的
动力!
收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富!
关注,你的喜欢是我长久的坚持!

欢迎关注微信公众号【程序人生6】,一起探讨学习哦!!!
本文转载自: https://blog.csdn.net/m0_66318554/article/details/125750652
版权归原作者 lxw-pro 所有, 如有侵权,请联系我们删除。
版权归原作者 lxw-pro 所有, 如有侵权,请联系我们删除。