AI时代来临,如何把握住文档处理及数据分析的机遇
在3月18日,由中国图象图形协会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会联合承办的“CSIG图像图形企业行”活动将正式举办,特邀来自上海交大、厦门大学、复旦、中科大的顶尖学府的学者与合合信息技术团队一道,以直播的形式分享文档处理实践经验及NLP发展趋势,探讨ChatGPT与文
【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)
构建用水事件行为识别模型1、洗浴识别模型根据建模样本数据和用户记录的包含用水的用途、用水开始时间、用水结束时间等属性的用水日志,建立BP神经网络模型识别洗浴事件。
Stata:中介效应理论及sgmediation命令做sobel检验
中介作用的检验模型可以用以下路径图来描述:方程(1)的系数c 为自变量X对因变量Y的总效应;方程(2)的系数a为自变量X对中介变量M的效应;方程(3)的系数b是在控制了自变量X的影响后,中介变量M对因变量Y的效应;方程(3)的系数c′是在控制了中介变量M 的影响后,自变量X对因变量Y的直接效应;系数
脑电信号分类问题的数据预处理方法
脑电信号分类问题的数据预处理方法
人工智能导论期末复习重点
绪论人工智能诞生于1956,达特茅斯会议,与空间技术和原子能技术统称为20世纪三大科学技术成就,智能是知识和智力的总和,知识是一切智能行为的基础,智力是获取知识并应用知识求解问题的能力。麦卡锡----人工智能之父。1969年成立国际人工智能会议。1970年创立人工智能杂志,1957年提出感知机模型智
盘点5种最频繁使用的检测异常值的方法(附Python代码)
在统计学中,异常值是指不属于某一特定群体的数据点。它是一个与其他数值大不相同的异常观测值,与良好构成的数据组相背离。例如,你可以清楚地看到这个列表里的异常值:[20, 24, 22, 19, 29, 18, 4300, 30, 18].当观测值仅仅是一堆数字并且是一维时,很容易识别出异常值。但是,当
奇异值分解(SVD)和np.linalg.svd()函数用法
奇异值分解是一种十分重要但又难以理解的矩阵处理技术,在机器学习中是最重要的分解没有之一的存在。那么,奇异值分解到底是在干什么呢?
数据挖掘(2.2)--数据预处理
描述数据的中心趋势、数据发散、数据清洗
一文速学-GBDT模型算法原理以及实现+Python项目实战
上篇文章内容已经将Adaboost模型算法原理以及实现详细讲述实践了一遍,但是只是将了Adaboost模型分类功能,还有回归模型没有展示,下一篇我将展示如何使用Adaboost模型进行回归算法训练。首先还是先回到梯度提升决策树GBDT算法模型上面来,GBDT模型衍生的模型在其他论文研究以及数学建模比
【数据挖掘实战】——应用系统负载分析与容量预测(ARIMA模型)
系统负载分析的传统方法:通过监控采集到的性能数据以及所发出的告警事件,人为进行判断系统的负载情况。实际业务中,监控系统会每天定时对磁盘的信息进行收集,但是磁盘容量属性一般情况下都是一个定值(不考虑中途扩容的情况),因此磁盘原始数据中会存在磁盘容量的重复数据。在不考虑人为因素的影响时,存储空间随时间变
数据挖掘(2.3)--数据预处理
三、数据集成和转换1.数据集成2.数据冗余性2.1 皮尔森相关系数2.2卡方检验3.数据转换
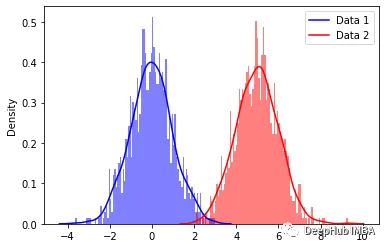
高斯混合模型 GMM 的详细解释
高斯混合模型(后面本文中将使用他的缩写 GMM)听起来很复杂,其实他的工作原理和 KMeans 非常相似,你甚至可以认为它是 KMeans 的概率版本。 这种概率特征使 GMM 可以应用于 KMeans 无法解决的许多复杂问题。
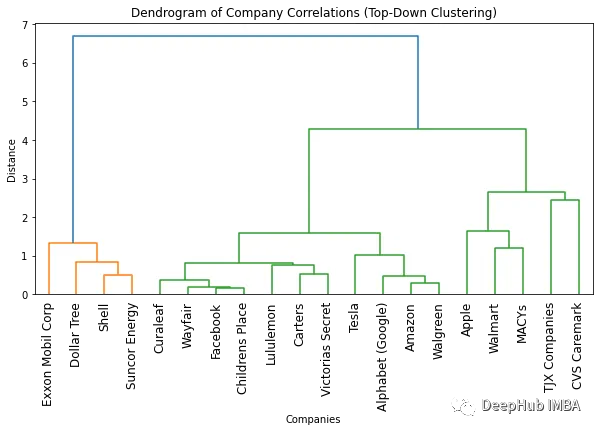
使用树状图可视化聚类
这篇文章中,我们介绍如何使用树状图(Dendrograms)对我们的聚类结果进行可视化。
10种基于MATLAB的方程组求解方法
直接发和迭代法,都有一定的适用范围,对应复杂的方程组,往往没法收敛,启发式算法,比如粒子群,可以自适应的对方程组的解进行求解,对复杂的方程组的求解精度一般更高,代码通用性更强,PSO是由Kennedy和Eberhart共同提出,最初用于模拟社会行为,作为鸟群或鱼群中有机体运动的形式化表示。
时间序列模型-ARIMA
主要介绍了ARIMA模型的基本概念和建模流程。
【机器学习之模型融合】Stacking堆叠法
Stacking堆叠法原理透析与应用

处理缺失值的三个层级的方法总结
缺失值是现实数据集中的常见问题,处理缺失值是数据预处理的关键步骤。本文将展示如何使用三种不同级别的方法处理这些缺失值
机器学习期末复习题
机器学习期末复习资料,答案已标注。
聚类算法(下):10个聚类算法的评价指标
上篇文章我们已经介绍了一些常见的聚类算法,下面我们将要介绍评估聚类算法的指标



